【2023】通过docker安装hadoop以及常见报错
目录
-
- 1、准备
- 2、安装镜像
-
- 2.1、创建centos-ssh的镜像
- 2.2、创建hadoop的镜像
- 3、配置ssh网络
-
- 3.1、搭建同一网段的网络
- 3.2、配置host实现互相之间可以免密登陆
- 3.3、查看是否成功
- 4、安装配置Hadoop
-
- 4.1、添加存储文件夹
- 4.2、添加指定配置
- 4.3、同步数据
- 5、测试启动
-
- 5.1、启动配置
- 5.2、启动hadoop
1、准备
准备安装的环境,最好是cenos的环境,相对问题会少一些,我因为是mac的内存比较珍贵,所以嫌麻烦就没安装虚拟机,所以问题非常多(所以还是不要嫌麻烦最好),就使用的是mac。
- 目的:通过本地docker安装hadoop,实现一主二从的分布式存储集群安装。
- 准备:
- 准备一个内存还ok,可以安装docker的系统(最好是centos7)的。
- 把相关需要的包传到该容器环境去
- 这个是我的hadoop和jdk的版本
链接: https://pan.baidu.com/s/1EN9wtLbNv7i6X2bcTh0yhw?pwd=ibum
提取码: ibum
2、安装镜像
2.1、创建centos-ssh的镜像
- 下载安装cenos7镜像
docker pull cenos:7
这里贴一下常用指令Dockerfile的常用指令,想详细学习可以了解Dockerfile文件可以看我 docker安装部署容器这一篇文章。

- 创建一个Dockerfile文件
通过Dockerfile文件创建镜像,通过ssh实现可以共用一个局域网
FROM centos:7
MAINTAINER zfp
# 添加EPEL源(如果直接是centos的环境可以不用加)
RUN yum install -y epel-release
# 安装 openssh-server 和 sudo
RUN yum install -y openssh-server sudo
# 修改 SSH 配置文件,禁用 PAM 认证。
RUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config
#安装 OpenSSH 客户端
RUN yum install -y openssh-clients
#配置 SSH 服务
RUN echo "root:123456" | chpasswd
RUN echo "root ALL=(ALL) ALL" >> /etc/sudoers
RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
# 创建运行 SSH 服务所需的目录
RUN mkdir /var/run/sshd
# 暴露 SSH 端口
EXPOSE 22
# 启动 SSH 服务
CMD ["/usr/sbin/sshd", "-D"]
- 构建centos7-ssh
docker build -t="centos7-ssh" .
将生成一个名为centos7-ssh的镜像
2.2、创建hadoop的镜像
- 准备需要的包,包需要和Dockerfile在同一级目录下
hadoop的jdk和hive的,该镜像除了hadoop还需要有jdk,所以需要先把jdk的包先准备好,因为要用到hive,我把hive的包也内嵌进去了,所以需要把包先准备好。

- 继续创建一个Dockerfile文件
FROM centos7-ssh
ADD jdk-8u361-linux-x64.tar.gz /usr/local/
#需要确认解压之后的文件名称对不对应得上
RUN mv /usr/local/jdk1.8.0_361 /usr/local/jdk1.8
ENV JAVA_HOME /usr/local/jdk1.8
ENV PATH $JAVA_HOME/bin:$PATH
ADD hadoop-3.3.4.tar.gz /usr/local
RUN mv /usr/local/hadoop-3.3.4 /usr/local/hadoop
ENV HADOOP_HOME /usr/local/hadoop
ENV PATH $HADOOP_HOME/bin:$PATH
ADD apache-hive-3.1.3-bin.tar.gz /usr/local
RUN mv /usr/local/apache-hive-3.1.3-bin /usr/local/hive
ENV HIVE_HOME /usr/local/hive
ENV PATH $HIVE_HOME/bin:$PATH
RUN yum install -y which sudo
- 构建镜像
docker build -t="centos7-ssh" .
3、配置ssh网络
3.1、搭建同一网段的网络
-
创建网络
docker network create --driver bridge hadoop-br -
配置三台容器的网络,hadoop1因为是主节点,所以需要把web的页面端口映射出来。
docker run -itd --network hadoop-br --name hadoop1 -p 50070:50070 -p 8088:8088 hadoop
docker run -itd --network hadoop-br --name hadoop2 hadoop
docker run -itd --network hadoop-br --name hadoop3 hadoop
- 查看网络
docker network inspect hadoop-br
会看到对应的容器的ip
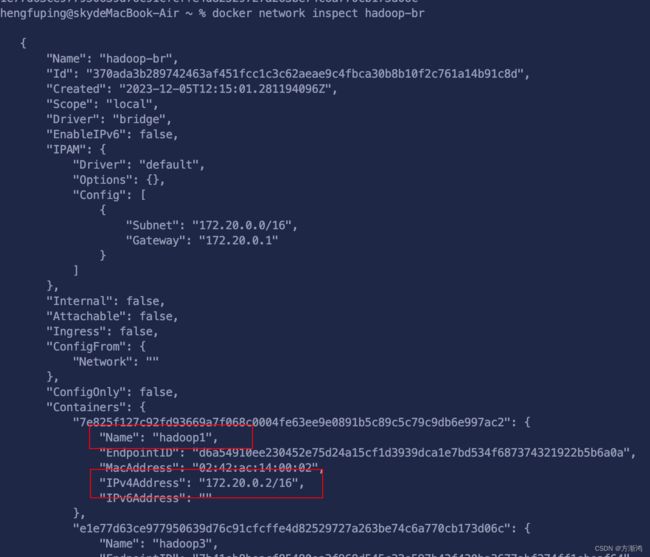
这个是我的,可以看自己的对应的,最后一位会从2开始
172.20.0.2 hadoop1
172.20.0.3 hadoop2
172.20.0.4 hadoop3
3.2、配置host实现互相之间可以免密登陆
- 分别进入不同的容器
docker exec -it hadoop1 bash
docker exec -it hadoop2 bash
docker exec -it hadoop3 bash
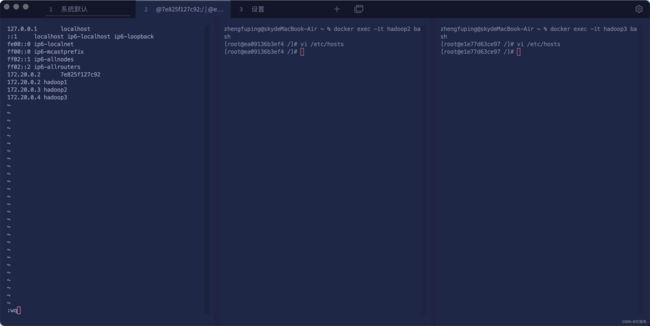
- 编辑文件
vi /etc/hosts
把端口以及名称映射放入该文件内,需要放自己生成的hadoop-br的网络
#这个是我的
172.20.0.2 hadoop1
172.20.0.3 hadoop2
172.20.0.4 hadoop3
- 配置免密登录
前面镜像中已经安装了ssh服务,所以直接分别在每台机器上执行以下命令:
ssh-keygen
一路回车
ssh-copy-id -i /root/.ssh/id_rsa -p 22 root@hadoop1
输入密码,如果按我的来得话就是123456
ssh-copy-id -i /root/.ssh/id_rsa -p 22 root@hadoop2
输入密码,如果按我的来得话就是123456
ssh-copy-id -i /root/.ssh/id_rsa -p 22 root@hadoop3
输入密码,如果按我的来得话就是123456
3.3、查看是否成功
ping hadoop1
ping hadoop2
ping hadoop3
ssh hadoop1
ssh hadoop2
ssh hadoop3
如果都可以正常ping通和切换则代表成功

4、安装配置Hadoop
4.1、添加存储文件夹
-
进入容器hadoop1
最好重写进入一下,要不然可能会没有hadoop文件
docker exec -it hadoop1 bash -
创建一些文件夹,用于存储hadoop运行时时产生文件的存储
mkdir /home/hadoop
mkdir /home/hadoop/tmp /home/hadoop/hdfs_name /home/hadoop/hdfs_data
4.2、添加指定配置
都添加在
- 编辑core-site.xml:
vi core-site.xml
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoop1:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>file:/home/hadoop/tmpvalue>
property>
<property>
<name>io.file.buffer.sizename>
<value>131702value>
property>
- 编辑hdfs-site.xml:
vi hdfs-site.xml
<property>
<name>dfs.namenode.name.dirname>
<value>file:/home/hadoop/hdfs_namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/home/hadoop/hdfs_datavalue>
property>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>hadoop1:9001value>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
- 编辑mapred-site.xml:
该文件部分版本没有,是因为被加了后缀先执行
cp mapred-site.xml.template mapred-site.xml
在去编辑,如果有的就直接编辑就行
vi mapred-site.xml
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>hadoop1:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>hadoop1:19888value>
property>
- 编辑yarn-site.xml:
vi yarn-site.xml
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>hadoop1:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>hadoop1:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>hadoop1:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>hadoop1:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>hadoop1:8088value>
property>
- 编辑slaves文件
hadoop1
hadoop2
hadoop3
4.3、同步数据
同步拷贝数据到hadoop2、hadoop3
依次执行以下命令:
scp -r $HADOOP_HOME/ hadoop2:/usr/local/
scp -r $HADOOP_HOME/ hadoop3:/usr/local/
scp -r /home/hadoop hadoop2:/
scp -r /home/hadoop hadoop3:/
5、测试启动
5.1、启动配置
- 分别重新连接每台机器
docker exec -it hadoop1 bash
docker exec -it hadoop2 bash
docker exec -it hadoop3 bash
- 分别给每台机器配置hadoop sbin目录的环境变量,jdk的也追加一下,要不然可能报错
vi ~/.bashrc或者vi ~/.bash_profile
追加
export PATH=$PATH:$HADOOP_HOME/sbin
export JAVA_HOME=/usr/local/jdk1.8
export PATH=$PATH:$JAVA_HOME/bin
- 执行
source ~/.bashrc
5.2、启动hadoop
- 格式化hdfs
hdfs namenode -format
执行一下jps,这个时候应该是只有一个启动的(如果这个命令不行就说明jdk路径压根没配置正确)
- 一键启动
start-all.sh

这个时候如果爆上面的错误,原因是 hadoop-env.sh文件,无法通过标签去读取到jdk的地址
-
修改全部主机的hadoop-env.sh文件
这个时候需要先
cd $HADOOP_HOME/etc/hadoop
去修改
vi hadoop-env.sh文件
找到下面截图的这个位置把地址修改为jdk的实际安装路径,不要是{}的,路径是前面配置的Dockerfile文件时配置的路径

然后在继续执行start-all.sh启动命令,可以通过jps命令看端口是不是变多了,如下应该就是成功啦

-
最后在到映射出来的web路径去查看