hadoop配置文件含义解释:
1 hdfs-site.xml 和 hdfs-default.xml 的区别:
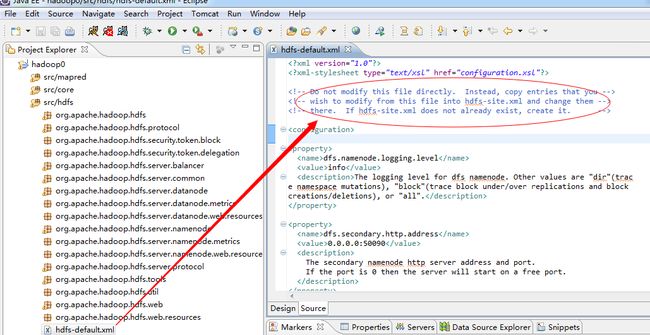
上图明确指出: hdfs的核心文件hdfs-default.xml禁止修改,如果想要自定义内容,请在hdfs-site.xml 内修改, 看单机版hadoop配置时的 hdfs-site.xml,其中对参赛fs.default.name和hadoop.tmp.dir进行了重写:
[root@master conf]# cat core-site.xml
fs.default.name
hdfs://master:9000
hadoop.tmp.dir
/usr/local/hadoop/tmp
NameNode详解:
是整个文件系统的管理节点。它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表。接收用户的操作请求。
(见源码)
文件包括:
fsimage:元数据镜像文件。存储某一时段NameNode内存元数据信息。
edits:操作日志文件。
fstime:保存最近一次checkpoint的时间
以上这些文件是保存在linux的文件系统中。
文件系统镜像simage : 存在位置:/usr/local/hadoop/tmp/dfs/name/current下
[root@master name]# cd current/
[root@master current]# ls
edits fsimage fstime VERSION
如果此文件丢失,则整个hdfs宕掉,其路径配置在 hdfs-default.xml内,贴出如下:
dfs.name.dir
${hadoop.tmp.dir}/dfs/name
Determines where on the local filesystem the DFS name node
should store the name table(fsimage). If this is a comma-delimited list
of directories then the name table is replicated in all of the
directories, for redundancy.
在文件 core.site.xml中, hadoop.tmp.dir配置如下,
hadoop.tmp.dir
/usr/local/hadoop/tmp
那么上述两部分(hdfs-default.xml + core-site.xml )综合得到的结果是:
dfs.name.dir保持位置为
${hadoop.tmp.dir}/dfs/name = /usr/local/hadoop/tmp/dfs/name
其中current是固定写法
edits: 存放用户的操作日志, 用户的操作都是一个事务,要么成功,要么失败下回滚
每次用户操作hdfs时,产生的edits会记录操作结果,然后根据fstime(合并时间),由secondnamenode将当次的edits日志内容更新到 fsimage中,然后edits清空。
上述合并操作交给 secondnamenode原因如下:
namonode响应用户请求,内存消耗大,如果此时在处理 edits和fsimage的合并,更加消耗内存,因为这合并工作交给 secondenamenode操作
合并时间fstime, 看文件 core-default.xml
fs.checkpoint.period
3600 3600秒
The number of seconds between two periodic checkpoints.
fs.checkpoint.size
67108864 大约64M 看下面的解释,这个触发的优先级更高
The size of the current edit log (in bytes) that triggers
a periodic checkpoint even if the fs.checkpoint.period hasn't expired.
Datanode详解:
作用:提供真实文件数据的存储服务,是一个文件管理系统,
你可以类比于MySQL, mysql仅仅是一个数据库管理软件,它将数据转换为mysql坑理解的格式(eg: 表-->记录-->字段)然后存储在window/linux操作系统下的物理磁盘中。
同样,通过客户端用户操作的文件通过hdfs处理,将文件划分成hdfs世界里的块,然后存储在linux系统管理的硬盘中。
hdfs文件块(block):最基本的存储单位。对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block。HDFS默认Block大小是64MB,以一个256MB文件,共有256/64=4个Block.
不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间。
针对于块的介绍引申1--Block的历史:
块并不是hdfs独有的概念, 这种数据基本存储单位出现在别的系统中,名词不一样而已,
eg: window的簇 ,Linux 为Block
hdfs借鉴linux的Block概念,但是又区别于linxu,Linux中Block是最小存储单元,即使物理文件没这么大,那么也要占用一个Block大小的物理空间,而在hdfs中,如果一个文件没有达到hdfs一个Block大小下,占用的是实际物理空间,而非一个Block(64M)
针对于块的介绍引申2---为何要划分快:
0 hdfs操作的文件很大, 如果原封不动的存储硬盘,并作为一个基本单位存储的话,
1 那么读写时都要打开此文件,加载内存耗费很大资源,读写速度自然很慢,
2 对这么大的文件操作时,文件独占,其余进程不能操作此文件,使用率降低
3 文件某块破坏,那么整个文件就废了,丢失概率为100%,而分块存储即使坏了
也就坏了某一块而已,丢失率远低于100%
针对于块的介绍引申3--64M是写死的吗?
1 这个64M可以修改,不是固定死的
其配置信息hdfs-default.xml:
dfs.block.size
67108864 64M
The default block size for new files.
针对hdfs 如果文件大于1个Block下文件大小是否占用下一整个Block的实验:
文件大小
[root@master local]# ls -l
-rwxr--r-- 1 root root 84927175 Jul 19 19:12 jdk-6u24-linux-i586.bin
先清空hdfs下文件
[root@master local]# hadoop fs -rmr hdfs://master:9000/*
查看此时 data/current下文件
[root@master current]# ls -l
total 16
-rw-r--r-- 1 root root 674 Aug 3 06:34 dncp_block_verification.log.curr
-rw-r--r-- 1 root root 158 Jul 30 06:41 VERSION
上传文件
[root@master local]# hadoop fs -put jdk-6u24-linux-i586.bin hdfs://master:9000/
再次查看
[root@master current]# ls -l
total 83724
-rw-r--r-- 1 root root 17818311 Aug 3 07:10 blk_4635014670961317001
-rw-r--r-- 1 root root 139215 Aug 3 07:10 blk_4635014670961317001_1022.meta
-rw-r--r-- 1 root root 67108864 Aug 3 07:10 blk_9146814489152210513
-rw-r--r-- 1 root root 524295 Aug 3 07:10 blk_9146814489152210513_1022.meta
-rw-r--r-- 1 root root 674 Aug 3 06:34 dncp_block_verification.log.curr
-rw-r--r-- 1 root root 158 Jul 30 06:41 VERSION
[root@master current]#
上传完毕后 在查看 data/current下文件详细
其中 xx.meta是校对文件, 可以看到,
排除原本就有的VERSION, dncp_block_verification.log.curr
和上传文件对应的 xx.meta校验文件后,新上传的文件jdk-6u24-linux-i586.bin(>64M, 84927175 )
被hdfs划分为两个block, blk_9146814489152210513-->67108864字节 blk_4635014670961317001-->17818311字节
两者大小和为84927175字节
datanode副本(理解为家里大门钥匙,分别放在不同的地方),默认配置写在 hdfs-default.xml中
dfs.replication
3 默认节点个数
Default block replication.
The actual number of replications can be specified when the file is created.
The default is used if replication is not specified in create time.