Hadoop精选18道面试题(附回答思路)
1.简述Hadoop1和Hadoop2的架构异同
HDFS HA(High Availablity)
一旦Active节点出现故障,就可以立即切换到Standby节点,避免了单点故障问题。
加入了对zookeeper支持实现比较可靠的高可用。
YARN
将MapReduce1.0中的资源管理调度功能分离出来形成了YARN,一个纯粹的资源任务管理调度框架,避免了内存受限问题。
2.简述HDFS
Hadoop分布式文件系统
文件系统
目录树定位文件
分布式
数据大,要拆,要分,再存。
"拆":block 128M
"分":编号,找namenode,分配
"存":传完第一份后内网互传
副本机制,一式三份
均衡
3.Hadoop生态系统与Hadoop框架
Hadoop生态系统除Hadoop之外,还包含zookeeper、Flume、Hbase、Hive、Sqoop等辅助框架
4.Hadoop核心组件(定义+组成+优点(思想))
HDFS 分布式文件系统 提供高吞吐量的数据访问和存储,特别适合大数据集的分布式存储。
NameNode*2(Active|Standby)+DataNode*N
具有高容错性 支持流式访问
MapReduce 分布式计算框架 用于大规模数据集的并行处理
Map+Shuffle+Reduce
分而治之 构造抽象模型
YARN 分布式资源管理系统 负责任务调度和集群资源管理
ResourceManager & ApplicationManager
NodeManager
HDFS角色
NameNode,DataNode,SecondaryNameNode
Hadoop架构
HDFS——分布式文件系统
MapReduce——分布式计算框架
YARN——分布式资源管理系统
Commons
5.Block大小
如果一个文件小于128M,它只占用文件本身大小的空间,其它空间别的文件也能用。
Block大小设置主要取决于磁盘传输速率。
(把文件分为N块,读取文件时就要寻址N次)
6.NameNode与SecondaryNameNode的区别与联系
区别
1)NameNode存储了文件系统下所有目录和文件的访问,修改,执行时间,块大小,执行权限等
2)SecondaryNameNode并非NameNode的热备(≠ StandBy NameNode)。定期触发CheckPoint(服务),代替NameNode合并EditLog和fsimage文件。
联系
1)SecondaryNameNode中保存了一份和NameNode一致的fsimage和edits文件。但是,NameNode还有一份正在使用的编辑日志edit_inporgress,这是SecondaryNameNode没有的。
2)在主namenode发生故障时(假设没有及时备份数据),可以从SecondaryNameNode恢复历史的数据。
7.SecondaryNameNode的目的是什么
SecondaryNameNode定期触发CheckPoint,代表NameNode合并编辑日志EditLog和镜像文件Fsimage,从而减小EditLog的大小,减少NN启动时间。
同时在合并期间,NameNode也可以对外提供写操作。
8.HDFS的读/写数据流程
HDFS的写(上传)数据流程

1)HDFS client创建DFS对象,通过该对象向NameNode请求上传文件,NameNode检查权限,并判断该目标文件是否已存在。
2)如果权限许可,目标文件也存在,NameNode响应请求。
3)客户端请求第一个Block上传到哪几台DataNode服务器上。
4)NameNode返回3个DataNode结点
5)HDFS client创建FS DataOutputStream数据流对象,请求dn1建立传输通道,dn1接收到请求之后会继续调用dn2建立通道…
6)传输通道建立完成之后,dn1,dn2,dn3逐级应答客户端。
7)客户端开始往dn1上传第一个Block,dn1利用通道传向dn2,dn2利用通道传向dn3…(直到传到Block副本应在的位置停止)
8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block到服务器。(重复3-7步)
HDFS的读数据流程
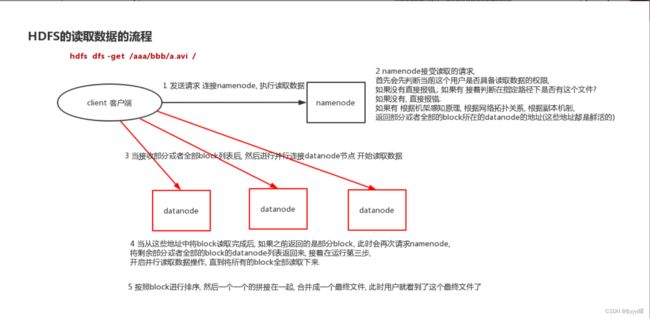
1)HDFS client创建DFS对象,该对象向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
2)挑选一台DataNode(要考虑结点距离最近选择原则,DataNode负载均衡)服务器,请求读取数据。
3)数据从DataNode传到客户端,如果在传输过程中出现宕机,才会考虑向含有该副本的其他节点获取数据。
4)客户端接收,写在本地缓存,然后写入目标文件。
9.请简述DataNode的工作机制
1)一个数据块在DataNode上以文件的形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据的校验信息。
2)DataNode 启动后向 NameNode 注册,之后周期性(默认 6 小时)的向 NameNode 上报所有的块信息。同时,DN 扫描自己节点块信息列表的时间,检查DN中的块是否完好,如果某块磁盘损坏,就将该块磁盘上存储的所有 BlockID报告给NameNode。
3)心跳是每 3 秒一次,心跳返回结果带有 NameNode 给该 DataNode 的命令如复制块数据到另一台机器,或删除某个数据块。 如果超过 10 分钟 + 30s 没有收到某个 DataNode 的心跳,则认为该节点不可用。
10.如果数据误删,如何抢救?
1.立即关闭Hadoop服务
2.打开edit_log文件,删除未发送的心跳包的命令
11.如何理解Hadoop中的数据倾斜现象?
A.可能因为HDFS的存储不均衡:可能的原因是后扩展了集群的几台机器
B.使用默认的HashPartitoner
C.输入数据中不均匀的键分布
解决方法:执行 /opt/software/hadoop-3.1.3/sbin/start-balancer.sh
12.Namenode和Datanode的心跳机制:
心跳是datanode向namenode发送的小数据包,表明它是活跃的。默认情况下,
每3秒datanode就会向namenode发送一次心跳信号。如果namenode在10分钟内
没有收到任何datanode的心跳,它会将该datanode标记为“死亡”,并开始数据
的复制过程,将其复制到其他datanode,以保持数据的冗余和可靠性。
13.Safe Mode
Safe Mode是HDFS的一种状态,在此状态下,系统处于只读模式,不会进行数据块的复制或删除。
这通常用于系统维护或故障恢复。
管理员可以使用命令"hdfs dfsadmin -safemode enter"进入安全模式,"hdfs dfsadmin -safemode leave"退出安全模式,而"hdfs dfsadmin -safemode get"则用来查询系统是否处于安全模式。
14.Hadoop启动流程
首先,启动HDFS,通常包括启动namenodes,datanodes和secondary namenodes。
其次,启动YARN的资源管理器和节点管理器。
最后,如果在集群中运行MapReduce作业,则还需要启动MapReduce的历史服务器。
15.如何检查?
检查服务:jps
检查路径:
cd /opt/software/hadoop-3.1.3/logs/hadoop-root-namenode-single.log
检查端口:netstat -anutp | grep 9870
检查安全模式:hdfs dfsadmin -safemode get
重启服务
16.YARN的组成架构
ResourceManager,NodeManager,ApplicationMaster,Container
ResourceManager
全局资源管理调度分配
ResourceScheduler
全局资源的调度与分配
ApplicationManager
接收客户端请求,监控NodeManager,启动和监控ApplicationMaster,必要时进行重启。
NodeManager
管理节点的资源与任务
定时向RM汇报节点的资源使用情况和容器运行情况
接受来自RM的开启或关闭Container的指令
接受来自AM分配MapTask|ReduceTask的指令
ApplicationMaster
负责整个应用程序
负责数据切片
向RM申请资源
分配MapTask|ReduceTask,启动或停止Container中的task
容错
Container
资源封装(CPU|DISK|MEM)
虚拟机
17.YARN的工作原理

18.Hadoop HA的整体架构
1.主备NameNode
2.主备控制转换器ZKFC
3.Zookeeper
4.JournalNodes
5.DataNode