小米品牌广告引擎与算法实践
品牌广告是小米商业化的重大战略方向,在小米视频、音乐、浏览器等多个媒体广泛投放,广告样式也越来越多样,开屏、视频、信息流等。品牌广告主对投放的需求也日益复杂和多样化,精准定向、频控、跨媒体投放、预算平滑等使得品牌广告投放引擎和算法面临着诸多挑战,包括流量预估、库存分配和在线投放算法等。本次分享重点介绍了小米品牌广告引擎与算法实践,包括系统架构和各种离线和在线算法。
小米品牌广告业务简介
小米大概是从2014年中开始广告平台的研发,一开始主要是效果广告,从去年开始大力发展品牌广告。
什么是品牌广告?这个说法一般是相对效果广告来说的。我们知道,效果广告的目的是追求立即的转化和效果,比如搜索广告,手机上的应用分发等。而品牌广告一般是为了品牌认知度,也就是brand awareness。当然品牌和效果的界限并不是这么严格,广告主很多时候也会追求品效合一。
目前,品牌广告在小米手机和电视全系资源都有投放,包括小米浏览器、视频、音乐、新闻资讯、天气、日历等系统app,还有小米电视和盒子等。广告形式也是非常丰富,基本上主流的产品形态都支持,包括开屏、锁屏、电视画报、信息流、横幅、贴片,甚至一些非标的广告形态比如换肤等。从业务规模来说,小米一共有20多款日活过千万的系统app,每天的广告曝光已经接近百亿,年收入规模也是达到了好几十亿。

小米品牌广告业务特点
品牌广告从售卖方式来看,一般是CPT或者CPM,提前一段时间下单。另外,品牌广告订单是合约式的,需要保量,如果违约,比如没有完成约定的投放量,一般都需要补量或者赔偿。提前下单意味着需要进行流量预估,违约补偿意味着分配算法需要有明确的优化目标,这都是接下来想重点讨论的话题。

品牌广告的第二个重要特点是定向。定向是每个广告平台必备的功能,各家平台在定向维度上有一些差别,但大体上的类别是相似的。比如用户属性的定向,包括人口属性:年龄性别学历,地域属性,兴趣属性等。另外,时间定向,支持小时级的定向。设备定向,支持不同手机型号,电视盒子型号的定向。内容定向,主要是针对视频/音乐等内容的分类,剧集,CP等,比如你可以定向投放综艺、动漫、体育视频,也可以定向投放某一部剧比如太阳的后裔等。人群包定向,包含或者排除指定的人群包。特殊定向,比如针对天气状况:下雨还是天晴、温度、PM2.5的情况等等都可以进行定向。
频控是品牌广告另一个重要的特点,也是品牌库存分配的核心技术挑战,后面会详细展开讨论。目前我们系统支持按照小时/日/周/月级别的频控。
最后一点,品牌广告的投放一般都需要支持第三方监测,目前我们系统支持秒针/admaster/double click等主流的第三方监测。
小米品牌广告系统架构
整个系统架构包含三大块,首先是广告检索,左上的部分。其次是广告售卖,左下部分。最后是数据处理,右边灰色的部分。
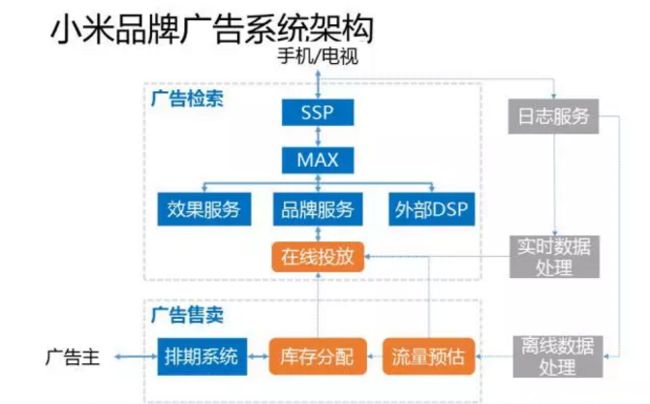
我们先来看广告检索系统,手机和电视的流量通过SSP接入我们的广告平台,SSP是我们的流量方管理平台,负责流量的接入。MAX是小米的广告交易系统AD EXCHANGE。MAX后面对接了很多个DSP,其中效果服务和品牌服务,是我们自己的DSP,分别对应我们的效果广告和品牌广告。除了我们自己的DSP,我们还对接了很多外部的DSP和广告平台,包括腾讯广点通、百度联盟、京东、阿里、品友等。效果服务的内部实现,这里没有详细讲,主要包括广告的检索、过滤、CTR/CVR预估、排序等。而品牌服务和效果服务也有很多相似的地方,包括广告检索、过滤、定向、平滑等。但品牌服务和效果服务最大的不同是,品牌服务没有CTR/CVR预估,对应的是在线投放模块。这是品牌DSP非常核心的一块。
我们再来看看广告售卖系统,也就是我们的排期系统。排期系统提供了一整套的订单管理和库存分配的功能,包括定量、寻量、删量、改量等。其中库存分配又依赖于流量预估模块。
最后一块是数据处理,右边灰色的部分,包括日志服务、离线数据处理、实时数据处理等。离线数据处理的结果会用于流量预估,而实时数据处理则用于在线投放的实时反馈。
整个系统架构中和品牌广告最相关也是最核心的部分,就是土黄色的这三块:在线投放,库存分配,流量预估。其中流量预估是基础,在线投放和库存分配都依赖于流量预估。
流量预估
我们来看一个例子,广告主打算购买12/25日这一天在小米视频首页焦点图这个广告位,北京男性用户的流量。这个需求可以分解成三部分:日期/广告位/定向条件。日期可以是一天,也可以是多天。如果想买一天内的流量,则是通过时间定向。定向条件:广告主可以指定任意维度的定向。

这样一个需求,背后有什么技术挑战呢?首先是定向预估,我们系统中支持的定向维度非常多,而广告主一般会任意组合,所以组合维度更多。在组合维度爆炸的情况下想要精准预估每一个维度是件非常困难的事情。第二个挑战是总量预估,流量一般随时间和季节变化。比如小米视频,一般来说周末的流量比工作日的流量高。还有寒暑假,双11,米粉节,这些都是需要考虑的因素。
流量预估系统的衡量指标,最主要是看预估的准确性,我们一般是用rmse作为衡量指标,也会更进一步计算高估率和低估率等。
流量预估 - 系统架构
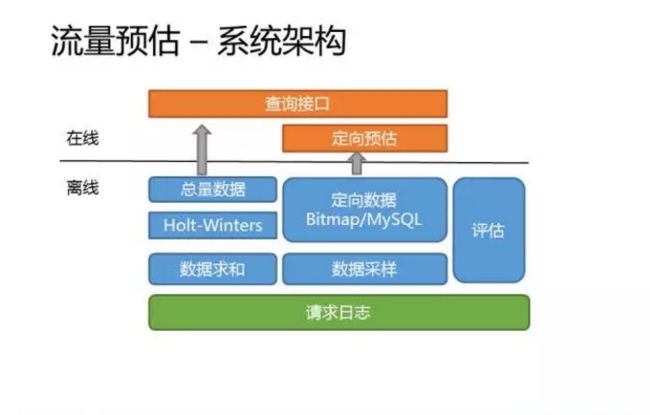
流量预估的系统架构分为离线和在线两部分,主要的工作都是离线的部分,在线部分提供了数据的查询接口。离线部分又可以分为三大块,一块是总量数据处理,一块是定向数据处理,还有就是算法评估。总量数据依赖于请求日志,先进行数据求和,然后采用holt-winters算法进行总量预估。定向数据也是依赖于请求日志,取决于后续的预估算法,定向数据的处理和存储可能会略有差别。我们系统中实现了两套独立的预估算法,下一页PPT会详细讲。其中bitmap算法需要对请求日志进行采样,结果以bitmap的形式直接放到内存中查询。而正交算法不需要做采样,定向数据经过处理之后存储到了mysql供查询。最后,算法评估模块,主要就是RMSE,高估率,低估率等指标的计算。
流量预估 - 算法描述
我们系统中实现了两套预估算法,早期我们用的是比较简单的正交算法,后来引入了位图算法,同时也保留了正交算法作为对比。
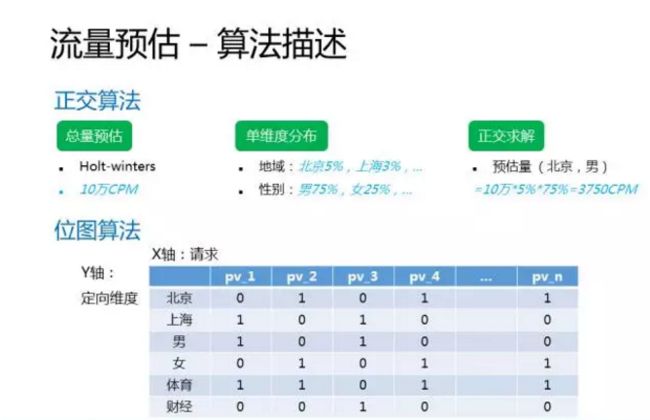
正交算法的基本思想是,假定各维度之间是相互独立,相互正交的。所以流量预估就转化成了三个步骤,首先是总量预估,这一块主要是用holt-winters算法,根据过去90天的数据来预估未来的数据。Holt-winters是比较成熟的时间序列的预测算法,我就不详细展开讲了。Holt-winters相对于移动平均算法的优势是可以很好的刻画流量随季节和时间的变化和趋势。第二步是分别计算每一个维度的分布,比如地域,我们算出来北京用户占5%,上海用户占3%。然后性别,男性用户占75%,女性用户占25%。最后就是正交求解,假定地域和性别这两个维度是相互独立相互正交的,那么北京男性用户的预估就是把两个维度的分布给乘起来。但是这个算法的假定是不成立的,比如拿北京的用户来说,可能男性用户的比例比整个大盘要高,这样对组合维度的预估就不够精确。但是单维度的定向预估会比较准确。
第二种算法是位图算法,基本思路是把请求日志映射成位图的形式。其中横轴是请求,纵轴是定向维度,取值就是0或者1。比如第一个请求,刻画的就是一个上海/男性/喜欢体育的用户,而第二个请求则是一个北京/女性/也是喜欢体育的用户。有了这个bitmap之后,如果想要查询北京/男性的比例,就把北京和男性这两行的数据进行按位与的操作。如果要查询北京或者上海用户的比例,则是把北京和上海两行的数据进行按位或的操作。所以这个算法的计算非常简单,同时多维度的预估也非常精准,但是由于请求量很大,全部放到内存中不太现实,所以我们需要进行数据采样。那采样当然就可能引起预测的不够精准。
流量预估 - 算法评估
下面我们来看一下对两个算法的一个对比和评估。首先,正交算法的优点是:简单,单维度的预估会比较准确。其实不要小看这个简单的算法,他可以解决大部分的预估问题,因为广告主的订单大部分还是单维度的定向。但是,正交算法的缺点是:组合维度的预估不够精确,这个比较好理解,因为正交算法假定维度之间是独立的,但实际情况是不可能完全独立的。
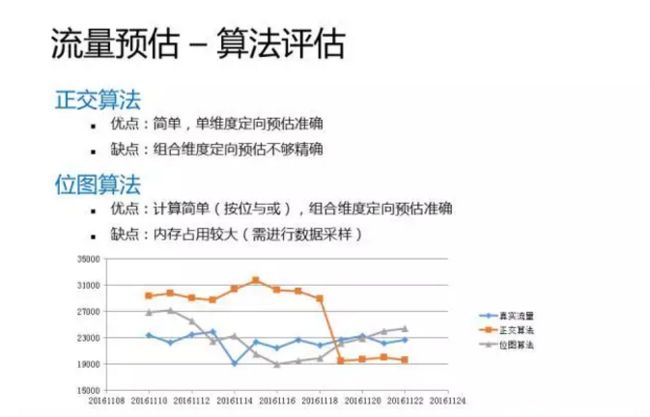
位图算法的优点:计算简单,只需要做简单的位操作,按位与或。组合维度的预估会比较准确。缺点是内存占用较大,必要的时候需要进行数据采样。
最后我们来看一下两种算法的一个实验数据,看这个图,蓝色是真实流量,黄色是正交算法,灰色是位图算法。可以看到从总体趋势来看,位图算法更贴近于真实流量,正交算法的预估一开始偏高,后来又偏低。
库存分配
我们先来看一个例子,首先是库存情况,这个图画了5个格子,每个格子代表一个CPM的流量,按照地域和性别两个定向维度来组织。从地域这个维度来看,北京有3个库存,其中2个男性1个女性。上海有2个库存,1个男性1个女性。然后我们系统中有两个订单,订单1的定向条件是北京,2个CPM,订单2的定向条件是女,也是2个CPM。我们一般把库存叫做supply或者叫做供给,订单叫做demand或者叫做需求。在这样的供需情况下,如何进行库存分配呢?
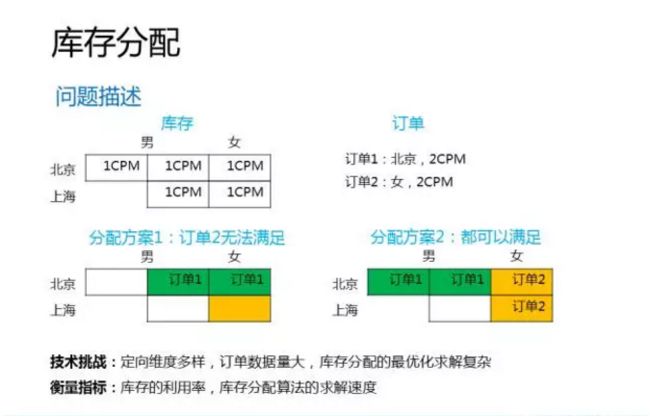
我们来看这里给出了两种分配方案,其中方案一把右上角绿色的两个北京的库存分配给了订单1,其中1个男性1个女性。这样的话订单2就无法满足了,因为整个库存只剩下一个女性用户的流量(黄色的格子)。好,那么方案二呢,把左上角绿色的两个北京男性的库存分配给了订单1,把右面两个黄色的格子分配给了订单2,这样两个订单都能满足。
这只是一个非常简单的例子,实际情况中订单量会非常大,每天上百个订单是很普遍的情况。每个订单的定向条件也比较多样化,多个订单之间会出现冲突和竞争抢量的情况。尤其是在一些热门的节日,比如双11,米粉节等,库存的售卖率会非常高。在这种情况下,库存分配是一件非常有挑战的事情。
库存分配的衡量指标,主要是库存的利用率。在排期系统中,我们的目标肯定是让尽可能多的订单进来,这一点和后面要讨论的在线投放的优化目标是不一致的。这也导致了离线分配和在线分配在实现细节上会略有不同。库存分配从技术上还需要考虑的是分配算法的求解速度,这会直接影响客户下单的效率和用户体验。
库存分配 - 问题建模
库存分配可以转化为一个带约束的最优化问题求解。还是拿上一页的例子来讲,根据供需情况可以构造出这么一个二分图,左边的圆圈是流量节点,右边的方框是订单节点。如果流量和订单之间是有关联的,则通过边进行连接,边上面的数字xij代表第个流量节点对第个订单的分配比例,也就是库存分配算法最终需要求解的目标值。
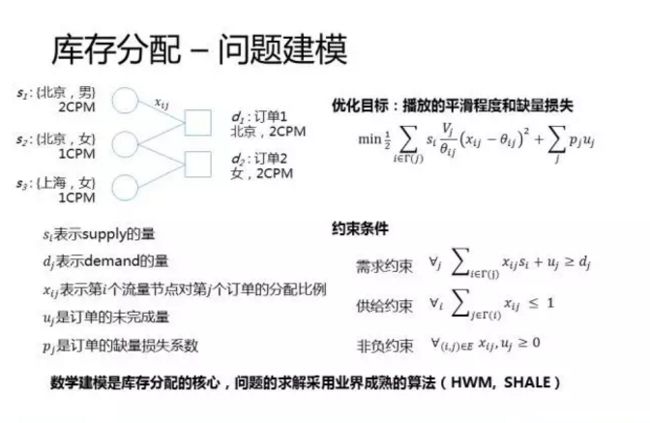
优化目标,这里给出的了一个例子,这个公式我不会展开来讲,大体意思,前半部分代表播放的平衡程度,后半部分代表缺量损失。整个优化目标就是最小化这两个取值的和。
约束条件主要有三个,需求约束,这个公式的含义是说每个订单的分配量不少于预定量。供给约束,这个公式的含义是指每个流量节点分配的流量不能超过自身能够提供的量。非负约束指的是各个分配因子都需要>=0。
库存分配的数学建模非常重要,是整个库存分配算法的核心,库存分配的求解算法反而不是最关键的,业界已经有比较成熟的两种求解算法, HWM和SHALE,由于牵涉比较复杂的数学公式的推导,我这里就不展开来讲了,感兴趣的同学可以搜索相关的论文。
库存分配的数学建模需要解决两个核心问题:首先:如何构造二分图,目标是使得二分图的节点最小化,这样问题的求解才能更快。其次:根据不同的业务场景需要制定不同的优化目标和约束条件,比如后面我们会讲到,如果广告主指定了频控,那么约束条件会有所不同。
库存分配 - 流程图
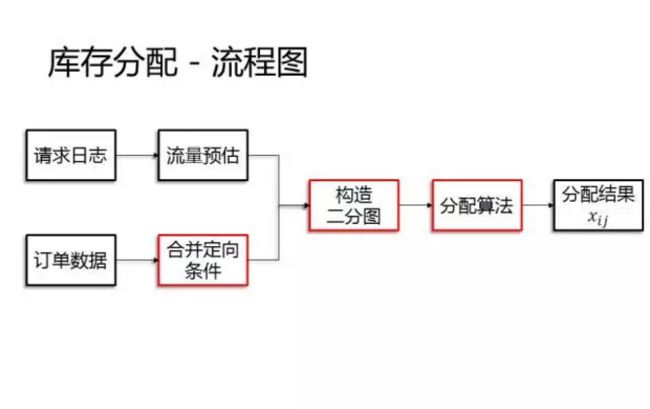
首先是根据请求日志进行流量预估,这一块前面已经讲过了,然后是根据订单数据生成最小化定向条件,这一块牵涉定向条件的合并。接下来根据流量预估和订单数据生成二分图,然后是分配算法,最后的输出是分配结果xij。接下来我们重点把红色的这三块展开来讲。
库存分配 - 合并定向条件
这一步的目标是生成最小规模的流量节点,以简化分配算法。具体来讲,我们需要为每个维度生成最小互斥的散列集合,然后再进行维度组合。

举一个例子,假设我们系统中有三个订单,订单1的定向条件是北京上海深圳这三个城市,订单2的定向条件是北京广州深圳这三个城市,同时要求是女性用户。订单3的定向条件是女性用户。这3个订单牵涉了2个定向维度,地域和性别。首先,我们假定地域的取值就是北上广深这四个城市,性别的取值就男和女。那么,在地域维度,我们可以生成的最小互斥的散列集合就是这三个,北京和深圳在一起,上海单独一个值,广州也是单独一个散列值。整个分拆和合并的过程一定要满足最小和互斥这两个条件。什么是互斥,举个例子,北京上海,和北京广州,这两个值就不是互斥的。同样,在性别维度我们得到两个散列值,男和女。
最后一步,生成候选节点,基本上就是把维度的散列值集合进行笛卡尔乘积,比如刚才这个例子,地域维度有3个散列值,性别维度有2个散列值,最后生成的候选节点就是3*2一个6个节点。
库存分配 - 构造二分图
这个步骤相对比较简单,遍历每一个候选节点,检查是否被某一个订单节点包含。如果不被任何订单包含,则丢弃。如果被某一个订单包含,则通过一条边来记录流量和订单之间的关联。在上一页PPT中,我们一共生成了6个候选节点,其中“广州,男”这个节点是不被任何订单包含的,所以最终生成的二分图一共只有5个流量节点,3个订单节点。
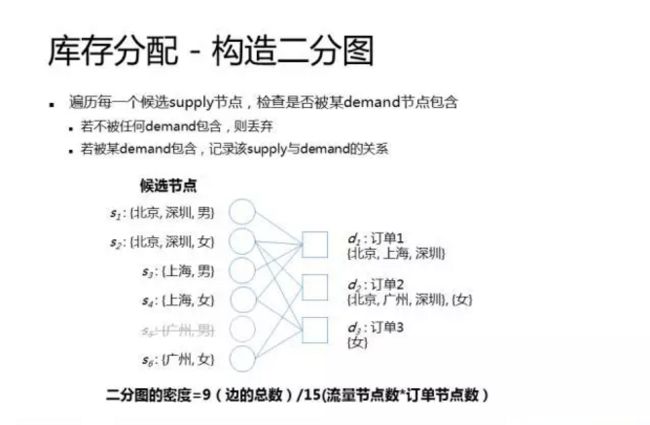
二分图的密度是一个很重要的指标,计算方式是二分图边的总数除以流量节点和订单节点的乘积,在这个例子中,一共有9条边,所以二分图的密度就是9/15=60%。二分图的密度很大程度会影响库存分配算法的求解速度。
库存分配 - 维度正交
下面我们再来看一个建模的例子,用户的兴趣属性。这也是用户画像非常重要的组成部分。但是用户的兴趣属性和人口属性有一个区别,人口属性的取值是唯一的,比如性别只能是男或者女,但是兴趣属性的取值是不唯一的,一个人可能有多个兴趣属性,比如既喜欢体育又喜欢财经。对于兴趣属性,如何进行数学建模呢?我们来看一个例子。
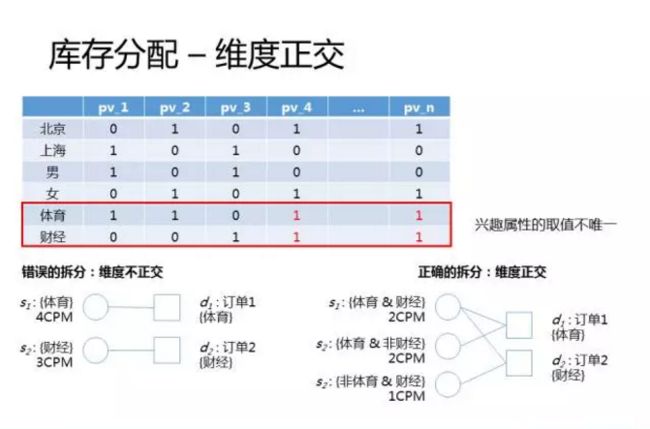
假设系统中有两个订单,订单1的定向条件是体育,订单2的定向条件是财经。如果按照前面的建模方式,构造出来的二分图如左下图所示,两个流量节点,分别是体育和财经。体育有4个CPM,财经有3个CPM,但是其实上面表格里面一共只有5个CPM,中间省略的部分不计的话,多出来2个CPM,为啥呢?因为体育和财经这两个维度不是正交的,有两个用户被重复分配到两个流量节点了。
正确的建模方法是右边这个,需要对兴趣属性的取值做一个排列组合,生成一个完整的组合列表,比如在这个例子中,体育和财经可以组合出三个节点:喜欢体育并且喜欢财经,喜欢体育不喜欢财经,不喜欢体育喜欢财经。这三个节点之间就是完全正交互斥的。这个时候再进行二分图的构造就对了。
库存分配 - 频控
频控是库存分配的一个重要的议题,也是一个难题。频控的分配和不带频控的分配,最大的区别在于流量节点的拆分。前面讲的不带频控的分配,本质上是对PV的拆分。而带频控的分配,则需要对UV进行拆分。
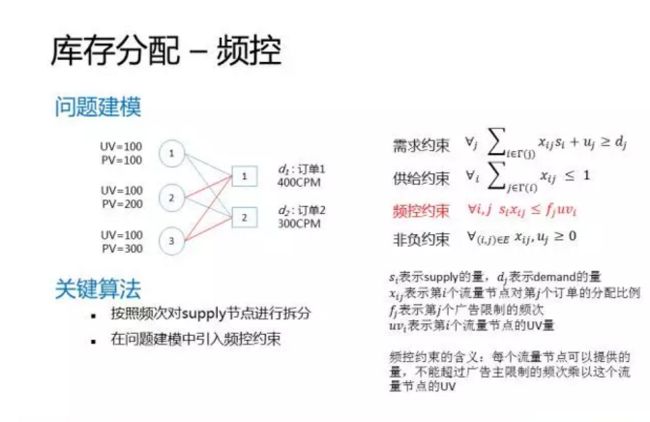
来看一个例子,有两个订单,定向条件一样,但是频控不一样。订单1的频控是1,订单2的频控是2。如果不考虑频控,由于两个订单的定向条件一样,只需要生成一个流量节点。如果考虑频控,我们就需要按照频控对同一个定向节点进行拆分。比如这个例子中,我们拆分成出了3个节点,节点旁边标注了UV和PV,比如第一个节点UV=100,PV也是100,因为这个节点代表的就是每天只有一次访问的用户。同样,第二个节点,UV=100,PV=200,代表每天有两次访问的用户,依次类推。
同样,对于约束条件来说,我们需要引入一个频控约束,如右图红色所示的公式,这个约束的含义是什么呢,意思就是说每个流量节点可以提供的量,不能超过广告主限制的频次乘以这个流量节点的UV。还是拿左边的例子来说,对于第二个流量节点和第一个订单,最多可分配的流量只有100PV,而不是200PV。为啥是100?因为流量节点的UV=100,订单节点的频控约束是1。 100*1=100PV。同样对于第三个流量节点和第二个订单,最大可分配的流量是200PV,而不是300PV。
库存分配 - 算法描述
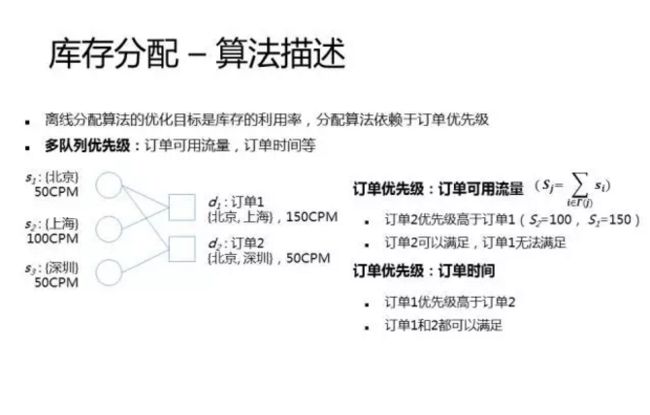
前面讲的都是问题的建模,核心就是构造二分图,制定合适的优化目标和约束条件。那接下来就是问题的求解了。前面我大概提了一下,业界已经有比较成熟的求解算法,比如HWM和SHALE,我们的离线分配算法和HWM很类似(在线分配算法是采用的SHALE),因为离线分配的优化目标是库存的利用率,分配算法依赖于订单优先级,采用启发式的算法进行求解。我们在订单的优先级方面尝试了多种不同的优先级,比如传统的按照订单可用流量进行排序,或者按照订单时间进行排序等。
这里举了一个例子,左边是二分图,我就不详细讲了,大家应该可以看懂。如果使用订单的可用流量作为订单的优先级。订单的可用流量等于订单连接的所有流量节点的总和,那么订单1的可用流量=150,而订单2的可用流量是100。订单2的优先级更高,优先进行分配,这种情况下订单1就没法得到满足了。因为s1这个流量节点有一半的流量也就是25个CPM分给了订单2,剩下的流量已经不够订单1要求的150个CPM了。如果我们订单的时间作为优先级,由于订单1先到有限分配,这种情况下两个订单都能满足。
在线投放
刚刚我们讲的库存分配其实是离线分配,接下来我们再来看看在线分配。离线分配是为了下单用,在线分配则是为了完成订单。离线分配的优化目标是库存的利用率,让尽可能多的订单进来,在线分配的优化目标则是订单的完成率和播放的平滑程度。
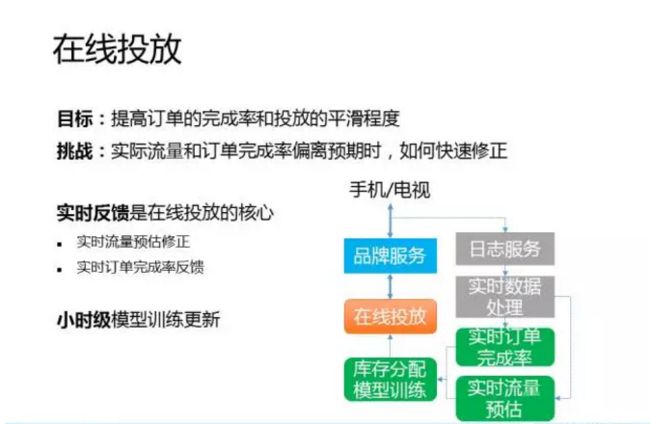
在线分配的核心技术挑战是实时反馈,当实际流量和订单完成率偏离预期时,如何快速修正。没有实时反馈,再好的分配算法也没用,因为流量预估总是会有偏差的,算法总是会有缺陷的。
实时反馈包括两个方面:实时流量预估的修正,实时订单完成率的反馈。技术实现上,主要是依赖我们的一个实时计算平台。通过实时反馈拿到最新的流量数据和订单完成率数据,再通过小时级的模型训练更新,不断修正模型,最终提高订单的完成率。
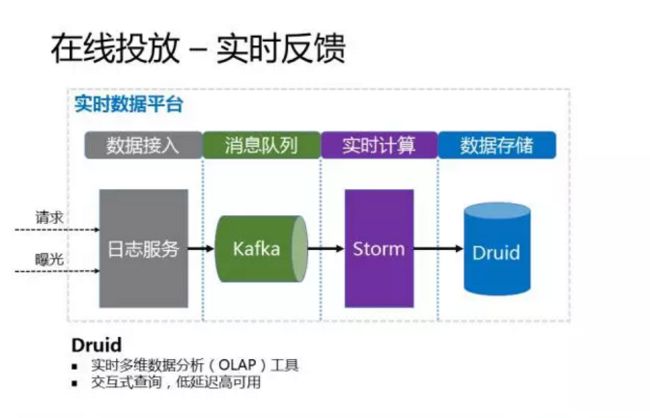
在线投放 - 实时反馈
实时反馈主要是通过我们的实时计算平台,收集到实时的数据,反馈给线上的模型进行重新训练。当然我们的实时计算平台不仅服务于在线分配,还有很多其他的广告业务,比如实时报表统计等。
我们的实时计算平台分为4层,首先是数据接入层,接收来自客户端上报的请求和曝光日志。然后消息队列我们用的是kafka,接下来的实时计算采用的是storm框架(最近也开始在尝试用spark streaming),最后数据存储用的是德鲁伊(Druid)。这里稍微提一下德鲁伊,德鲁伊是一个实时的多维数据分析工具,可以支持很多维度和很多指标的实时统计和分析,还可以进行交互式查询,并且是低延迟高可用。
在线投放 - A/B实验
分流量实验在效果广告中使用的比较多,比如CTR/CVR预估等。品牌广告的A/B实验和效果广告有一些相似,但也有一些不同。
首先,在线分配是按照“订单X实验”进行保量控制。比如我们想实验两个分配算法,流量比例各50%,那么每个算法只需要完成预定量的一半即可。
另外,离线分配的算法训练可以在全流量进行,不需要分流量。这也比较好理解,流量节点和订单节点的量如果按照同比例增加或者减少,对于模型的输出是没有影响的。
最后一点,品牌广告的A/B实验需要按天进行,所以无法动态调整流量。这一点确实是很大的局限,我们也没找到更好的办法。
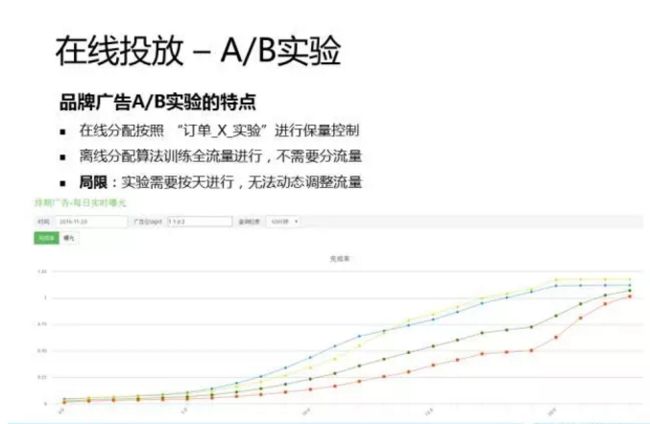
这里有一个截图,对比了不同分配算法一整天的完成率情况。可以看到,有的分配算法出现了超投,有的分配算法的平衡程度不够好,最好的算法应该是绿色这个。
在线投放 - 分析平台
最后简单介绍一下我们的分析平台,先说一下背景,不管我们的流量预估算法和库存分配算法做的有多好,我们总是会面临各种各样的问题,可能是系统问题,可能是算法问题,可能是数据问题,但现象都是一个,订单的预定量没有完成。当出现这种问题的时候,我们如何快速定位问题的根源?这很关键,所以说分析平台很重要。
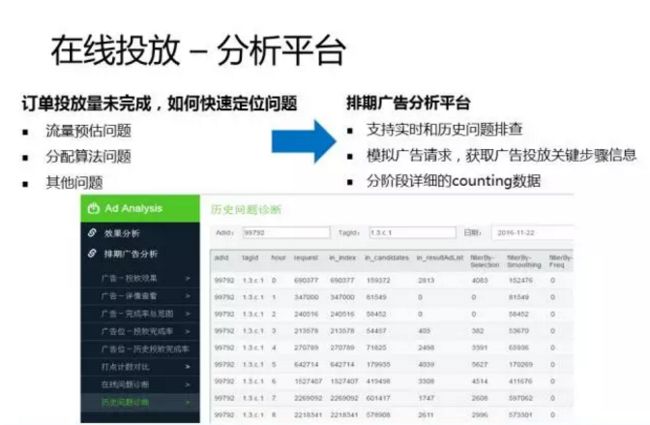
我们这个分析平台可以支持实时和历史问题的排查。对于实时问题,一般是通过发送debug广告请求,获取到广告投放每一个关键步骤的信息,可以很清晰的看到广告最终是否返回,如果没有,是在哪个步骤被干掉了等等。
对于历史问题,我们提供了分阶段详细的counting信息,比如这个截图,我们可以看到这个广告每个小时的分阶段数据统计,总的请求,有多少次被平滑过滤,有多少次被在线分配算法过滤等等。有了这些数据,我们至少可以很清楚的知道这是一个预估问题还是分配问题。
总结
简单总结一下,本次分享一开始介绍了小米品牌广告的业务情况以及系统架构。接下来重点介绍了流量预估的系统架构和算法实现,库存分配的数学建模和问题求解,在线分配的实时反馈和分析平台等。时间有限,每一块讲的都不算太深入,感兴趣的同学可以进一步交流。
作者简介 :宋强,10多年的资深老码农,做过后端开发,玩过大数据,略懂机器学习算法。目前在小米商业产品部负责广告业务研发,包括小米自有流量和移动网盟业务的变现。之前在微软STC从事搜索广告、反作弊相关工作。再之前,在IBM从事数据库和查询优化相关的工作。
更多精彩,欢迎关注CSDN大数据公众号!
