看了这个Hadoop和大数据你就懂了一半了
1、多台服务器是怎么通讯的,网络间的配置
这里以设置虚拟机为例,虚拟机需要设置两个网卡,第一个网卡设置为“NAT网卡”-enp0s3(Ubuntu16中的命名),主要是通过主机连接到外部互联网进行上网;另一个为“仅主机适配器(网卡)”-enp0s8,用于创建内部网络,通过该网络实现同一网段下不同的机器进行相互登录通讯等操作。(其中第二个网卡的地址需要自己手动设置)

然后在master主机上修改hosts文件,输入对应的没一探主机名和对应的IP地址,最后设置 slave文件,添加对应的主机名便可,会根据hosts文件中对应的IP地址进行查找连接,这样就可以通过ssh进行登录。
(SSH登录原理:将该主机的公匙文件添加到另一台主机的授权列表下(中间还会有一个相互验证的过程))
2、RPC远程过程调用,可以实现不同主机下进行类方法的直接访问
在Hadoop分布式系统中常会用到RPC,在分布式系统中,因为是不同的主机,我的一台主机如果想调用另一个类的实现方法怎么办?而另一个类的实现在另一台主机上,这就是简单的RPC调用,其底层机制是通过网络通讯完成的。

3、Yarn 资源框架
Hadoop主要由三部分组成:HDFS文件系统,YARN资源调度框架,MR处理逻辑。
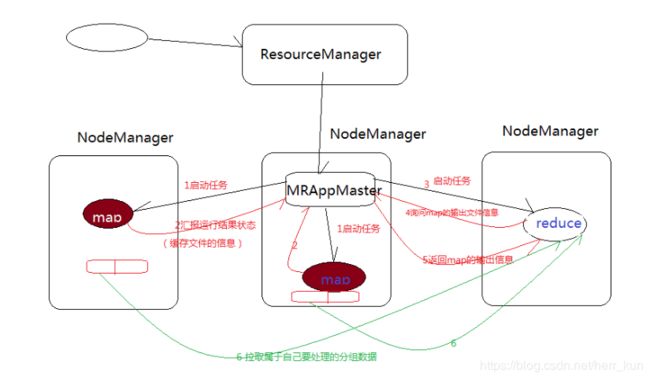
其中yarn资源框架主要是进行资源的调度的处理,下面来看一个job 的提交过程,你就可以看到yarn到底是做什么用的

可以看出来当你把job提交了之后还是有很多后续工作要做的,比如我分配我的资源,分多少内存运行job,多个job怎么处理,开几个map进程,开几个reduce进程等等,这些都是要做的,yarn里面分为两种管理者:resource manager , node manager,从上图可以看到两者的分工。
4、shuffle机制(这里的shuffle指的是mapreduce的处理流程)
注:因为shuffle涉及到向磁盘写入数据,而spark的数据处理一般都是在内存中的,这是由于Hadoop的一个重要的点。
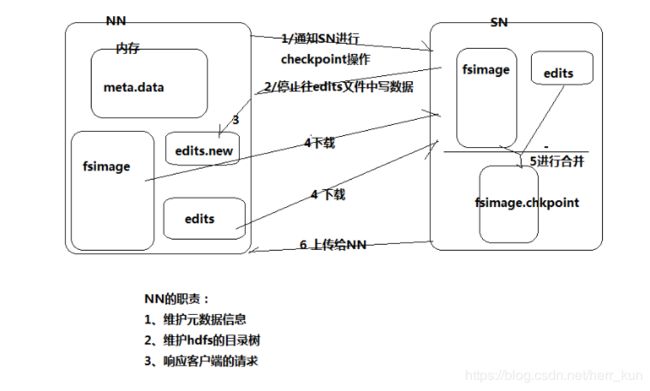
5、secondery namenode的实现
secondery namenode主要是辅助namenode进行元数据的存储 ,并且还能加强namenode的健壮性,因为一旦我们整个分布式系统运行了很久,我们知道namenode不存储数据,只是存储一些元数据,记录了每个文件的地址和block信息等,那么namenode就会有很多的元数据,会很大怎么办,这时候 secondery namenode就来了,它通过合并namenode的edits log and fsimage文件生成检查点文件,然后在重新传给namenode,这样一来namenode的edits log文件就会很小,并且它的fsimage都是更新过的(这里的 edits.new是SN合并文件时(要暂停向edits log写入),NN暂时替代edits log文件的一个临时文件)。
参考:https://blog.csdn.net/xh16319/article/details/31375197
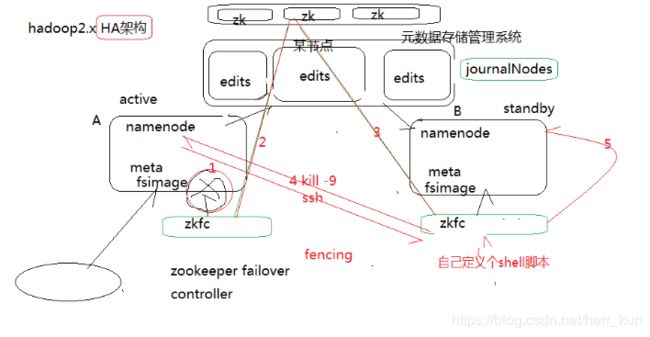
6、HA的实现机制,如何一个active,一个standby
HA就是高可用的意思,为什么会有HA,想象一下如果我们仅有的一个namenode挂掉了,怎么办?那真个系统可能就挂掉了,因为没了元数据就无法进行数据的读取写入。所以这时候很简单的一个想法就是至少两个机器都是namenode,一个为active活跃状态,一个为standby待命状态(随时可以顶上)。而HA将这个思想更加发扬光大,它将两个个甚至多个机器组成一个联邦,里面只有一台为active状态,并且还搞了多个联邦,防止万一挂了一整个联邦怎么办。
实现机制:这里讲edits文件拿了出来,实现共享(底层zookeeper实现)),防止一个机器挂掉了之后找不到最新的元数据。
7、zookeeper 是干嘛的
zookeeper主要是实现少量数据的存储,实现配置信息的共享。说一个例子就明白了:我的多台服务器每一个都有配置文件,当我想改变这个集群的时候就要修改配置文件,那么如果我有上千台服务器,还要一个个修改么?所以这时候zookeeper(动物园管理者)就出现了,管理Apache的各个小动物(Hadoop就是大象的标志)。
8、Hive-数据仓库
Hive本质是什么? 他就是mr对对数据处理的封装,也就是说将常用的数据处理方法比如select操作封装为MapReduce程序,为什么这么做呢?1、Hive是针对大数据处理开发的,所以肯定是基于分布式开发的,所以要用MapReduce处理框架来实现,速度更快。2、自己写比较麻烦,不如把常用的操作封装好。
底层实现:
Hive语句(select ID,name.......)-->编译(对Hive语句进行解析)-->调用相应的jar包(比如调用封装好的select的jar包)-->执行器(调用mr框架进行运次处理)-->处理存储在hdfs中的数据
什么是数据仓库?为什么不是数据库
数据仓库更在意的是对数据的处理,一般来说里面的数据一半不会发生改变,不会进行数据的写入等操作,都是一些“成熟”的数据,适合做数据分析;而数据库在意的是数据,可以进行数据的写入,清洗等操作
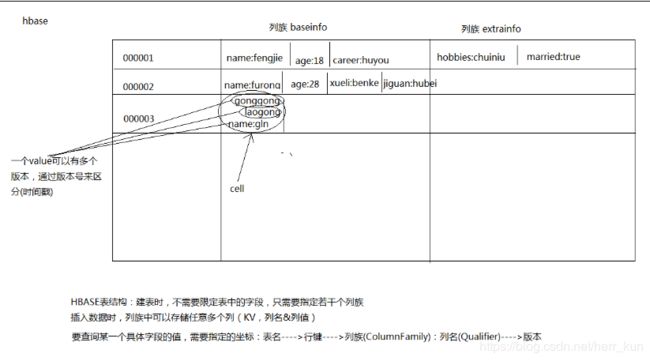
9、HBase是什么
HBase可以说是一个分布式的数据库,官方文档上说是一个基于分布式的大数据存储,简单的额来说就是在HDFS文件系统上搭建的一个结构化的文件查询系统,他属于nosql的范围,不支持向mysql一样的表间操作比如join等,一般只用来进行数据的快速查询查看(因为HDFS无法进行快速特定的查询,HBase在HDFS之上进行结构化优化,所以查询更快)。
HBase不满足数据库的三大范式,数据是以KV形式存储在表中的,具体是这样的,添加额外的特征属性就需要添加另外一个列族来实现。