深度学习(二十五)基于Mutil-Scale CNN的图片语义分割、法向量估计
基于Mutil-Scale CNN的图片语义分割、法向量估计
原文地址:http://blog.csdn.net/hjimce/article/details/50443995
作者:hjimce
一、相关理论
2016年的第一篇博文,新的奋斗征程。本篇博文主要讲解2015年ICCV的一篇paper:《Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture》,文献的主页:http://www.cs.nyu.edu/~deigen/dnl/。一开始看到这篇文献的名字,有点被吓到了,我以为作者要采用mutil-task多任务特征学习的方法,用于估计单幅图像的深度、法向量、语义分割三个任务。还以为paper即将采用跟文献《Facial Landmark Detection by Deep Multi-task Learning》一样的思想,进行提高精度,最后仔细通读全文才知道,其实这三个任务是独立的,不是传说中的“多任务特征学习”,终于松了一口气(因为之前看《机器学习及其应用2015》这本书的第一章的时候,讲到了“鲁邦多任务特征学习”,觉得好难,看不懂,所以就对多任务特征学习有点害怕)。这篇paper的思想其实很简单,说白了就是在文献《Depth map prediction from a single image using a multi-scale deep network》的基础上,改一改,精度稍微提高了一点点,就这样。
基于多尺度的语义分割在FCN网络中,早有耳闻,所以如果学过paper:《Fully Convolutional Networks for Semantic Segmentation 》 ,在学习这篇文献的网络架构时会比较轻松。对于三维法向量估计,这个需要懂一点点三维图像学的知识,一般只有搞到三维图像的人才会去在意这篇paper的法向量估计算法,不然二维视觉很少用到,因为我以前曾经搞过三维,所以对于三维的一些知识比较了解。还有另外一个是深度估计,深度估计基本上没变,都是继承了文献《Depth map prediction from a single image using a multi-scale deep network》的方法。所以总得来说我感觉这篇文献的创新点不是很明显,新的知识点很少,我们学起来也会比较轻松。
学习建议:要学习这篇paper,我个人感觉还是先要学《Depth map prediction from a single image using a multi-scale deep network》,学了这篇文献,那么接着就非常容易了。
二、网络架构
网格结构方面与文献《Depth map prediction from a single image using a multi-scale deep network》基本相似,可以说是在这篇paper的基础上做的修改,区别在于:
(1)采用了更深层的网络;
(2)增加了第三个尺度的网络,使得我们的输出是更高分辨率的图片(之前的paper输出大小是55*77,现在最后网络的输出大小是109*147);
(3)与之前的思路有点不同,之前采用的方式是,先训练scale1,训练完成后,以scale 1的输出作为scale 2的输入。现在所采用的方式是:scale 1和scale 2联合训练,最后固定这两个尺度CNN,在训练scale 3。
我们先大体看一下网络的总体架构:
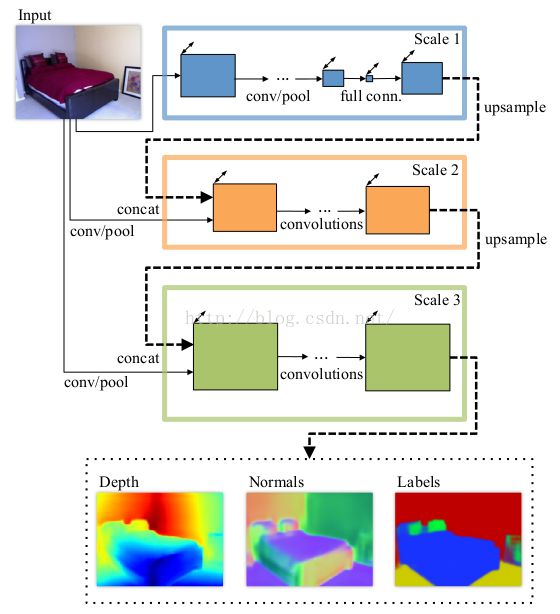
网络分成三个尺度的CNN模型,scale 1的输入是原始图片;scale 2 的输入是原始图片和scale 1的输出;同样,scale 3 的输入是scale 2的输出和原始图片。可能网络的结构,看起来有点庞大,其实不然,这个相比于前面的博文《基于DCNN的人脸特征点定位》简单多了。
1、Scale 1 网络架构
网络的输入:原始图片,输入图片大小为 三通道彩色图片;
网络的输出:19*14大小的图片;
下面是网络第一个尺度的相关参数,这个和文献《Depth map prediction from a single image using a multi-scale deep network》一样,基本上是Alexnet。

本尺度的CNN不在细讲,如果不知道怎么架构,可以好好阅读文献:《Depth map prediction from a single image using a multi-scale deep network》。
2、Scale 2 网络架构
(1)第一层网络
输入:原始图片304*228(输入320*240后,训练的时候,采用random crop到304*208),经过卷积后,得到74*55大小的图片。相关参数如下:
[conv_s2_1]
type = conv
load_key = fine_2
filter_shape = (96,3,9,9)
stride = 2
init_w = lambda shp: 0.001*np.random.randn(*shp)
init_b = 0.0
conv_mode = valid
weight_decay_w = 0.0001
learning_rate_scale = 0.001
[pool_s2_1]
type = maxpool
poolsize = (3,3)
poolstride = (2,2)也就是特征图个数为96,卷积的stride大小为2。池化采用重叠池化,池化stride大小为2。这样卷积步的stride=2,池化步的stride=2,图片的大小就缩小为原来的1/4(具体计算不再详解,因为这些计算是非常基础的东西了)。
(2)第二层网络。输入:除了第一层得到的特征图之外,还有scale 1的输出(把scale1的输出图片由19*14,放大4倍,然后进行边界处理,得到74*55的图片)。
3、Scale 3 网络结构
个人感觉多加了这个尺度的网络,仅仅只是为了获得更高分辨率的输出。
(1)第一层网络。与scale 2一样,第一层网络的输入是原始图片,然后进行卷积池化,因为我们scale 3要得到更大分辨率的结果,于是作者就把池化的stride选择为1,具体代码如下:
[conv_s3_1]
type = conv
load_key = fine_3
filter_shape = (64,3,9,9)
stride = 2
init_w = lambda shp: 0.001*np.random.randn(*shp)
init_b = 0.0
conv_mode = valid
weight_decay_w = 0.0001
learning_rate_scale = 0.001
[pool_s3_1]
type = maxpool
poolsize = (3,3)
poolstride = (1,1)这样经过这一层的操作,我们可以得到147*109的图片。
(2)第二层网络。输入第一层的特征图,还有scale 2的输出图,在进行卷积池化。相关参数如下:
[depths_conv_s3_2]
type = conv
load_key = fine_3
filter_shape = (64,64,5,5)
init_w = lambda shp: 0.01*np.random.randn(*shp)
init_b = 0.0
conv_mode = same
weight_decay_w = 0.0001
learning_rate_scale = 0.01(3)第三层网络。后面都差不多,大同小异,具体就不在详解了,看一下网络的相关配置参数:
[depths_conv_s3_3]
type = conv
load_key = fine_3
filter_shape = (64,64,5,5)
init_w = lambda shp: 0.01*np.random.randn(*shp)
init_b = 0.0
conv_mode = same
weight_decay_w = 0.0001
learning_rate_scale = 0.01(4)第四层网络
[depths_conv_s3_4]
type = conv
load_key = fine_3
filter_shape = (64,1,5,5)
transpose = True
init_w = lambda shp: 0.01*np.random.randn(*shp)
init_b = 0.0
conv_mode = same
weight_decay_w = 0.0001
learning_rate_scale = 0.001四、损失函数构建
我觉得文献的提出算法,如何构造损失函数也是一大创新点,所以我们还是要好好阅读对于深度、法向量、语义分割这些损失函数是怎么构建的。
(1)深度估计损失函数
这个与之前的那篇paper的构造方法相同,也是采用作者所提出的缩放不变损失函数,同时后面又加了一项elementwise L2:
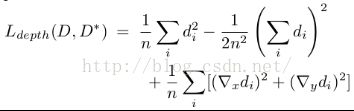
其中D和D*分别表示网络深度预测值、实际的深度值。然后d=D-D*。
(2)法矢估计损失函数
因为法向量是三维的,因此我们每层scale的输出,就不应该是一个单通道图片了,而应该改为3通道,用于分别预测一个三维向量的(x,y,z)值。同时我们要知道法向量指的是长度为1的归一化向量,因此在输出三维V向量后,我们还需要把它归一化,然后接着才能定义计算损失函数:
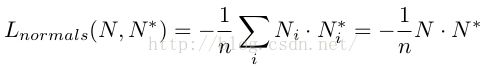
因为预测值N和真实值N*向量的模长都为1,所以其实上面的损失函数说白了就是以两个向量的角度差,作为距离度量。
真实的法向量的获取方法:可能是没有训练数据的原因,所以文献法向量训练数据的获取方法,是通过每个像素点的深度值,获得三维空间中每个像素点的位置,也就是相当于点云。然后采用最小二乘平面拟合,拟合出每个点邻域范围内平面,以平面的法向量作为每个像素点的法矢(这个因为我之前搞过三维的重建、点云处理,所以对于三维点云法向量的求取会比较熟悉,如果没有接触过三维图形学的,可以跳过不看,或者可以学一学我的博客: http://blog.csdn.net/hjimce/article/category/5570255 关于三维图形学的知识,可以直接看点云重建)
(3)语义分割损失函数
因为语义分割,就相当于给每个像素点做分类,也就是相当于一个多分类问题,所以自然而然采用softmax,损失函数采用交叉熵:
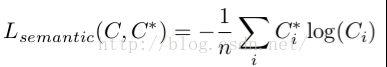
其中:
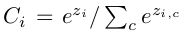
这个是softmax的相关知识了,不熟悉的赶紧补一下。不然后面遇到CNN图片分类,就要抓狂了,softmax是基础知识。
五、网络训练
(1)训练流程
训练方法采用的都是随机梯度下降法,首先我们训练把scale 1和scale 2 联合起来训练,也就是说我们在训练scale 2的时候,scale1的参数也是要更新的,这个与另外一篇paper:《Depth Map Prediction from a Single Image using a Multi-Scale Deep Network》的训练方法不同。然后scale 3的训练和前面两个尺度的训练是分开的,我们先训练完了scale 1、scale 2,训练完毕后,固定这两个尺度的参数,然后继续训练scale 3(换一种说法就是训练scale 3的时候,scale 1\2的参数是不更新的)。
(2)训练参数
具体的训练参数,还是参考作者给的代码中的conf网络配置文件,里面可以看到每层的学习率,以及其它的一些相关参数。参数初始化:除了scale 1前面几层卷积层是用了Alexnet训练好的参数,作为初始值。其它的全部采用随机初始化的方法。Batch size大小选择32。
参考文献:
1、《Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture》
2、http://www.cs.nyu.edu/~deigen/dnl/
3、《Depth map prediction from a single image using a multi-scale deep network》
**********************作者:hjimce 时间:2016.1.1 联系QQ:1393852684 地址:http://blog.csdn.net/hjimce 原创文章,转载请保留原文地址、作者信息************