pytorch-利用LSTM做股票预测
1.获取数据
import tushare as ts
# 获取代号为000300的股票价格
cons=ts.get_apis()
df=ts.bar('000001', conn=cons, asset='INDEX', start_date='2018-01-01', end_date='')
2. 对于获取的数据按日期进行升序排列,因为我们要通过历史的情况预测未来的情况
df=df.sort_index(ascending=True)
print(df.head(5))
3.取开盘价,收盘价,最高价,最低价,交易量五个特征,并做标准化
df=df[["open","close","high","low","vol"]]
df=df.apply(lambda x:(x-min(x))/(max(x)-min(x)))
4.构造X和Y
思路:我们根据前n天的数据,预测当天的收盘价(close),例如,根据1月1日,1月2日,1月3日的数据(包含5个特征) 预测 1月4日的收盘价(一个值)
比如:X=[ ["open1","close1","high1","low1","vol1"] ,["open2","close2","high2","low2","vol2"]["open3","close3","high3","low3","vol3"] ] Y=[ close4 ]
这个例子中,X对应的sequence length为3,input_size=5 (这tm就是nlp中词的embedding的概念)
我这边是设定 sequence 长度为5 ,就是根据前5天的数据来预测收盘价
sequence=5
X=[]
Y=[]
for i in range(df.shape[0]-sequence):
X.append(np.array(df.iloc[i:(i+sequence),].values,dtype=np.float32))
Y.append(np.array(df.iloc[(i+sequence),1],dtype=np.float32))
print(X[0])
print(Y[0])

5.划分训练集,测试集,构造数据迭代器等常规操作
class Mydataset(Dataset):
def __init__(self,xx,yy,transform=None):
self.x=xx
self.y=yy
self.tranform = transform
def __getitem__(self,index):
x1=self.x[index]
y1=self.y[index]
if self.tranform !=None:
return self.tranform(x1),y1
return x1,y1
def __len__(self):
return len(self.x)
# # 构建batch
trainx,trainy=X[:int(0.7*total_len)],Y[:int(0.7*total_len)]
testx,testy=X[int(0.7*total_len):],Y[int(0.7*total_len):]
train_loader=DataLoader(dataset=Mydataset(trainx,trainy,transform=transforms.ToTensor()), batch_size=12, shuffle=True)
test_loader=DataLoader(dataset=Mydataset(testx,testy), batch_size=12, shuffle=True)
6. 定义LSTM模型
class lstm(nn.Module):
def __init__(self,input_size=5,hidden_size=32,output_size=1):
super(lstm, self).__init__()
# lstm的输入 #batch,seq_len, input_size
self.hidden_size=hidden_size
self.input_size=input_size
self.output_size=output_size
self.rnn=nn.LSTM(input_size=self.input_size,hidden_size=self.hidden_size,batch_first=True)
self.linear=nn.Linear(self.hidden_size,self.output_size)
def forward(self,x):
out,(hidden,cell)=self.rnn(x) # x.shape : batch,seq_len,hidden_size , hn.shape and cn.shape : num_layes * direction_numbers,batch,hidden_size
a,b,c=hidden.shape
out=self.linear(hidden.reshape(a*b,c))
return out7.开始训练模型
criterion=nn.MSELoss()
optimizer=optim.Adam(model.parameters(),lr=0.001)
preds=[]
labels=[]
for i in range(100):
total_loss=0
for idx,(data,label) in enumerate(train_loader):
data1=data.squeeze(1)
pred=model(Variable(data1))
label=label.unsqueeze(1)
loss=criterion(pred,label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss+=loss.item()
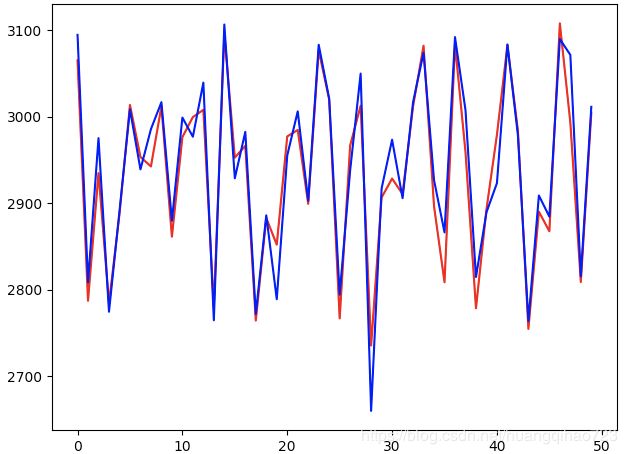
8.开始测试,将预测的收盘价与实际的收盘价画个图,红色表示预测的收盘价,蓝色表示实际的收盘价
preds=[]
labels=[]
for idx, (x, label) in enumerate(test_loader):
x = x.squeeze(1) # batch_size,seq_len,input_size
pred=model(x)
preds.extend(pred.data.squeeze(1).tolist())
labels.extend(label.tolist())下面画图,因为之前做了标准化到0-1区间,所以我图中要将收盘价恢复到原始的情况,全部取太密集,所以我只取了前50个进行比对
import matplotlib.pyplot as plt
plt.plot([ele*(close_max-close_min)+close_min for ele in preds[0:50]],"r",label="pred")
plt.plot([ele*(close_max-close_min)+close_min for ele in labels[0:50]],"b",label="real")
plt.show()