人体行为识别:Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
参考文献:https://arxiv.org/abs/1705.07750
pytorch代码实现:https://github.com/MRzzm/action-recognition-models-pytorch
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
摘要
由于目前动作分类数据集(UCF-101和HMDB-51)中视频的缺乏,大多数方法在小规模数据集基础上的性能相似,很难得到识别效果好的网络结构,本文根据最新的Kinetics人体动作视频数据集重新评估了当前最先进的网络结构。Kinetics从具有挑战的YouTube视频收集,比UCF-101和HMDB-51大两个数量级,具有400个人体动作类别和每个类别超过400个片段。我们挑选经典的图像分类方法在Kinetics数据集上进行预先训练,然后在较小的基准数据集(UCF-101和HMDB-51)上作微调。
我们还利用2D ConvNet扩充得到新的双流3D ConvNet(I3D):将深度神经网络结构中的filters和pooling kernels扩展到3D,从而更好地提取视频时序信息,又由于是从2D扩展而来,还可以利用ImageNet训练好的参数。结果表明,经过Kinetics预训练后,I3D模型在动作分类方面取得了很大的改进,HMDB-51和UCF-101数据集分别达到80.9%和98.0%。
1 引言
ImageNet是目前计算机视觉领域最大的图像数据集,有1500 万由人工注释的带标签的图片,超过 2.2 万个类别。在ImageNet数据集上训练得到的网络架构可以应用于其他任务和其他领域,例如,使用ImageNet上训练网络的fc7特征在PASCAL VOC数据集中执行分类和检测任务[10,23],且随着网络结构的改进(从AlexNet到VGG-16),PASCAL VOC数据集的性能得到改善[25]。许多例子表明,经过ImageNet训练得到的网络结构可以满足其他任务,例如目标分割、深度预测、姿势估计、动作分类等。
针对视频行为识别,在一个足够大的数据集上训练一个动作分类网络,当应用于不同的时空任务或数据集时,是否会在性能上有相似的提高,这是一个悬而未决的问题。建立具有挑战的视频数据集味着大多数流行的动作识别数据集的基准都很小,大约有10万个视频。
在本文中,我们使用新的Kinetics人体动作视频数据集[16]来回答这个问题,Kinetics从具有挑战的YouTube视频收集,比UCF-101和HMDB-51大两个数量级,具有400个人体动作类别和每个类别超过400个片段。
我们的实验策略是首先从现有文献中重新实现一些有代表性的动作分类神经网络结构,然后每个网络结构在Kinetics上进行预训练,最后在HMDB-51和UCF-101上分别进行微调来分析它们的迁移行为。结果表明,通过预训练可以提高系统性能,但在不同的体系结构中,性能提高程度会有很大的差异。在此基础上,我们提出了一个新的模型,该模型能够充分利用Kinetics预训练的优势,达到较高的性能。该模型被称为“双流Inflated 3D ConvNets”(I3D),在最先进图像分类网络结构的基础上,将filters和pooling kernels扩展到3D,从而得到时空分类器。基于Inceptionv1[13]的I3D模型在经过Kinetics的预训练后,性能远远超过了当前状态。
在我们的模型比较中,我们没有考虑更经典的方法,如bag-of-visual-words表示[6,19,22,33],但是Kinetics数据集是公开的,可以使用它进行此类比较。
本文的工作安排如下:第2节阐述目前最先进的动作分类模型,第3节介绍Kinetics数据集,第4节报告了模型在先前基准和Kinetics数据集上的性能,第5节研究了在Kinetics学习到的特征如何迁移到不同的数据集,第6节讨论。
2 动作分类的网络结构
虽然近年来基于图像表示的网络结构发展很快,但目前仍然没有一个清晰的基于视频信息表示的网络结构。目前视频网络结构中的一些主要区别在于:卷积和层的运算是使用2D(基于图像)还是3D(基于视频)kernels;网络的输入仅仅是RGB视频还是RGB视频+预计算的光流;在2D ConvNets的情况下,信息是如何跨帧传播的,这可以使用诸如LSTMs之类的临时递归层,或者随着时间的推移使用特征聚合来完成。
在本文中,我们比较和研究了动作分类模型包括:在2D ConvNet方法中,我们考虑了ConvNet+LSTMs[5,37]和两种不同类型流融合的双流网络[8,27];我们还考虑了3D ConvNet[14,30]:C3D[31]。
作为主要的技术贡献,我们提出了双流Inflated 3D ConvNets(I3D)。由于参数高维和缺少标记的视频数据,以前的3D ConvNets相对较浅(多达8层)。我们观察到,非常深的图像分类网络,例如Inception[13]、VGG-16[28]和ResNet[12],可以简单地扩展为时空特征提取器,并且它们的预训练权重提供了有价值的初始化。我们还发现双流配置仍然有用。
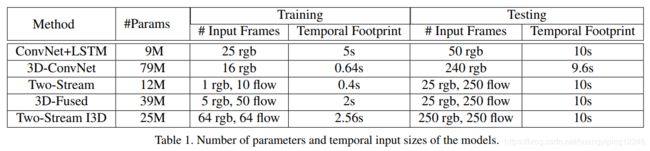
我们评估的五种网络结构的图形概述如图2所示,模型参数大小和输入如表1所示。
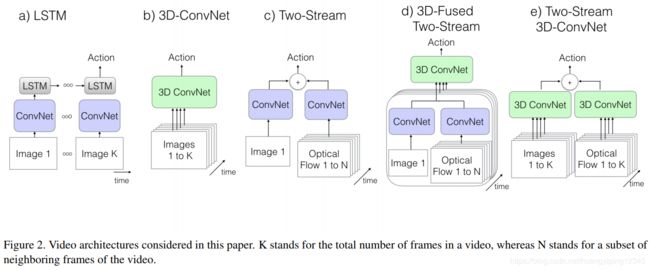
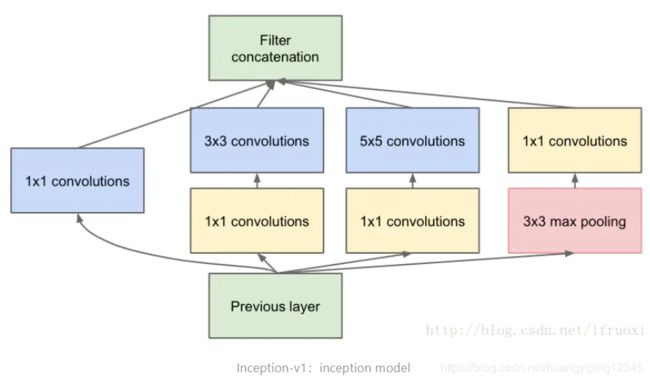
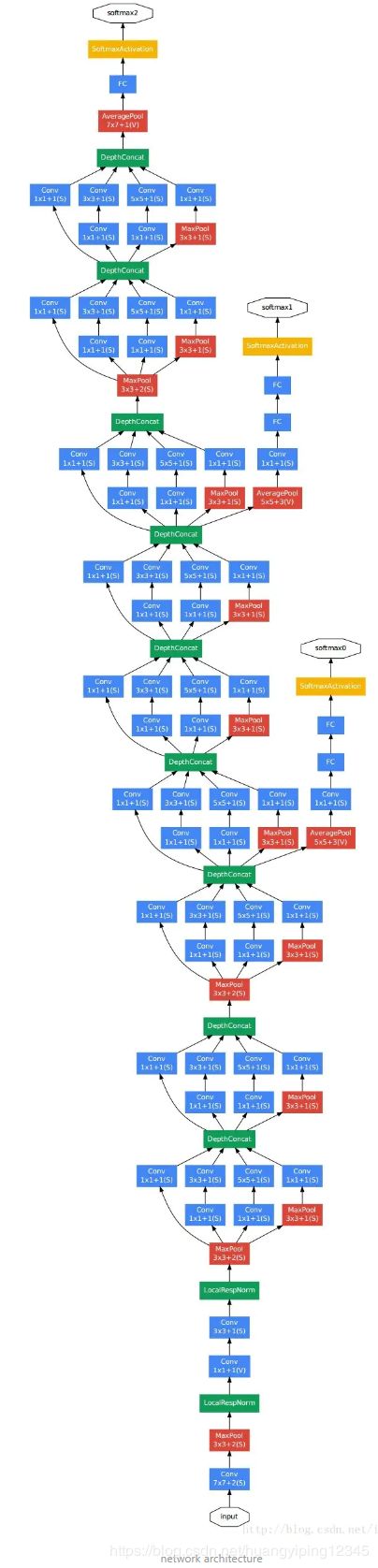
我们的实验策略以一个公共的ImageNet预训练图像分类网络结构作为背景(C3D除外),选择了带有batch normalization的Inception-v1[13]作为骨干网络,并以不同的方式对其进行变换来适应各个具体的网络结构。我们的期望是,在相同骨干网络的基础上,更好地梳理出那些最有利于动作分类的组件。
补充:Inception-v1网络结构

2.1. The Old I: ConvNet+LSTM
- 图像分类任务的高精度使得我们很想把它直接用在视频分析上;
- 最简单最方便的做法是把每帧都看成是独立的,提取图像特征后,然后取平均作为整个视频的特征,但是这样的做法完全忽略了视频的时序信息;
- 所以像图(a)中展示的更合理的做法就是增加一层长短期时间网络LSTM,来学习各个帧之间的时序信息 。所以文章在Inception-V1的最后一个average-pooling后面加了一个包含512个隐含节点的LSTM,最后跟的是一个用于分类的全连接层。
2.2. The Old II: 3D ConvNets
- 3D ConvNets看起来应该是处理视频分析最自然的方法;
- 但是3D网络比2D网络拥有更多的模型参数,这也代表网络更难训练;
- 而且因为本来就是3D的结构,所以它们看起来没有办法享受到ImageNet预训练的好处;
- C3D本身也是一个非常经典的3D convNet,我们来看一下3D convolution的示意图,具体的细节就不展开了

- 在实验中对原始的C3D的结构做了一些小的变化,这里就不再说具体的了,对这篇文章来说主要掌握到知道C3D大概是什么样子就可以了。
2.3. The Old III: Two-Stream Networks
why two-stream?
- 像ConvNet+LSTM这样的结构中,可能能够提取到高层的一些变化信息,但是对帧与帧之间低层动作信息建模是不够的, 而这一点在action recognition中是非常重要的;
- two-stream就从不同的角度解决了这个问题:一路是RGB帧,另一路是计算得到的光流,这样就对时间和空间的信息提取都比较好;
- 这种方法在现有benchmarks上的表现都不错,而且比较容易训练和测试。
two different fusion methods
- 图2(c): 取一帧图像预测的结果与光学流图像预测的结果取平均;
- 图2(d): 是在图2(c)基础上的一种扩展,通过一个3D ConvNet对多帧的信息进行融合,取到两个Stream的最后一个average pooling层的输出,作为3D ConvNet部分的输入,先是512个(3,3,3)的卷积核,然后是一个(3,3,3)的max-pooling,最后是一个全连接层。
两个Two-Stream模型都是端到端的方式进行训练的。
2.4. The New: Two-Stream Inflated 3D ConvNets
我们展示了3D ConvNet如何从ImageNet 2D ConvNet设计中获益,以及如何从它们的学习参数中获益。我们还采用了双流配置(在第4节中显示),虽然3D ConvNets可以直接从RGB流学习时间模式,但是通过包含光流,它们的性能仍然可以大大提高。
2D ConvNets扩展为3D。通过多年来艰苦的尝试,已经开发出许多非常成功的图像分类网络结构。我们简单地将图像(2D)分类模型扩展为3D ConvNets,而不是重复时空模型的过程。这可以从一个2D网络结构开始,对所有的过滤器进行扩展,过滤器的核赋予额外的时间维度,滤波器通常是正方形的,我们只需使 N × N N×N N×N滤波器变为 N × N × N N×N×N N×N×N滤波器。
从二维滤波器扩展到三维滤波器。除了网络结构之外,还需要从预先训练的ImageNet模型中扩展网络参数。为了做到这一点,我们观察到一个图像可以通过反复复制到一个视频帧序列中来生成一个(无聊)视频。我们可以在无聊视频的固定点上用ImageNet数据集隐式地预先训练3D模型,无聊视频上的pool激活应该与原始的单个图像输入相同。由于是线性的,可以通过沿时间维度重复2D滤波器的权重N次,并通过除以N来重新缩放它们,这确保了卷积滤波器维度响应是相同的。由于用于无聊视频的卷积层的输出在时间上是恒定的,所以逐点非线性层、平均和最大池化层的输出与2D的情况相同,因此整个网络维度响应遵循无聊视频固定点。文献[21]研究了其他扩展策略。
感受野在空间、时间和网络深度上的增长。无聊视频的固定点给如何沿时间维度扩展池操作以及如何设置卷积/池时间stride留下了足够的自由度——这些是形成特征感受野大小的主要因素。事实上,所有的图像模型都对两个空间维度(水平和垂直)一视同仁——pool核和stride的效果是一样的,这是很自然的,这意味着网络中更深层次的特征在两个维度上都同样受到越来越深的图像位置的影响。然而,当考虑时间时,对称的感受野并不一定是最佳的,这取决于帧速率和图像尺寸。如果它相对于空间在时间上增长过快,可能会融合不同对象的边缘,破坏早期的检测特征,而如果增长过慢,可能无法很好地捕捉场景动态变化。
在Inception-v1中,第一卷积层的stride为2,然后在最后一个线性分类层之前有4个步长为2的最大池化层和一个7×7的平均池化层,此外并行Inception分支中有最大池化层。在我们的实验中,输入视频以每秒25帧的速度进行处理,我们发现在前两个最大池化层中(使用1×3×3核和时间stride为1)不执行时间池,而在其他最大池化层中使用对称的核和stride是有帮助的,最后的平均池化层使用2×7×7核。整体网络结构如图3所示,我们使用64帧片段训练模型,并使用整个视频进行测试。

两个3D流。虽然3D ConvNet能够直接从RGB输入中学习运动特征,但它只执行纯前馈计算,而光流法在某种意义上是递归的(例如,它们对流场执行迭代优化)。我们发现,使用一个基于RGB输入的I3D网络和另一个承载优化的平滑流信息的流输入(如图2、e所示)的两流配置是有价值的。我们分别训练这两个网络,并在测试时将它们的预测结果进行平均。
2.5 实现细节
除了C3D-like的3D ConvNet之外,所有模型都使用imagnet预训练的Inception-V1[13]作为基础网络。对于所有的网络结构,除了产生每个动作类别分数的最后一个卷积层外,每个卷积层后都跟batch normalization [13]层和ReLU激活函数。
训练使用标准SGD算法,所有情况下动量设置为0.9,除了接收大量输入帧而需要更多GPU才能形成大批量的3D ConvNets之外(64 GPU),所有模型的同步并行化均为32 GPU进行训练。我们训练了110k steps的Kinetics模型,当验证损失值收敛时,学习率降低10倍。我们调整了Kinetics验证集上的学习率超参数,在UCF-101和HMDB-51上微调时,使用与Kinetics相似的学习率,但仅使用16 GPU。所有模型均在TensorFlow[1]中实现。
众所周知,数据增强对于深度神经网络的性能至关重要。在训练过程中,我们使用了随机裁剪两种方法,一种是在空间上——将较小视频帧一侧的大小调整为256像素,然后随机裁剪224×224块,另一种是在时间上,在足够早的时间内选择开始帧,以保证所需的帧数。对于较短的视频,我们根据需要循环视频帧多次,以满足每个模型的输入尺寸。在训练过程中,我们还对每个视频应用随机的左右翻转。在测试期间,将模型卷积应用于整个视频中,采集224×224个中心物,并对预测值进行平均。我们对256×256视频进行了空间卷积测试,但没有观察到改进。通过在测试时同时考虑左右翻转的视频,以及在训练过程中添加额外的增强(如光度),可以获得更好的性能,我们把这个留给以后的工作。
我们使用TV-L1算法计算光流[38]。
3 人体行为识别数据集Kinetics
Kinetics数据集关注人类行为(而不是活动或事件)。动作类别包括:人的动作(单个人),例如绘画、喝酒、大笑、打拳;人的动作,例如拥抱、亲吻、握手;人-物体动作,例如打开礼物、修剪草坪、洗盘子。有些动作是细粒度的,需要时间推理来区分,例如不同类型的游泳。其他动作需要更加强调物体的区分,例如演奏不同类型的乐器。
该数据集有400个人类动作类别,每个类有400个或更多的片段,每个片段来自一个独特的视频,总共有240k个训练视频。这些视频片段长度约10秒,没有未经剪辑的视频。测试集由每个类别的100个片段组成。文献[16]中给出了数据集的完整描述及其构建方式。
4 不同网络结构的比较
在本节中,我们将比较第2节中描述的五种网络结构的性能。
表2显示了在UCF-101、HMDB-51和Kinetics上进行训练和测试时的分类精度。我们在UCF-101和HMDB-51的split 1测试集上进行了测试,在Kinetics的held-out测试集上进行了测试。值得注意几点:
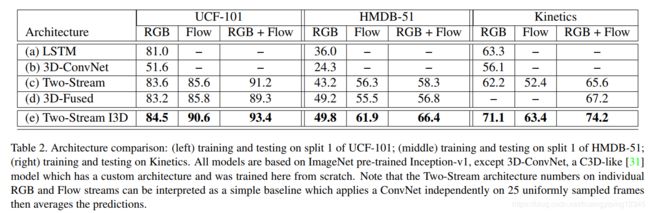
第一,我们提出的I3D模型在所有数据集中都表现得最好,无论是RGB、flow还是RGB+flow模式。这很有趣,因为模型参数非常多,而且UCF-101和HMDB-51非常小,这表明ImageNet预训练的好处可以扩展到3D ConvNets而不会严重过拟合。
第二,所有模型在Kinetics性能都远低于UCF-101,这表明两个数据集的难度不同。然而,在Kinetics性能比HMDB-51上的要高,一部分原因是HMDB-51缺乏训练数据,另一部分原因是HMDB-51数据集是故意构建的,因此难度很高(许多片段在完全相同的场景中有不同的动作,例如“拔剑”的例子取自与“拔剑”和“练剑”相同的视频)。
第三,不同网络结构的排名基本一致。
第四,两种流结构在所有数据集上都显示出优越的性能,但Kinetics数据集与其他数据集的RGB和flow的相对值存在显著差异。flow的贡献,略高于UCF-101上RGB的贡献,HMDB-51上的贡献大得多,Kinetics上的贡献大幅度降低。通过看数据集的视频,Kinetics有更多的相机运动,这可能会使运动流的工作更加困难。与其他模型相比,I3D模型似乎能够从流中获得更多的信息,然而,这可以用长时间感受野(训练期间64帧vs10帧)和更完整的时间特征提取机制来解释。虽然RGB流似乎具有更具辨别力的信息(在Kinetics中,我们经常用自己的眼睛从流中辨别动作,而RGB的情况很少如此)似乎是合理的,但将来可能将某种形式的运动稳定化集成到这些网络结构中。
我们还评估了从ImageNet预训练权重开始的Kinetics训练模型与从零开始的Kinetics训练模型的性能,结果如表3所示。可以看出,ImageNet预训练在所有流情况下仍然是有帮助的,这对于RGB流来说稍微更为明显。
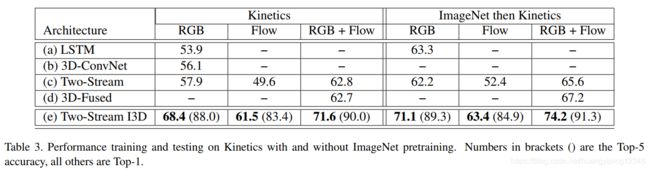
5 Kinetics预训练模型迁移到其他数据集
在这一节中,我们研究了Kinetics训练网络的可推广性。我们考虑了两种措施:首先,我们冻结网络权重,并使用网络为UCF-101/HMDB-51数据集的(未显示的)视频生成特征,为UCF-101/HMDB-51类(使用其训练数据)训练多路softmax分类器,并在其测试集上进行评估;然后,我们为UCF-101/HMDB-51类(使用UCF-101/HMDB-51训练数据)微调每个网络,并在UCF-101/HMDB-51测试集上进行评估。
我们还研究了预先训练ImageNet+Kinetics而不仅仅是预先训练Kinetics。
结果见表4。明确的结果是,所有的网络架构都受益于Kinetics视频数据的预训练,但有些网络结构的获益明显大于其他架构,特别是I3D ConvNet和3D ConvNet(尽管后者的起点要低得多)。在Kinetics(固定)预训练后仅训练最后一层模型也比在UCF-101和HMDB-51上直接训练I3D模型有更好的性能。
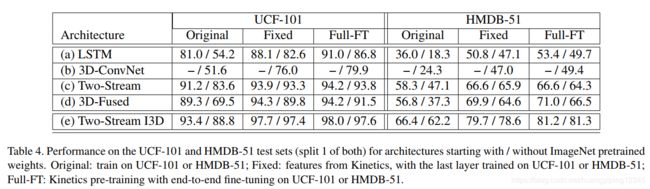
I3D模型具有显著更好迁移性的一个解释是它的高时间分辨率——它们以每秒25帧的速度在64帧视频片段上进行训练,并在测试时处理所有视频帧,这使得它们能够捕获动作的细粒度时间结构。换言之,视频输入较稀疏方法从这种大型视频数据集的训练中获益可能较少,因为从它们的角度来看,视频与ImageNet中的图像差别不大。与类似C3D模型的区别可以解释为I3D模型的深度更大,参数更少,利用ImageNet的warm-start,在4倍长的视频上训练,以及在2倍高的空间分辨率视频上操作。
即使是从头训练(没有ImageNet或Kinetics),两个流模型的性能特别好,主要是由于流的准确性,导致不容易过拟合(未显示)。Kinetics预训练比ImageNet有更大的帮助。
5.1 与先进方法的比较
在UCF-101和HMDB-51数据集上,我们在表5中比较了I3D模型和以前最先进的方法的性能。我们展示了在Kinetics数据集上进行预训练时的结果(有或没有ImageNet预训练)。训练模型的conv1滤波器如图4所示。

许多方法得到了相似的结果,但目前在这些数据集上表现最好的方法是Feichtenhofer及其类似的方法[7],他们在RGB和光流上使用ResNet-50模型,当与密集轨迹模型结合使用时[33],在UCF-101上得到94.6%,在HMDB-51上得到70.3%。我们在三个标准训练/测试split上求平均精度对我们的方法进行了基准测试。单独使用我们的RGB-I3D或RGB流模型,在Kinetics进行预训练时,任何模型或模型组合的性能都优于所有最先进方法的性能。我们的双流架构大大增加了与先前模型比较的优势,使UCF-101的总体性能达到98.0,HMDB-51的总体性能达到80.9,与之前最好的模型相比,分别降低了63%和35%(?)。
Kinetics预先训练的I3D模型与先前的3D ConvNets(C3D)之间的差异很大,尽管C3D是在更多的视频上训练的(来自Sports-1M的1M示例加上一个内部数据集),这一方面是因为Kinetics数据集的质量更好,另一方面是I3D的网络架构很好。
6 讨论
我们回到引言中提出的问题“从视频表示中进行迁移学习有好处吗?”, 很明显,在大型视频数据集Kinetics的预训练中有相当大的好处,正如在ImageNet上对ConvNets进行预训练中有这样的好处一样。本文展示了从一个数据集(Kinetics)到另一个数据集(UCF-101/HMDB-51)的类似任务(尽管针对不同的动作类别)的转移学习。然而,将Kinetics预训练用于其他视频任务(如语义分割、目标检测或光流计算)是否有好处,还有待观察。
当然,我们没有对网络结构进行全面的研究——例如,我们没有使用action tubes[11,17]或注意机制(attention mechanism)[20]来关注人员。最近的研究提出了一种富有想象力的方法来确定双流结构中参与者的时空范围(检测),方法是在时间上结合目标检测[24,26]。时空关系是一种神秘的关系,最近有几篇非常有创意的论文试图捕捉这种关系,例如通过学习动作类别的帧排序函数并将其用作表示[9]在动作和变换之间进行类比[36]或通过创建帧序列的二维可视快照[2]–这一思想与[3]的经典运动有关。在我们的比较中包括这些模型是很有价值的,但是因为缺乏时间和空间,因此不能比较。