深度学习车道线检测
以前简单看过车道线检测思路,现在看到比较详细文章,以后系统学习。
深度学习检测车道线(一)
-
Opencv4图像分割和识别实战课程-车道线检测相关理论知识点-计算机...
第九章:车道线检测 1. 车道线检测相关理论知识点 [ 27:19 ]
最近在用深度学习的方法进行车道线检测,现总结如下:
目前,对于车道线检测的方法主要分为两大类,一是基于传统机器视觉的方法,二是基于深度学习大方法。
一、基于传统机器视觉的方法
1. 边缘检测+霍夫变换
方法流程:彩色图像转灰度,模糊处理,边缘检测,霍夫变换
这种方法一般能够检测出简单场景下的车辆目前行驶的两条车道线,以及偶尔的相邻车道(依赖前视相机的角度)。该方法可以利用霍夫变换的结果(线的斜率),进一步过滤出左右车道线。不过同时,该方法也依赖于边缘检测的结果,所以调参(边缘检测、霍夫变换)以及其他的trick(roi选取等等)是很重要的。
2. 颜色阈值
方法流程:将图像转颜色空间(一般HSV),对新的color space中的各个通道设置阈值(大于阈值取值为1,小于取值为0),得到结果。
该方法依赖于各通道的阈值的选取,只需要调整几个阈值参数,但个人认为该方法鲁棒性会较差,例如当前车辆前方的车辆可能会被全部置1。
3. 透视变换
方法流程:获取透视变换矩阵,透视变换,车道线检测(1或者2)
该方法的优点是将前视摄像头抓拍的图像转为鸟瞰图,能够检测到多条线。其关键在于透视变换矩阵的准确性(不考虑转换后的车道线检测),对于转换后的鸟瞰图,可以通过上述两种方式检测车道线。
在实际场景中,传统方法的鲁棒性确实不行,除去光照和邻近车辆的影响外,车道中间的指示箭头和人行道也是此类算法很难处理的挑战。
上述方法的总结建议参考该博文
二、基于深度学习的方法
小编主要讲的是如何通过训练一个深度神经网络对车道线进行语义分割,从而实现车道线检测。SegNet网络是一种很有趣的图像分割技术,是一种encoding-decoding的结构,在使用时可直接调用标准的模型结构。小编训练的网络便是基于SegNet网络构建的。
初始的网络结构如下图: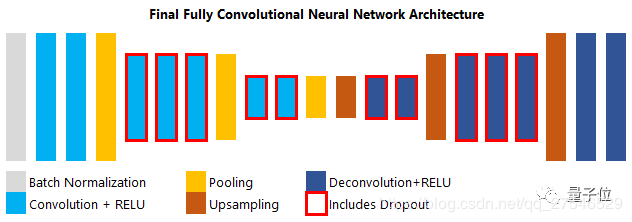
1.数据集
原图:
分割图(label):
原图点此处下载(https://www.dropbox.com/s/rrh8lrdclzlnxzv/full_CNN_train.p?dl=0)
数据集labels点此处下载(https://www.dropbox.com/s/ak850zqqfy6ily0/full_CNN_labels.p?dl=0)
初版的网络model如下:
""" This file contains code for a fully convolutional
(i.e. contains zero fully connected layers) neural network
for detecting lanes. This version assumes the inputs
to be road images in the shape of 80 x 160 x 3 (RGB) with
the labels as 80 x 160 x 1 (just the G channel with a
re-drawn lane). Note that in order to view a returned image,
the predictions is later stacked with zero'ed R and B layers
and added back to the initial road image.
"""
import numpy as np
import pickle
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
# Import necessary items from Keras
from keras.models import Sequential
from keras.layers import Activation, Dropout, UpSampling2D, concatenate
from keras.layers import Conv2DTranspose, Conv2D, MaxPooling2D
from keras.layers.normalization import BatchNormalization
from keras.preprocessing.image import ImageDataGenerator
from keras import regularizers
# Load training images
train_images = pickle.load(open("full_CNN_train.p", "rb" ))
# Load image labels
labels = pickle.load(open("full_CNN_labels.p", "rb" ))
# Make into arrays as the neural network wants these
train_images = np.array(train_images)
labels = np.array(labels)
# Normalize labels - training images get normalized to start in the network
labels = labels / 255
# Shuffle images along with their labels, then split into training/validation sets
train_images, labels = shuffle(train_images, labels)
# Test size may be 10% or 20%
X_train, X_val, y_train, y_val = train_test_split(train_images, labels, test_size=0.1)
# Batch size, epochs and pool size below are all paramaters to fiddle with for optimization
batch_size = 16
epochs = 10
pool_size = (2, 2)
input_shape = X_train.shape[1:]
### Here is the actual neural network ###
model = Sequential()
# Normalizes incoming inputs. First layer needs the input shape to work
model.add(BatchNormalization(input_shape=input_shape))
# Below layers were re-named for easier reading of model summary; this not necessary
# Conv Layer 1
model.add(Conv2D(8, (3, 3), padding='valid', strides=(1,1), activation = 'relu', name = 'Conv1'))
# Conv Layer 2
model.add(Conv2D(16, (3, 3), padding='valid', strides=(1,1), activation = 'relu', name = 'Conv2'))
# Pooling 1
model.add(MaxPooling2D(pool_size=pool_size))
# Conv Layer 3
model.add(Conv2D(16, (3, 3), padding='valid', strides=(1,1), activation = 'relu', name = 'Conv3'))
model.add(Dropout(0.2))
# Conv Layer 4
model.add(Conv2D(32, (3, 3), padding='valid', strides=(1,1), activation = 'relu', name = 'Conv4'))
model.add(Dropout(0.2))
# Conv Layer 5
model.add(Conv2D(32, (3, 3), padding='valid', strides=(1,1), activation = 'relu', name = 'Conv5'))
model.add(Dropout(0.2))
# Pooling 2
model.add(MaxPooling2D(pool_size=pool_size))
# Conv Layer 6
model.add(Conv2D(64, (3, 3), padding='valid', strides=(1,1), activation = 'relu', name = 'Conv6'))
model.add(Dropout(0.2))
# Conv Layer 7
model.add(Conv2D(64, (3, 3), padding='valid', strides=(1,1), activation = 'relu', name = 'Conv7'))
model.add(Dropout(0.2))
# Pooling 3
model.add(MaxPooling2D(pool_size=pool_size))
# Upsample 1
model.add(UpSampling2D(size=pool_size))
# Deconv 1
model.add(Conv2DTranspose(64, (3, 3), padding='valid', strides=(1,1), activation = 'relu', name = 'Deconv1'))
model.add(Dropout(0.2))
# Deconv 2
model.add(Conv2DTranspose(64, (3, 3), padding='valid', strides=(1,1), activation = 'relu', name = 'Deconv2'))
model.add(Dropout(0.2))
# Upsample 2
model.add(UpSampling2D(size=pool_size))
# Deconv 3
model.add(Conv2DTranspose(32, (3, 3), padding='valid', strides=(1,1), activation = 'relu', name = 'Deconv3'))
model.add(Dropout(0.2))
# Deconv 4
model.add(Conv2DTranspose(32, (3, 3), padding='valid', strides=(1,1), activation = 'relu', name = 'Deconv4'))
model.add(Dropout(0.2))
# Deconv 5
model.add(Conv2DTranspose(16, (3, 3), padding='valid', strides=(1,1), activation = 'relu', name = 'Deconv5'))
model.add(Dropout(0.2))
model.get_layer('Conv4')
# Upsample 3
model.add(UpSampling2D(size=pool_size))
# Deconv 6
model.add(Conv2DTranspose(16, (3, 3), padding='valid', strides=(1,1), activation = 'relu', name = 'Deconv6'))
# Final layer - only including one channel so 1 filter
model.add(Conv2DTranspose(1, (3, 3), padding='valid', strides=(1,1), activation = 'relu', name = 'Final'))
### End of network ###
# Using a generator to help the model use less data
# Channel shifts help with shadows slightly
datagen = ImageDataGenerator(channel_shift_range=0.2)
datagen.fit(X_train)
# Compiling and training the model
model.compile(optimizer='Adam', loss='mean_squared_error')
model.fit_generator(datagen.flow(X_train, y_train, batch_size=batch_size), steps_per_epoch=len(X_train)/batch_size,
epochs=epochs, verbose=1, validation_data=(X_val, y_val))
# Freeze layers since training is done
model.trainable = False
model.compile(optimizer='Adam', loss='mean_squared_error')
# Save model architecture and weights
model.save('full_CNN_model.h5')
# Show summary of model
model.summary()
上述model的建立参考链接(https://github.com/mvirgo/MLND-Capstone)
三、改进网络的model
上述的网络model在车道线检测的时候效果并不稳定,所以对其进行了改进。
1.增加了网络的层数,修改了每层卷积核的个数。
2.受Unet网络的启发,采用并联跳跃结构将encoding的feature map 与 decoding的feature map进行连接,这样可以在进行分类预测时利用多层信息。
3.将UpSampling2D改为Conv2DTranspose实现上采样的过程,UpSampling2D直接采用原像素值进行填补不存在学习的过程,而Conv2DTranspose存在学习的过程,效果更好。
训练
改进后的网络model如下:
import numpy as np
import pickle
#import cv2
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
# Import necessary items from Keras
from keras.models import Model
from keras.layers import Activation, Dropout, UpSampling2D, concatenate, Input
from keras.layers import Conv2DTranspose, Conv2D, MaxPooling2D
from keras.layers.normalization import BatchNormalization
from keras.preprocessing.image import ImageDataGenerator
from keras.utils import plot_model
from keras import regularizers
# Load training images
train_images = pickle.load(open("full_CNN_train.p", "rb" ))
# Load image labels
labels = pickle.load(open("full_CNN_labels.p", "rb" ))
# Make into arrays as the neural network wants these
train_images = np.array(train_images)
labels = np.array(labels)
# Normalize labels - training images get normalized to start in the network
labels = labels / 255
# Shuffle images along with their labels, then split into training/validation sets
train_images, labels = shuffle(train_images, labels)
# Test size may be 10% or 20%
X_train, X_val, y_train, y_val = train_test_split(train_images, labels, test_size=0.1)
# Batch size, epochs and pool size below are all paramaters to fiddle with for optimization
batch_size = 16
epochs = 15
pool_size = (2, 2)
#input_shape = X_train.shape[1:]
### Here is the actual neural network ###
# Normalizes incoming inputs. First layer needs the input shape to work
#BatchNormalization(input_shape=input_shape)
Inputs = Input(batch_shape=(None, 80, 160, 3))
# Below layers were re-named for easier reading of model summary; this not necessary
# Conv Layer 1
Conv1 = Conv2D(16, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Inputs)
Bat1 = BatchNormalization()(Conv1)
# Conv Layer 2
Conv2 = Conv2D(16, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Conv1)
Bat2 = BatchNormalization()(Conv2)
# Pooling 1
Pool1 = MaxPooling2D(pool_size=pool_size)(Conv2)
# Conv Layer 3
Conv3 = Conv2D(32, (3, 3), padding = 'valid', strides=(1,1), activation = 'relu')(Pool1)
#Drop3 = Dropout(0.2)(Conv3)
Bat3 = BatchNormalization()(Conv3)
# Conv Layer 4
Conv4 = Conv2D(32, (3, 3), padding = 'valid', strides=(1,1), activation = 'relu')(Bat3)
#Drop4 = Dropout(0.5)(Conv4)
Bat4 = BatchNormalization()(Conv4)
# Conv Layer 5
Conv5 = Conv2D(32, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Bat4)
#Drop5 = Dropout(0.2)(Conv5)
Bat5 = BatchNormalization()(Conv5)
# Pooling 2
Pool2 = MaxPooling2D(pool_size=pool_size)(Bat5)
# Conv Layer 6
Conv6 = Conv2D(64, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Pool2)
#Drop6 = Dropout(0.2)(Conv6)
Bat6 = BatchNormalization()(Conv6)
# Conv Layer 7
Conv7 = Conv2D(64, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Bat6)
#Drop7 = Dropout(0.2)(Conv7)
Bat7 = BatchNormalization()(Conv7)
# Pooling 3
Pool3 = MaxPooling2D(pool_size=pool_size)(Bat7)
# Conv Layer 8
Conv8 = Conv2D(128, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Pool3)
#Drop8 = Dropout(0.2)(Conv8)
Bat8 = BatchNormalization()(Conv8)
# Conv Layer 9
Conv9 = Conv2D(128, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Bat8)
#Drop9 = Dropout(0.2)(Conv9)
Bat9 = BatchNormalization()(Conv9)
# Pooling 4
Pool4 = MaxPooling2D(pool_size=pool_size)(Bat9)
# Upsample 1 to Deconv 1
Deconv1 = Conv2DTranspose(128, (2, 2), padding='valid', strides=(2,2), activation = 'relu')(Pool4)
#Up1 = UpSampling2D(size=pool_size)(Pool4)
Mer1 = concatenate([Deconv1, Bat9], axis=-1)
# Deconv 2
Deconv2 = Conv2DTranspose(128, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Mer1)
DBat2 = BatchNormalization()(Deconv2)
# Deconv 3
Deconv3 = Conv2DTranspose(64, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(DBat2)
DBat3 = BatchNormalization()(Deconv3)
# Upsample 2 to Deconv 4
Deconv4 = Conv2DTranspose(64, (2, 2), padding='valid', strides=(2,2), activation = 'relu')(DBat3)
#Up2 = UpSampling2D(size=pool_size)(DBat2)
Mer2 = concatenate([Deconv4, Bat7], axis=-1)
# Deconv 5
Deconv5 = Conv2DTranspose(64, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Mer2)
DBat5 = BatchNormalization()(Deconv5)
# Deconv 6
Deconv6 = Conv2DTranspose(32, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(DBat5)
DBat6 = BatchNormalization()(Deconv6)
# Upsample 3 to Deconv 7
Deconv7 = Conv2DTranspose(32, (2, 2), padding='valid', strides=(2,2), activation = 'relu')(DBat6)
#Up3 = UpSampling2D(size=pool_size)(DBat4)
Mer3 = concatenate([Deconv7, Bat5], axis=-1)
# Deconv 8
Deconv8 = Conv2DTranspose(32, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Mer3)
DBat8 = BatchNormalization()(Deconv8)
# Deconv 9
Deconv9 = Conv2DTranspose(16, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(DBat8)
DBat9 = BatchNormalization()(Deconv9)
# Deconv 10
Deconv10 = Conv2DTranspose(16, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(DBat9)
DBat10 = BatchNormalization()(Deconv10)
# Upsample 4 to Deconv 11
Deconv11 = Conv2DTranspose(16, (2, 2), padding='valid', strides=(2,2), activation = 'relu')(DBat10)
#Up4 = UpSampling2D(size=pool_size)(DBat7)
Mer4 = concatenate([Deconv11, Bat2], axis=-1)
# Deconv 12
Deconv12 = Conv2DTranspose(16, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Mer4)
DBat12 = BatchNormalization()(Deconv12)
# Deconv 13
Deconv13 = Conv2DTranspose(8, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(DBat12)
DBat13 = BatchNormalization()(Deconv13)
# Final layer - only including one channel so 1 filter
Final = Conv2DTranspose(1, (3, 3), padding='same', strides=(1,1), activation = 'relu')(DBat13)
### End of network ###
model = Model(inputs=Inputs, outputs=Final)
# Using a generator to help the model use less data
# Channel shifts help with shadows slightly
datagen = ImageDataGenerator(channel_shift_range=0.2)
datagen.fit(X_train)
# Compiling and training the model
model.compile(optimizer='Adam', loss='mean_squared_error')
model.fit_generator(datagen.flow(X_train, y_train, batch_size=batch_size), steps_per_epoch=len(X_train)/batch_size,
epochs=epochs, verbose=1, validation_data=(X_val, y_val))
# Freeze layers since training is done
model.trainable = False
model.compile(optimizer='Adam', loss='mean_squared_error')
# Save model architecture and weights
model.save('full_CNN_model_HYe15.h5')
# Show summary of model
model.summary()
plot_model(model, to_file='model.png')
测试
将网络model训练好以后,进行测试,每帧图像的检测结果是其前5帧图像检测结果的平均。
import numpy as np
import cv2
from scipy.misc import imresize
from moviepy.editor import VideoFileClip
from IPython.display import HTML
from keras.models import load_model
import matplotlib.pyplot as plt
# Load Keras model
model = load_model('full_CNN_model_HY.h5')
# Class to average lanes with
class Lanes():
def __init__(self):
self.recent_fit = []
self.avg_fit = []
def road_lines(image):
""" Takes in a road image, re-sizes for the model,
predicts the lane to be drawn from the model in G color,
recreates an RGB image of a lane and merges with the
original road image.
"""
# Get image ready for feeding into model
small_img = imresize(image, (80, 160, 3))
small_img = np.array(small_img)
small_img = small_img[None,:,:,:]
# Make prediction with neural network (un-normalize value by multiplying by 255)
prediction = model.predict(small_img)[0] * 255
# Add lane prediction to list for averaging
lanes.recent_fit.append(prediction)
# Only using last five for average
if len(lanes.recent_fit) > 5:
lanes.recent_fit = lanes.recent_fit[1:]
# Calculate average detection
lanes.avg_fit = np.mean(np.array([i for i in lanes.recent_fit]), axis = 0)
# Generate fake R & B color dimensions, stack with G
blanks = np.zeros_like(lanes.avg_fit).astype(np.uint8)
lane_drawn = np.dstack((blanks, lanes.avg_fit, blanks))
# Re-size to match the original image
lane_image = imresize(lane_drawn, (720, 1280, 3))
#plt.imshow(lane_image)
#plt.show()
# Merge the lane drawing onto the original image
result = cv2.addWeighted(image, 1, lane_image, 1, 0)
return result
lanes = Lanes()
# Where to save the output video
vid_output = 'project_video_hy.mp4'
# Location of the input video
clip1 = VideoFileClip("project_video.mp4")
vid_clip = clip1.fl_image(road_lines)
vid_clip.write_videofile(vid_output, audio=False)
测试结果
测试结果还可以,之后将继续研究利用深度学习对多个车道进行检测,未完待续。。。。。。
深度学习车道线检测 相关内容
深度学习中文ocr 深度学习里的神经网络 深度学习算法数学推导 深度学习图像动漫化 深度学习工具作用 数据扩展 深度学习 深度学习中的可视化 中文标签 深度学习 深度学习论文笔记 深度学习图像分类论文 java实现变声效果---萝莉、大叔、肥仔、搞怪、慢吞吞、网红女、困兽 CSDN测试课程 前端小白入门必修-小米商城开发实战(下)
原
基于深度学习的车道线检测网络
深度学习的车道线检测网络
一.分割模型
1. SCNN,Github,TuSimple Benchmark lane Detection challenge获得了第一名,准确率为96.53%,结合车道线特征提出的专门的分割模型,主要贡献点是spati cnn结构的提出,这个结构主要适用于条状目标的检测例如车道线,电线,电线杆等。
2. LaneNet ,Github 该算法在图森的车道线数据集上的准确率为96.4%,在NVIDIA 1080 TI上的处理速度为52FPS。 多任务的车道线检测模型 一个分支学习一个中间层的特征图用于统计车道线数目,一个分支去分割车道线(二分类,相比于多分类这里参数少了,计算量小了,准确率高了),结合两个分支,利用聚类计算车道线的数量,最终实现车道线的实例分割,最终通过HNet学习透视矩阵参数去实现车道线的拟合
3.ENet-SAD ,Github 自注意力蒸馏分割网络,主干网络采用ENet 在E2-E4模块加上SAD模块去产生一个注意力特征图,利用loss去缩小相邻模块之间的差距,从而让网络能够实现低层模仿高层学习,加快网络的收敛速度。比SCNN参数少20倍,快10倍
二.目标检测模型
Vpgnet ,Github 多任务的车道线检测,有目标检测任务 ,分割任务,以及坐标点回归任务相结合,实现车道线的检测。
深度学习方法实现车道线分割之二(自动驾驶车道线分割)
1 原理
之前我曾采用传统方法实现了一下车道线检测,
https://blog.csdn.net/xiao__run/article/details/82746319
车道线检测是无人车系统里感知模块的重要组成部分。利用视觉算法的车道线检测解决方案是一种较为常见解决方案。视觉检测方案主要基于图像算法,检测出图片中行车道路的车道线标志区域。
高速公路上的车道线检测是一项具有挑战性的任务,由于车道线标志的种类繁多,车辆拥挤造成车道线标志区域被遮挡,车道线可能有腐蚀磨损的情况,以及天气等因素都能给车道线检测任务带来不小的挑战。过去,大部分车道线检测算法基本是通过卷积滤波方法,识别分割出车道线区域,然后结合霍夫变换、RANSAC等算法进行车道线检测,这类算法需要人工手动去调滤波算子,根据算法所针对的街道场景特点手动调节参数,工作量大且鲁棒性较差,当行车环境出现明显变化时,车道线的检测效果不佳。参考我的上一篇博文
https://blog.csdn.net/xiao__run/article/details/82746319
本文基于传统车道线检测算法,结合深度学习技术,提出了一种使用深度神经网络,代替传统算法中手动调滤波算子,对高速公路上的车道线进行语义分割.基本结构就是采用segnet类似结构网络与分割车道线区间,基于fcn, segnet, Unet语义分割网络基本都是encoding,decoding结构,小编在特征选取上做了基本改进,效果还能看.
1 最后一层采用1个3x3的卷积核去回归.
2 采用adam去优化,
3 loss采用loss=‘mean_squared_error’
2 数据集样本
数据集如图所示 分割图
分割图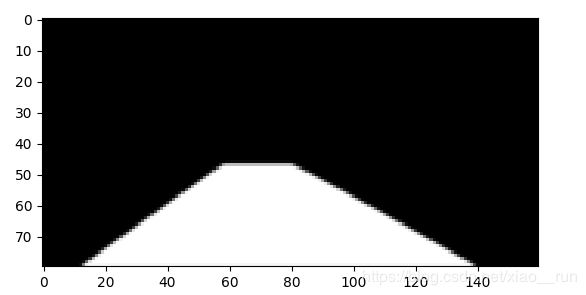
网络model如下:
""" This file contains code for a fully convolutional
(i.e. contains zero fully connected layers) neural network
for detecting lanes. This version assumes the inputs
to be road images in the shape of 80 x 160 x 3 (RGB) with
the labels as 80 x 160 x 1 (just the G channel with a
re-drawn lane). Note that in order to view a returned image,
the predictions is later stacked with zero'ed R and B layers
and added back to the initial road image.
"""python
import numpy as np
import pickle
import cv2
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
# Import necessary items from Keras
from keras.models import Model
from keras.layers import Activation, Dropout, UpSampling2D, concatenate, Input
from keras.layers import Conv2DTranspose, Conv2D, MaxPooling2D
from keras.layers.normalization import BatchNormalization
from keras.preprocessing.image import ImageDataGenerator
from keras.utils import plot_model
from keras import regularizers
# Load training images
train_images = pickle.load(open("full_CNN_train.p", "rb" ))
# Load image labels
labels = pickle.load(open("full_CNN_labels.p", "rb" ))
# Make into arrays as the neural network wants these
train_images = np.array(train_images)
labels = np.array(labels)
# Normalize labels - training images get normalized to start in the network
labels = labels / 255
# Shuffle images along with their labels, then split into training/validation sets
train_images, labels = shuffle(train_images, labels)
# Test size may be 10% or 20%
X_train, X_val, y_train, y_val = train_test_split(train_images, labels, test_size=0.1)
# Batch size, epochs and pool size below are all paramaters to fiddle with for optimization
batch_size = 16
epochs = 10
pool_size = (2, 2)
#input_shape = X_train.shape[1:]
### Here is the actual neural network ###
# Normalizes incoming inputs. First layer needs the input shape to work
#BatchNormalization(input_shape=input_shape)
Inputs = Input(batch_shape=(None, 80, 160, 3))
# Below layers were re-named for easier reading of model summary; this not necessary
# Conv Layer 1
Conv1 = Conv2D(16, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Inputs)
Bat1 = BatchNormalization()(Conv1)
# Conv Layer 2
Conv2 = Conv2D(16, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Conv1)
Bat2 = BatchNormalization()(Conv2)
# Pooling 1
Pool1 = MaxPooling2D(pool_size=pool_size)(Conv2)
# Conv Layer 3
Conv3 = Conv2D(32, (3, 3), padding = 'valid', strides=(1,1), activation = 'relu')(Pool1)
#Drop3 = Dropout(0.2)(Conv3)
Bat3 = BatchNormalization()(Conv3)
# Conv Layer 4
Conv4 = Conv2D(32, (3, 3), padding = 'valid', strides=(1,1), activation = 'relu')(Bat3)
#Drop4 = Dropout(0.5)(Conv4)
Bat4 = BatchNormalization()(Conv4)
# Conv Layer 5
Conv5 = Conv2D(32, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Bat4)
#Drop5 = Dropout(0.2)(Conv5)
Bat5 = BatchNormalization()(Conv5)
# Pooling 2
Pool2 = MaxPooling2D(pool_size=pool_size)(Bat5)
# Conv Layer 6
Conv6 = Conv2D(64, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Pool2)
#Drop6 = Dropout(0.2)(Conv6)
Bat6 = BatchNormalization()(Conv6)
# Conv Layer 7
Conv7 = Conv2D(64, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Bat6)
#Drop7 = Dropout(0.2)(Conv7)
Bat7 = BatchNormalization()(Conv7)
# Pooling 3
Pool3 = MaxPooling2D(pool_size=pool_size)(Bat7)
# Conv Layer 8
Conv8 = Conv2D(128, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Pool3)
#Drop8 = Dropout(0.2)(Conv8)
Bat8 = BatchNormalization()(Conv8)
# Conv Layer 9
Conv9 = Conv2D(128, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Bat8)
#Drop9 = Dropout(0.2)(Conv9)
Bat9 = BatchNormalization()(Conv9)
# Pooling 4
Pool4 = MaxPooling2D(pool_size=pool_size)(Bat9)
# Upsample 1
Up1 = UpSampling2D(size=pool_size)(Pool4)
Mer1 = concatenate([Up1, Bat9], axis=-1)
# Deconv 1
Deconv1 = Conv2DTranspose(128, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Mer1)
#DDrop1 = Dropout(0.2)(Deconv1)
DBat1 = BatchNormalization()(Deconv1)
# Deconv 2
Deconv2 = Conv2DTranspose(64, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(DBat1)
#DDrop2 = Dropout(0.2)(Deconv2)
DBat2 = BatchNormalization()(Deconv2)
# Upsample 2
Up2 = UpSampling2D(size=pool_size)(DBat2)
Mer2 = concatenate([Up2, Bat7], axis=-1)
# Deconv 3
Deconv3 = Conv2DTranspose(64, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Mer2)
#DDrop3 = Dropout(0.2)(Deconv3)
DBat3 = BatchNormalization()(Deconv3)
# Deconv 4
Deconv4 = Conv2DTranspose(32, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(DBat3)
#DDrop4 = Dropout(0.2)(Deconv4)
DBat4 = BatchNormalization()(Deconv4)
# Upsample 3
Up3 = UpSampling2D(size=pool_size)(DBat4)
Mer3 = concatenate([Up3, Bat5], axis=-1)
# Deconv 5
Deconv5 = Conv2DTranspose(32, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Mer3)
#DDrop5 = Dropout(0.2)(Deconv5)
DBat5 = BatchNormalization()(Deconv5)
# Deconv 6
Deconv6 = Conv2DTranspose(16, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(DBat5)
#DDrop6 = Dropout(0.2)(Deconv6)
DBat6 = BatchNormalization()(Deconv6)
# Deconv 7
Deconv7 = Conv2DTranspose(16, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(DBat6)
#DDrop7 = Dropout(0.2)(Deconv7)
DBat7 = BatchNormalization()(Deconv7)
# Upsample 4
Up4 = UpSampling2D(size=pool_size)(DBat7)
Mer4 = concatenate([Up4, Bat2], axis=-1)
# Deconv 8
Deconv8 = Conv2DTranspose(16, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Mer4)
#DDrop8 = Dropout(0.2)(Deconv8)
DBat8 = BatchNormalization()(Deconv8)
# Deconv 9
Deconv9 = Conv2DTranspose(8, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(DBat8)
#DDrop9 = Dropout(0.2)(Deconv9)
DBat9 = BatchNormalization()(Deconv9)
# Final layer - only including one channel so 1 filter
Final = Conv2DTranspose(1, (3, 3), padding='same', strides=(1,1), activation = 'relu')(DBat9)
### End of network ###
model = Model(inputs=Inputs, outputs=Final)
# Using a generator to help the model use less data
# Channel shifts help with shadows slightly
datagen = ImageDataGenerator(channel_shift_range=0.2)
datagen.fit(X_train)
# Compiling and training the model
model.compile(optimizer='Adam', loss='mean_squared_error')
model.fit_generator(datagen.flow(X_train, y_train, batch_size=batch_size), steps_per_epoch=len(X_train)/batch_size,
epochs=epochs, verbose=1, validation_data=(X_val, y_val))
# Freeze layers since training is done
model.trainable = False
model.compile(optimizer='Adam', loss='mean_squared_error')
# Save model architecture and weights
model.save('full_CNN_model.h5')
# Show summary of model
model.summary()
plot_model(model, to_file='model.png')
进一步改进
接下来我不是直接采用unsample,采用转置卷积进行上采样,同样进行一个多尺度特征融合
,训练代码如下:
""" This file contains code for a fully convolutional
(i.e. contains zero fully connected layers) neural network
for detecting lanes. This version assumes the inputs
to be road images in the shape of 80 x 160 x 3 (RGB) with
the labels as 80 x 160 x 1 (just the G channel with a
re-drawn lane). Note that in order to view a returned image,
the predictions is later stacked with zero'ed R and B layers
and added back to the initial road image.
"""
import numpy as np
import pickle
#import cv2
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
# Import necessary items from Keras
from keras.models import Model
from keras.layers import Activation, Dropout, UpSampling2D, concatenate, Input
from keras.layers import Conv2DTranspose, Conv2D, MaxPooling2D
from keras.layers.normalization import BatchNormalization
from keras.preprocessing.image import ImageDataGenerator
from keras.utils import plot_model
from keras import regularizers
# Load training images
train_images = pickle.load(open("full_CNN_train.p", "rb" ))
# Load image labels
labels = pickle.load(open("full_CNN_labels.p", "rb" ))
# Make into arrays as the neural network wants these
train_images = np.array(train_images)
labels = np.array(labels)
# Normalize labels - training images get normalized to start in the network
labels = labels / 255
# Shuffle images along with their labels, then split into training/validation sets
train_images, labels = shuffle(train_images, labels)
# Test size may be 10% or 20%
X_train, X_val, y_train, y_val = train_test_split(train_images, labels, test_size=0.1)
# Batch size, epochs and pool size below are all paramaters to fiddle with for optimization
batch_size = 16
epochs = 10
pool_size = (2, 2)
#input_shape = X_train.shape[1:]
### Here is the actual neural network ###
# Normalizes incoming inputs. First layer needs the input shape to work
#BatchNormalization(input_shape=input_shape)
Inputs = Input(batch_shape=(None, 80, 160, 3))
# Below layers were re-named for easier reading of model summary; this not necessary
# Conv Layer 1
Conv1 = Conv2D(16, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Inputs)
Bat1 = BatchNormalization()(Conv1)
# Conv Layer 2
Conv2 = Conv2D(16, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Conv1)
Bat2 = BatchNormalization()(Conv2)
# Pooling 1
Pool1 = MaxPooling2D(pool_size=pool_size)(Conv2)
# Conv Layer 3
Conv3 = Conv2D(32, (3, 3), padding = 'valid', strides=(1,1), activation = 'relu')(Pool1)
#Drop3 = Dropout(0.2)(Conv3)
Bat3 = BatchNormalization()(Conv3)
# Conv Layer 4
Conv4 = Conv2D(32, (3, 3), padding = 'valid', strides=(1,1), activation = 'relu')(Bat3)
#Drop4 = Dropout(0.5)(Conv4)
Bat4 = BatchNormalization()(Conv4)
# Conv Layer 5
Conv5 = Conv2D(32, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Bat4)
#Drop5 = Dropout(0.2)(Conv5)
Bat5 = BatchNormalization()(Conv5)
# Pooling 2
Pool2 = MaxPooling2D(pool_size=pool_size)(Bat5)
# Conv Layer 6
Conv6 = Conv2D(64, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Pool2)
#Drop6 = Dropout(0.2)(Conv6)
Bat6 = BatchNormalization()(Conv6)
# Conv Layer 7
Conv7 = Conv2D(64, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Bat6)
#Drop7 = Dropout(0.2)(Conv7)
Bat7 = BatchNormalization()(Conv7)
# Pooling 3
Pool3 = MaxPooling2D(pool_size=pool_size)(Bat7)
# Conv Layer 8
Conv8 = Conv2D(128, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Pool3)
#Drop8 = Dropout(0.2)(Conv8)
Bat8 = BatchNormalization()(Conv8)
# Conv Layer 9
Conv9 = Conv2D(128, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Bat8)
#Drop9 = Dropout(0.2)(Conv9)
Bat9 = BatchNormalization()(Conv9)
# Pooling 4
Pool4 = MaxPooling2D(pool_size=pool_size)(Bat9)
# Upsample 1 to Deconv 1
Deconv1 = Conv2DTranspose(128, (2, 2), padding='valid', strides=(2,2), activation = 'relu')(Pool4)
#Up1 = UpSampling2D(size=pool_size)(Pool4)
Mer1 = concatenate([Deconv1, Bat9], axis=-1)
# Deconv 2
Deconv2 = Conv2DTranspose(128, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Mer1)
DBat2 = BatchNormalization()(Deconv2)
# Deconv 3
Deconv3 = Conv2DTranspose(64, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(DBat2)
DBat3 = BatchNormalization()(Deconv3)
# Upsample 2 to Deconv 4
Deconv4 = Conv2DTranspose(64, (2, 2), padding='valid', strides=(2,2), activation = 'relu')(DBat3)
#Up2 = UpSampling2D(size=pool_size)(DBat2)
Mer2 = concatenate([Deconv4, Bat7], axis=-1)
# Deconv 5
Deconv5 = Conv2DTranspose(64, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Mer2)
DBat5 = BatchNormalization()(Deconv5)
# Deconv 6
Deconv6 = Conv2DTranspose(32, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(DBat5)
DBat6 = BatchNormalization()(Deconv6)
# Upsample 3 to Deconv 7
Deconv7 = Conv2DTranspose(32, (2, 2), padding='valid', strides=(2,2), activation = 'relu')(DBat6)
#Up3 = UpSampling2D(size=pool_size)(DBat4)
Mer3 = concatenate([Deconv7, Bat5], axis=-1)
# Deconv 8
Deconv8 = Conv2DTranspose(32, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Mer3)
DBat8 = BatchNormalization()(Deconv8)
# Deconv 9
Deconv9 = Conv2DTranspose(16, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(DBat8)
DBat9 = BatchNormalization()(Deconv9)
# Deconv 10
Deconv10 = Conv2DTranspose(16, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(DBat9)
DBat10 = BatchNormalization()(Deconv10)
# Upsample 4 to Deconv 11
Deconv11 = Conv2DTranspose(16, (2, 2), padding='valid', strides=(2,2), activation = 'relu')(DBat10)
#Up4 = UpSampling2D(size=pool_size)(DBat7)
Mer4 = concatenate([Deconv11, Bat2], axis=-1)
# Deconv 12
Deconv12 = Conv2DTranspose(16, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(Mer4)
DBat12 = BatchNormalization()(Deconv12)
# Deconv 13
Deconv13 = Conv2DTranspose(8, (3, 3), padding='valid', strides=(1,1), activation = 'relu')(DBat12)
DBat13 = BatchNormalization()(Deconv13)
# Final layer - only including one channel so 1 filter
Final = Conv2DTranspose(1, (3, 3), padding='same', strides=(1,1), activation = 'relu')(DBat13)
### End of network ###
model = Model(inputs=Inputs, outputs=Final)
# Using a generator to help the model use less data
# Channel shifts help with shadows slightly
datagen = ImageDataGenerator(channel_shift_range=0.2)
datagen.fit(X_train)
# Compiling and training the model
model.compile(optimizer='Adam', loss='mean_squared_error')
model.fit_generator(datagen.flow(X_train, y_train, batch_size=batch_size), steps_per_epoch=len(X_train)/batch_size,
epochs=epochs, verbose=1, validation_data=(X_val, y_val))
# Freeze layers since training is done
model.trainable = False
model.compile(optimizer='Adam', loss='mean_squared_error')
# Save model architecture and weights
model.save('full_CNN_model.h5')
# Show summary of model
model.summary()
plot_model(model, to_file='model.png')
测试
训练得到model之后,接下来我们用视频进行测试一下:
测试时采用连续5帧做的一个平均
import numpy as np
import cv2
from scipy.misc import imresize
from moviepy.editor import VideoFileClip
from IPython.display import HTML
from keras.models import load_model
import matplotlib.pyplot as plt
# Load Keras model
model = load_model('full_CNN_model.h5')
# Class to average lanes with
class Lanes():
def __init__(self):
self.recent_fit = []
self.avg_fit = []
def road_lines(image):
""" Takes in a road image, re-sizes for the model,
predicts the lane to be drawn from the model in G color,
recreates an RGB image of a lane and merges with the
original road image.
"""
# Get image ready for feeding into model
small_img = imresize(image, (80, 160, 3))
small_img = np.array(small_img)
small_img = small_img[None,:,:,:]
# Make prediction with neural network (un-normalize value by multiplying by 255)
prediction = model.predict(small_img)[0] * 255
# Add lane prediction to list for averaging
lanes.recent_fit.append(prediction)
# Only using last five for average
if len(lanes.recent_fit) > 5:
lanes.recent_fit = lanes.recent_fit[1:]
# Calculate average detection
lanes.avg_fit = np.mean(np.array([i for i in lanes.recent_fit]), axis = 0)
# Generate fake R & B color dimensions, stack with G
blanks = np.zeros_like(lanes.avg_fit).astype(np.uint8)
lane_drawn = np.dstack((blanks, lanes.avg_fit, blanks))
# Re-size to match the original image
lane_image = imresize(lane_drawn, (720, 1280, 3))
#plt.imshow(lane_image)
#plt.show()
# Merge the lane drawing onto the original image
result = cv2.addWeighted(image, 1, lane_image, 1, 0)
return result
lanes = Lanes()
# Where to save the output video
vid_output = 'harder_challenge.mp4'
clip1 = VideoFileClip("project_video.mp4")
vid_clip = clip1.fl_image(road_lines)
vid_clip.write_videofile(vid_output, audio=False)
结果
结果如图所示:
效果勉强还能看,后续我将会做进一步改进,例如使用E-Net网络加速,采用lanenet实例分割,聚类等算法训练图森的数据集,得到更加好的效果
背景
车道线检测作为自动驾驶领域的常规工作,在深度学习的浪潮中又有了很大的进步,在此分享我所做的调研工作,部分为ppt截图,为了方便请谅解。
https://github.com/soulmeetliang/Awesome-Lane-Detection
- [论文极简笔记]SCNN-Spatial As Deep: Spatial CNN for Traffic Scene Understanding
- [论文极简笔记] Towards End-to-End Lane Detection: an Instance Segmentation Approach
- [论文极简笔记] LineNet: a Zoomable CNN for Crowdsourced High Definition Maps Modeling in Urban Environm
- [论文极简笔记] Robust Lane Detection from Continuous Driving Scenes Using Deep Neural Networks
车道线检测工作的局限性
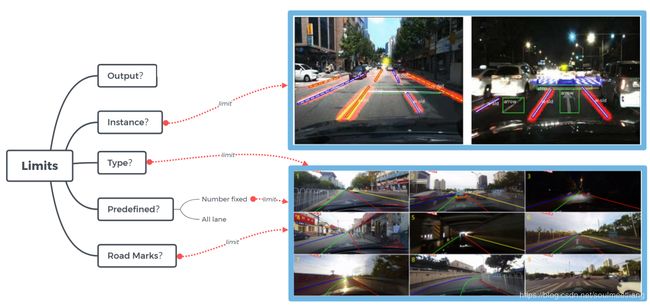 如上图所示,车道线检测工作的baseline并不明确,不同的方法与不同的场景应用都有各自的局限性。例如:
如上图所示,车道线检测工作的baseline并不明确,不同的方法与不同的场景应用都有各自的局限性。例如:
- 输出类型:mask掩码/点集/矢量线条
- 实例化:每个车道线是否形成实例
- 分类:是否对车道线进行了分类(单白、双黄等)
- 提前定义的参数:是否只能检测固定数量的车道线
- 车道标记:是否对车道上的行车标记也做了检测
性能指标
 如上图所示,在评判ture or false时,主要有两种方式:
如上图所示,在评判ture or false时,主要有两种方式:
- end point,通过判断线的端点间的距离及其包围面积是否超过阈值
- IOU,直接计算IOU的重叠面积
工作pipeline

如上图所示,目前的主流方法pipeline分为多阶段与单阶段。
- 多阶段可以分为两个部分,二值语义分割产生掩码图和对掩码图进行线的拟合。其中,二值语义分割主要采用CNN方法,并通过SCNN(Spatial As Deep: Spatial CNN for Traffic Scene Understanding)、CNN+RNN(Robust Lane Detection from Continuous Driving Scenes Using Deep Neural Networks
)、GAN(EL-GAN:Embedding Loss Driven Generateive Adversarial Networks for Lane Detection)等方法来提高语义分割精度。
而对掩码图的线的拟合,有采用学习到的转换矩阵先将分割结果转换为鸟瞰图视角,然后,采用均匀取点+最小二乘法拟合,拟合方程可选三次方程。 - 对于单阶段方法,即是直接回归出线的参数,即在CNN上修改分支,使用特殊层将参数输出。
数据集

传统方法

近三年的部分工作(基于深度学习)

引用github项目 awesome-lane-detection
Paper
2019
《Robust Lane Detection from Continuous Driving Scenes Using Deep Neural Networks》
《End-to-end Lane Detection through Differentiable Least-Squares Fitting》 github
2018
《End to End Video Segmentation for Driving : Lane Detection For Autonomous Car》
《3D-LaneNet: end-to-end 3D multiple lane detection》
《Efficient Road Lane Marking Detection with Deep Learning》 DSP 2018
《Multiple Lane Detection Algorithm Based on Optimised Dense Disparity Map Estimation》 IST 2018
《LineNet: a Zoomable CNN for Crowdsourced High Definition Maps Modeling in Urban Environments》
《Real-time stereo vision-based lane detection system》
《LaneNet: Real-Time Lane Detection Networks for Autonomous Driving》
《EL-GAN: Embedding Loss Driven Generative Adversarial Networks for Lane Detection》
《Real-time Lane Marker Detection Using Template Matching with RGB-D Camera》
《Towards End-to-End Lane Detection: an Instance Segmentation Approach》 论文解读 github
《Lane Detection and Classification for Forward Collision Warning System Based on Stereo Vision》
《Advances in Vision-Based Lane Detection: Algorithms, Integration, Assessment, and Perspectives on ACP-Based Parallel Vision》
《(SCNN)Spatial As Deep: Spatial CNN for Traffic Scene Understanding》 AAAI 2018 CSDN Translator
《Lane Detection Based on Inverse Perspective Transformation and Kalman Filter》
2017
《A review of recent advances in lane detection and departure warning system》
《Deep Learning Lane Marker Segmentation From Automatically Generated Labels》 Youtube
VPGNet: Vanishing Point Guided Network for Lane and Road Marking Detection and Recognition ICCV 2017 github
Code
https://github.com/wvangansbeke/LaneDetection_End2End
https://github.com/georgesung/advanced_lane_detection
https://github.com/MaybeShewill-CV/lanenet-lane-detection
https://github.com/XingangPan/SCNN
https://github.com/davidawad/Lane-Detection
https://github.com/yang1688899/CarND-Advanced-Lane-Lines
https://github.com/SeokjuLee/VPGNet
https://github.com/mvirgo/MLND-Capstone:Lane Detection with Deep Learning
https://github.com/galenballew/SDC-Lane-and-Vehicle-Detection-Tracking
https://github.com/shawshany/Advance_LaneFinding
Blog
Lane Detection with Deep Learning (Part 1)
Simple Lane Detection with OpenCV
Building a lane detection system using Python 3 and OpenCV
Datasets
tusimple.ai
A Dataset for Lane Instance Segmentation in Urban Environments
论文介绍
后面会各开一篇详细介绍
Spatial As Deep: Spatial CNN for Traffic Scene Understanding
Abstract
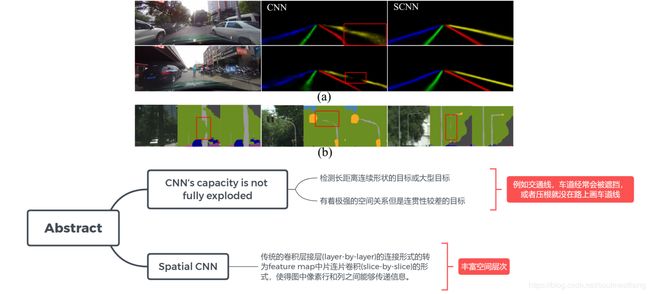
Towards End-to-End Lane Detection: an Instance Segmentation Approach
Abstract

LineNet: a Zoomable CNN for Crowdsourced High Definition Maps Modeling in Urban Environments
Abstract

Robust Lane Detection from Continuous Driving Scenes Using Deep Neural Networks
Abstract
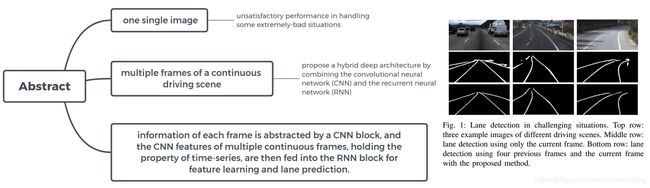
深度学习笔记(十二)车道线检测 LaneNet
论文:Towards End-to-End Lane Detection: an Instance Segmentation Approach
代码:https://github.com/MaybeShewill-CV/lanenet-lane-detection
参考:车道线检测算法LaneNet + H-Net(论文解读)
数据集:Tusimple
Overview
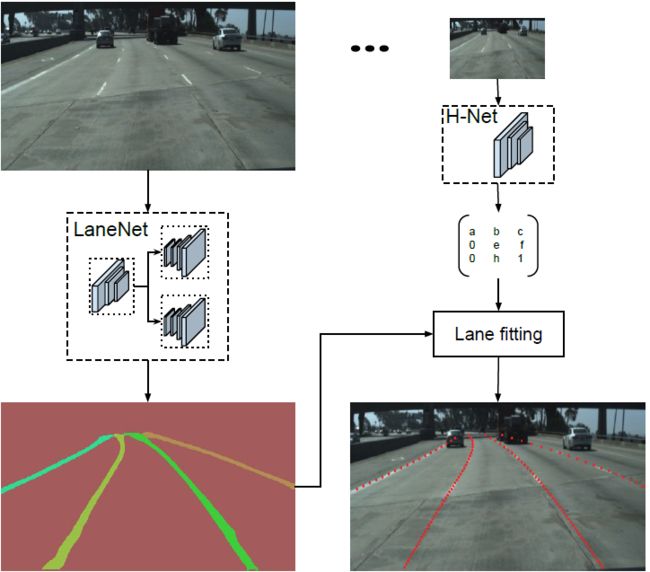
本文提出一种端到端的车道线检测算法,包含 LanNet + H-Net 两个网络模型。其中 LanNet 是一种将语义分割和对像素进行向量表示结合起来的多任务模型,最后利用聚类完成对车道线的实例分割。H-Net 是有个小的网络结构,负责预测变换矩阵 H,使用转换矩阵 H 对同属一条车道线的所有像素点进行重新建模(使用 y 坐标来表示 x 坐标)。
LaneNet
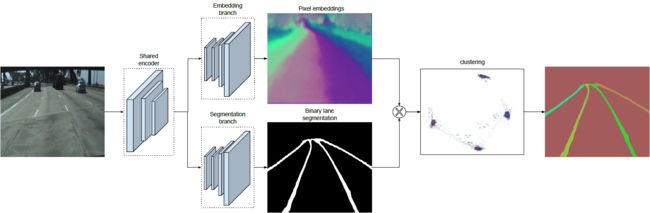
论文中将实例分割任务拆解成语义分割(LanNet 一个分支)和聚类(LanNet一个分支提取 embedding express, Mean-Shift 聚类)两部分。如上图所示,LanNet 有两个分支任务,分别为 a lane segmentation branch and a lane embedding branch。Segmentation branch负责对输入图像进行语义分割(对像素进行二分类,判断像素属于车道线还是背景);Embedding branch对像素进行嵌入式表示,训练得到的embedding向量用于聚类。最后将两个分支的结果进行结合利用 Mean-Shift 算法进行聚类,得到实例分割的结果。
语义分割
在设计语义分割模型时,论文主要考虑了以下两个方面:
1.在构建label时,为了处理遮挡问题,论文对被车辆遮挡的车道线和虚线进行了还原;
2. Loss使用交叉熵,为了解决样本分布不均衡的问题(属于车道线的像素远少于属于背景的像素),参考论文ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation ,使用了boundedinverse class weight对loss进行加权:
$W_{class} = \frac{1}{ln(c+p_(class))}$
其中,p 为对应类别在总体样本中出现的概率,c 是超参数(ENet论文中是1.02,使得权重的取值区间为[1,50])。
实例分割
为了区分车道线上的像素属于哪条车道,embedding_branch 为每个像素初始化一个 embedding 向量,并且在设计 loss 时,使属同一条车道线的像素向量距离很小,属不同车道线的像素向量距离很大。
这部分的loss函数是由两部分组成:方差loss($L_{var}$)和距离loss($L_{dist}$):
$L_{var} = \frac{1}{C} \sum_{c=1}^{C} \frac{1}{N_c} [\Arrowvert \mu_c-x_i \Arrowvert -\delta_v]_{+}^{2}$
$L_{dist} = \frac{1}{C(C-1)} \sum_{c_A=1}^{C} \sum_{c_B=1, c_A \ne C_B}^{C} [\delta_d - \Arrowvert \mu_{c_A} - \mu_{c_B} \Arrowvert ]_{+}^{2}$
其中,C 是车道线数量,$N_c$ 是属同一条车道线的像素点数量,$\mu_c$ 是车道线的均值向量,$x_i$ 是像素向量(pixel embedding),$[x]_+ = max(0, x)$。
该 loss 函数源自于论文 《Semantic Instance Segmentation with a Discriminative loss function》 ,该论文中还有一个正则项,本文没有用:
$L_{reg} = \frac{1}{C} \sum_{c=1}^{C} \Arrowvert \mu_c \Arrowvert $
同一车道线的像素向量,距离车道线均值向量 $\mu_c$ 超过 $\delta_v$ 时, pull force($L_{var}$) 才有意义,使得 $x_i$ 靠近 $\delta_d$;
不同车道线的均值向量 $\mu_{c_A}$ 和 $\mu_{c_B}$ 之间距离小于 $\delta_d$ 时,push force($L_{dist}$) 才有意义,使得 $\mu_{c_A}$ 和 $\mu_{c_B}$ 彼此远离。
聚类
注意,聚类可以看做是个后处理,上一步里 embedding_branch 已经为聚类提供好的特征向量了,利用这些特征向量我们可以利用任意聚类算法来完成实例分割的目标。
为了方便聚类,论文中设定 $\delta_d > 6\delta_v$。
在进行聚类时,首先使用 mean shift 聚类,使得簇中心沿着密度上升的方向移动,防止将离群点选入相同的簇中;之后对像素向量进行划分:以簇中心为圆心,以 $2\delta_v$ 为半径,选取圆中所有的像素归为同一车道线。重复该步骤,直到将所有的车道线像素分配给对应的车道。
网络结构
LaneNet是基于ENet 的encoder-decoder模型,如图5所示,ENet由5个stage组成,其中stage2和stage3基本相同,stage1,2,3属于encoder,stage4,5属于decoder。
如上图所示,在LaneNet 中,语义分割和实例分割两个任务共享 stage1 和 stage2,并将 stage3 和后面的 decoder 层作为各自的分支(branch)进行训练;其中,语义分割分支(branch)的输出 shape 为W*H*2,实例分割分支(branch)的输出 shape 为W*H*N,W,H分别为原图宽和高,N 为 embedding vector 的维度;两个分支的loss权重相同。


H-Net
LaneNet的输出是每条车道线的像素集合,还需要根据这些像素点回归出一条车道线。传统的做法是将图片投影到 bird’s-eye view 中,然后使用 2 阶或者 3 阶多项式进行拟合。在这种方法中,变换矩阵 H 只被计算一次,所有的图片使用的是相同的变换矩阵,这会导致地平面(山地,丘陵)变化下的误差。
为了解决这个问题,论文训练了一个可以预测变换矩阵 H 的神经网络 H-Net,网络的输入是图片,输出是变换矩阵 H:
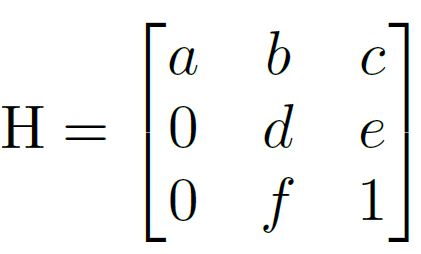
通过置 0 对转置矩阵进行约束,即水平线在变换下保持水平。(即坐标 y 的变换不受坐标 x 的影响)
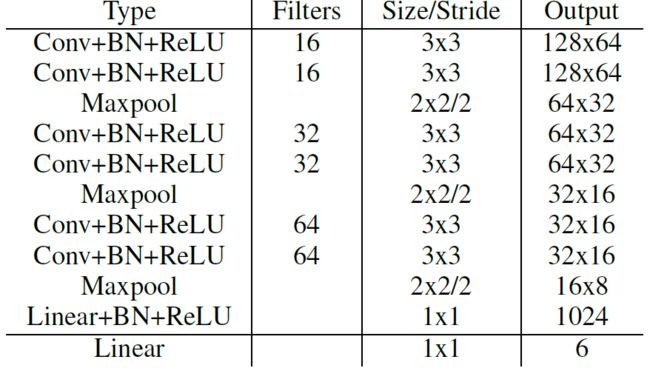
由上式可以看出,转置矩阵 H 只有6个参数,因此H-Net的输出是一个 6 维的向量。H-Net 由 6 层普通卷积网络和一层全连接网络构成,其网络结构如图所示:
Curve Fitting
Curve fitting的过程就是通过坐标 y 去重新预测坐标 x 的过程:
- 对于包含 N 个像素点的车道线,每个像素点 $p_i = [x_i, y_i, 1]^T \in P$, 首先使用 H-Net 的预测输出 H 对其进行坐标变换:
$P^{'} = HP$
- 随后使用 最小二乘法对 3d 多项式的参数进行拟合:
$w = (Y^TY)^{-1}Y^Tx^{'}$
- 根据拟合出的参数 $w = [\alpha, \beta, \gamma]^T$ 预测出 $x_i^{'*}$
$x_i^{'*} = \alpha y^{'2} + \beta y^{'} + \gamma$
- 最后将 $x_i^{'*}$ 投影回去:
$p_i^{*} = H^{-1}p_i^{'*}$
Loss function
$Loss = \frac{1}{N} \sum_{i=1}^{N}(x_i^{*} - x_i)^2 $
实验参数
LanNet
Dataset : Tusimple
Embedding dimension = 4
δ_v=0.5
δ_d=3
Image size = 512*256
Adam optimizer
Learning rate = 5e-4
Batch size = 8
H-Net
Dataset : Tusimple
3rd-orderpolynomial
Image size =128*64
Adam optimizer
Learning rate = 5e-5
Batch size = 10
评价标准
语义分割部分
$accuracy = \frac{2}{\frac{1}{recall} + \frac{1}{precision}}$
$recall = \frac{TP_1}{G_1}$
$precision = \frac{TP_0}{G_0}$
其中 $G_1$ 代表 GT二值图里像素值为 1 部分的数量,$TP_1$ 则代表预测结果里相对于 $G_1$, 预测正确的数量。
简单示例:


import numpy as np
import tensorflow as tf
out_logits = np.array([
[[0.1, 0.1, 0.1, 0.1, 0.1],
[0.1, 0.2, 0.2, 0.8, 0.1],
[0.1, 0.2, 0.2, 0.2, 0.1],
[0.1, 0.2, 0.2, 0.2, 0.1],
[0.1, 0.1, 0.1, 0.1, 0.1]],
[[0.1, 0.1, 0.1, 0.1, 0.1],
[0.1, 0.8, 0.8, 0.2, 0.1],
[0.1, 0.8, 0.8, 0.8, 0.1],
[0.1, 0.8, 0.8, 0.8, 0.1],
[0.1, 0.1, 0.1, 0.1, 0.1]]
]) # 预测结果
binary_label = np.array([
[0, 0, 0, 0, 0],
[0, 1, 1, 1, 0],
[0, 1, 1, 1, 0],
[0, 1, 1, 1, 0],
[0, 0, 0, 0, 0]
]) # GT
logits = np.transpose(out_logits, (1, 2, 0))
out_logits = tf.constant(logits, dtype=tf.float32)
binary_label_tensor = tf.constant(binary_label, dtype=tf.int32)
binary_label_tensor = tf.expand_dims(binary_label_tensor, axis=-1)
# =================== pix_cls_ret: 对于 GT 中为 1 的部分,统计 Pre 中是否分对,1对0错
out_logits = tf.nn.softmax(logits=out_logits)
out = tf.argmax(out_logits, axis=-1) # 最后那个维度上的 max_idx
out = tf.expand_dims(out, axis=-1) # 增加一维 5x5 -> 5x5x1
idx = tf.where(tf.equal(binary_label_tensor, 1))
pix_cls_ret = tf.gather_nd(out, idx)
# =================== recall: 以GT 中像素值为 1 为基数,统计 recall = TP_1 / G1
recall = tf.count_nonzero(pix_cls_ret) # TP_1
recall = tf.divide(recall, tf.cast(tf.shape(pix_cls_ret)[0], tf.int64))
# =================== pix_cls_ret: 对于 GT 中为 0 的部分,统计 Pre 中是否分对,0对1错
idx = tf.where(tf.equal(binary_label_tensor, 0))
pix_cls_ret = tf.gather_nd(out, idx)
# =================== precision: 以 GT 中像素值为 0 为基数,统计 precision = TP_0 / G0
precision = tf.subtract(tf.cast(tf.shape(pix_cls_ret)[0], tf.int64), tf.count_nonzero(pix_cls_ret)) # TP_0
precision = tf.divide(precision, tf.cast(tf.shape(pix_cls_ret)[0], tf.int64))
accuracy = tf.divide(2.0, tf.divide(1.0, recall) + tf.divide(1.0, precision))
with tf.Session() as sess:
out_logits = out_logits.eval()
out = out.eval()
idx = idx.eval()
pix_cls_ret = pix_cls_ret.eval()
recall = recall.eval()
precision = precision.eval()
print(accuracy)View Code
相关文献
LaneNet: Towards End-to-End Lane Detection: an Instance Segmentation Approach
ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation
Discriminative Loss: Semantic Instance Segmentation with a Discriminative loss function
转载于:https://www.cnblogs.com/xuanyuyt/p/11523192.html