基于万兆40G以太网的DSP+FPGA专用加速计算平台
1 加速计算平台综述
基于FPGA的加速计算目前是FPGA厂家Xilinx,Intel大力发展的产品。以FPGA的PCIe卡+X86模式是目前主流的加速计算方式,如图结构:
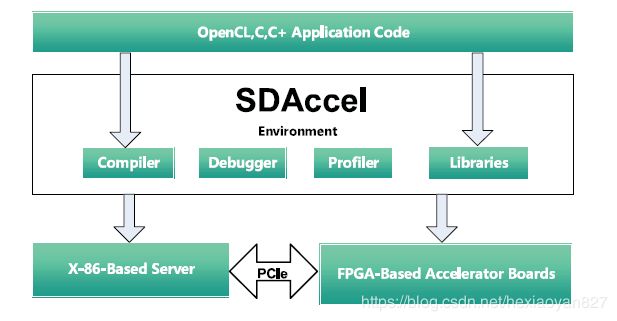
但是该方案导致的问题表现如下:
1 需要通用万兆网卡把输入导入到X86 CPU内存,然后通过PCIe转发数据到FPGA,FPGA加速计算的结果再转给X86,数据的延迟大大增加。
2 X86 需要作为中间桥梁,需要消耗X86的计算资源。
3 由于单片FPGA资源有限,有些复杂的加速计算,需要多片FPGA串联或者并联完成算法,该架构没有办法支持。
4 金手指插卡模式,抗震性能比较差,机箱内部的风道不合理,导致产品在苛刻环境下不能使用。
基于DSP+FPGA的加速计算方案在特种应用场合之下,体现了其巨大优势。表现在:
1 光纤10G/40G 以太网直接接入数据,FPGA实现低延迟计算,DSP通过RapidIO与FPGA互联,延迟很低,实时传输,8核1GHz主频CPU实现快速浮点计算。
2 DSP代替X86CPU工作,嵌入式裸跑纯C编程,代码简练,指令效率高。
3 整板构成1U机箱,体积小,功耗低,性价比高。
基于DSP+FPGA的加速计算方案,可用于卫星数据地面站大数据计算,气象天文台的数据计算,高能物理大数据计算。特别适合非互联网行业的封闭式局域网,国家专业应用,行业内部大数据计算。
硬件方案1:基于双XCKU060+双C6678 的双FMC接口40G光纤传输加速计算卡
- 板卡概述
板卡采用基于双FPGA+双DSP的信号采集综合处理硬件平台,板卡大小360mmx217mm。板卡两片FPGA提供两个FMC接口,4路QSFP+接口;每片FPGA挂接2簇32-bit DDR4 SDRAM,总容量2GB;两片FPGA之间通过GTH x8以及若干LVDS信号互联。每片FPGA通过RapidIO总线连接一片TMS320C6678型号8核DSP;每片DSP芯片外挂1GB的DDR3 SDRAM,Flash和2路千兆网接口;两片DSP之间通过HyperLink进行高速互联。
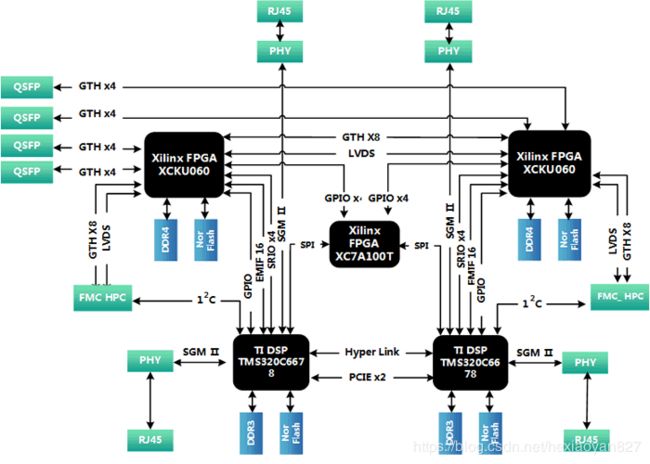
二、处理板技术指标
• 板载两片TI公司8核心DSP TMS320C6678,两片Xilinx公司UltraScale架构Kintex FPGA芯片KU060;
• 搭载一片Artix用于整板时钟、电源、复位等控制;
• 两片DSP之间的HyperLink支持50 Gbaud速率,PCIe支持x1/x2模式,速率可达5Gbaud/Lane;
• DSP与FPGA之间通过SRIO互联,满足SRIO 2.1标准,支持x1/x2/x4模式,速率可达5Gbps/Lane;
• 具备4路QSFP接口,支持40Gbps高速传输;
• 每路QSFP支持1转4模式,转换后支持大16.3Gbps/Lane传输速率;
• 具备两个FMC子卡接口,每个子卡接口通过GTH x8以及LVDS与一片Xilinx FPGA XCKU060相连;GTH x8可配置为8个GTH x1或4个GTH x2或2个GTH x4,最大速率可达16.3Gbps/Lane;
• 具备4路千兆网口,每路网口均可自适应10Mbps/100Mbps/1000Mbps通信速率;
• 具备I2C接口,实现系统功耗、状态管理与监测;
三、软件系统
四、物理特性:
• 工作温度:商业级 0℃~+55℃,工业级-40℃~+85℃;
• 工作湿度:10%~80%;
五、供电要求:
• 直流电源供电,整板大功耗120W;
• 供电电压:12V/10A;
• 电源纹波:≤10%;
硬件方案2:基于单XCVU9P+双C6678 的双FMC接口40G光纤传输加速计算卡
- 板卡概述
基于FPGA+DSP架构的信号处理开发平台主要包括:一片Xilinx FPGA XCVU9P,两片 TI 多核DSP TMS320C6678及其控制管理芯片CFPGA.设计芯片满足工业级要求。
FPGA VU9P 需要外接4路QSFP+(100Gbps)及其两个FMC HPC接口。DSP需要外接两路千兆以太网。如下图所示:
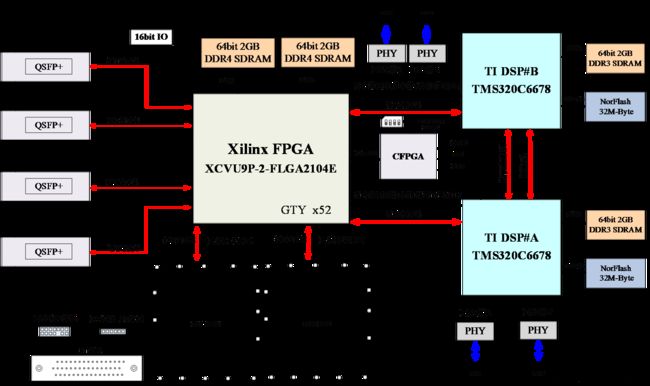
图 1:原理框图
- 主要功能及性能指标
- FPGA处理器采用Xilinx Virtex UltralSCALE+ 系列芯片 XCVU9P。
- FPGA 外挂2组FMC HPC 连接器。
- FPGA 外挂两簇DDR4
- FPGA 每簇DDR4位宽64bit,容量2GB,数据速率2400Mb/s。
- FPGA 连接4路QSPF+,每路QSFP+数据速率100Gb/s。
- FPGA 预留GPIO ,TTL3V3电平。
- 光模块的参考时钟可以切换至外部时钟源,频率245.76MHz。
- DSP处理器采用两颗TI 8核处理器TMS320C6678。
- 每片DSP 外挂一组64bit DDR3颗粒,总容量2GB,数据速率1333Mb/s。
- DSP 采用EMIF16 NorFlash加载模式,NorFlash容量32MB。
- 每片DSP 外挂两路千兆以太网1000BASE-T,分别放置在板卡的上边沿和下边沿。
- DSP 和FPGA 之间通过SRIO x4互联@5Gbps。
- DSP间通过Hyperlink x4 ,PCIe x2互联。
- DSP,FPGA,CFPGA 仿真器接口连接到J30J-66ZKWP7-J连接器,且板卡预留仿真器接口。
- CFPGA 外接拨码开关控制DSP boot模式的切换。
- 需考虑DSP/FPGA的远程更新程序的功能。
- 板卡单电源输入12v。
- 板卡配套散热和加固设计。
- 板卡结构
板卡结构为非标结构,长x宽:360mm x 217mm,光口的位置在板卡的左侧,电源供电在板卡的上边沿,具体板卡形态如下图所示:
图 2:板卡外形
- FPGA资源介绍
