二、计算机视觉与卷积神经网络
-
- 一、神经网络到卷积神经网络
- 二、卷积神经网络的构成
- 三、卷积神经网络的训练
- 四、卷积神经网络的特点
- 五、正则化与Dropout
一、神经网络到卷积神经网络
人工神经网络可以用于计算机视觉吗?
可以
为什么利用卷积神经网络?
人工神经网络全连接结构对内存要求非常高,而且大量的参数会导致过拟合,参数过多学习能力太强,会把所有样本点记下来,以至于在测试集的泛化性能很差。
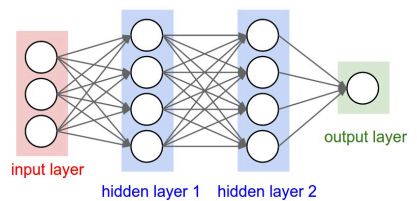
卷积神经网络的特点:
- 仍然保持了层级结构,利用多层网络来构成一个深层的网络结构
- 不同于全连接层,卷积神经网络是由卷积层+池化层+非线性层+全连接层构成

输入:原始图像
输出:经过softmax输出的属于每个类别的概率
二、卷积神经网络的构成

1、数据输入层——数据预处理

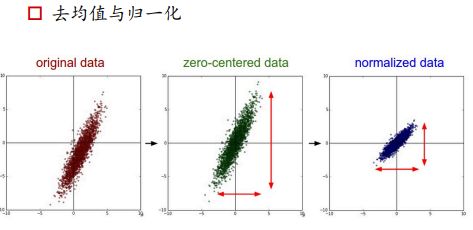
利用L2损失的话,如果不进行尺度缩放,则会使得在梯度下降的时候,下降方向呈z字型,出现震荡、收敛缓慢、准确度下降的情况。
为什么进行去均值化:
如果不进行去均值的步骤,在训练的时候很容易饱和,如果利用sigmoid函数作为激活函数,未进行去均值之前,数据可能处于sigmoid函数的两侧,使得输出为0/1,此时梯度几乎为0,无法进行反向传播,网络无法进行学习。如果进行去均值之后,数据处于sigmoid曲线的中心,此时处于激活状态。
例如图像的对比度,如果完成图像颜色的分辨,如果颜色分布非常均匀,则可以很好的学习出数据,但如果数据有偏移,也就是全都是红色,只不过红的颜色不同,如果减掉均值的话,可以使得数据有正有负。
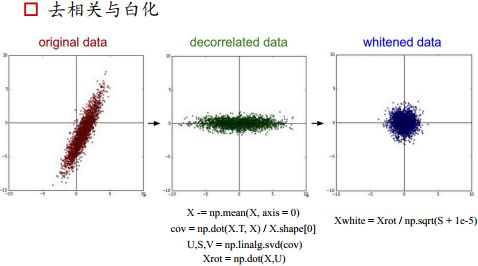
经过PCA之后,去掉了相关性,将数据投影到方差最大的方向,whitened是再次进行尺度归一化
有的特征维度很高,可以在保留大部分特征的情况下, 进行降维,做完PCA之后,进行白化操作,(也就是将每个维度的特征的方差归一化到1),因为进行归一化之后再进行PCA降维,可能每个维度的方差由不同了,所以要再次对特征的方差进行缩放。
图像分类只用了去均值操作:
去均值有两种方法:将100w组图像的均值取出,在每个图像上减掉
- 因为图像的像素值本就处于[0,255]区间内,不用进行归一化,
2、卷积计算层
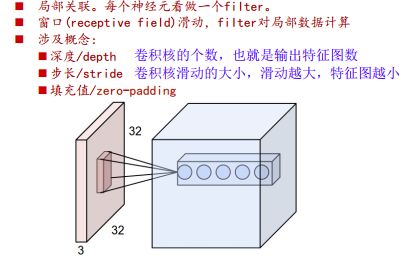
补零:
1、当x=0的时候,wx=0,不会影响输出,如果补别的结果会影响输出
2、补零也会使得卷积之后特征图等于原图大小,信息保留更全面,更利用之后的融合

- 局部关联
图像具有局部关联性,某点的像素和距离它较远的像素不具备很大的相关性,所以可以用局部连接来对图像进行特征提取。
- 权值共享
如果对整幅图像的每个小块分别用不同的卷积核来提取特征,则参数太多,可以利用同一组参数,也就是卷积核来对一副图像滑动进行特征提取,也就是一个窗口提取一副图像中相同的特征,换句话说就是,无论猫出现在图像中的哪个位置,都不会影响最后的判断。
- 特征提取过程
利用同一卷积核和图像做滑动卷积,提取出一个特征图谱,分别利用多个卷积核对同一幅图像做卷积,得到多个特征图。
3、激活层
将卷积层的输出结果做非线性映射,判断信号是否要往后传,或者以多大的程度往后传。
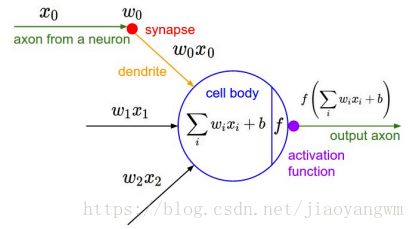
特征:
- 非线性
- 几乎处处可微
- 计算简单
- 非饱和性
- 接近恒等变换
- 单调性


Relu如果输入都是小于0的话,那就挂掉了,全都抑制了,该神经元再也激活不了了,但是这种概率很小,因为数据都是一批一批送进来的,不会都落到抑制区。
所以提出了Leacky Relu,降低完全抑制的概率。
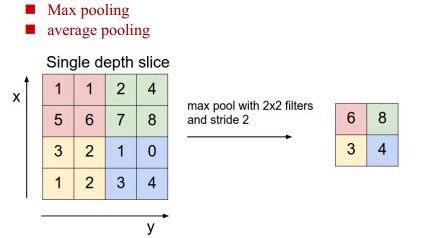
4、池化层
降低数据量,提供平移、旋转稳定性,减小过拟合

5、全连接层

三、卷积神经网络的训练

池化层如何求导:
池化相当于 max(x1,x2,x3,x4) m a x ( x 1 , x 2 , x 3 , x 4 ) ,如果最大值为x4的话,分段函数求导之后,只有x4处为1,其他地方的求导都为0。
四、卷积神经网络的特点

五、正则化与Dropout
神经网络的强学习能力可能会导致过拟合,利用Dropout来解决。
Dropout:随机失活,也就是将神经元随机失活,置为0,此时和该神经元相连的线也就没用了。
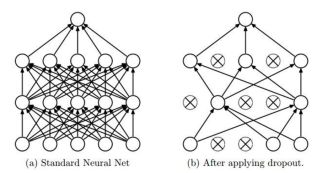
在每一次做训练的时候,会将某些神经元关掉,该神经元就不起作用了,
import numpy as np
p=0.5
def train_step(X):
# 3层神经网络的前向计算
# H1包含了Relu的过程
H1=np.maximum(0,np.dot(w1,x)+b1)
'''第一次dropout'''
# 生成0~1直接的随机数,小于0.5的置为False,大于0.5的置为True
U1=np.random.rand(*H1.shape)# H1和U1数值相乘,保留U1中为True的值
H1 *=U1
'''第二次dropout'''
H2=np.maximum(0,np.dot(w2,x)+b2)
U2 = np.random.rand(*H2.shape) < p
H2 *=U2
out=np.dot(w3,H2)+b3
.
.
.
# 预测过程
# 以数学期望的形式往后传递
# 一个时间发生的概率为p,数学期望E=X.P
def predict(X):
# 加上dropout的前向计算
H1=np.maximum(0,np.dot(w1,x)+b1)*p
H2=np.maximum(0,np.dot(w2,x)+b2)*p
out=np.dot(w3,H2)+b3
U1是一个bool型的numpy数组,生成随机概率分布,如果大于0.5就留下来,
实际实现:把预测阶段的时间转移到训练上
用户关心的是测试的速度,与训练的速度无关。
所以要把预测阶段的时间转移到训练阶段,以数学期望的方式来转移。训练过程除以p,等于预测过程乘以p。

Dropout的作用:防止过拟合
- 去掉冗余信息
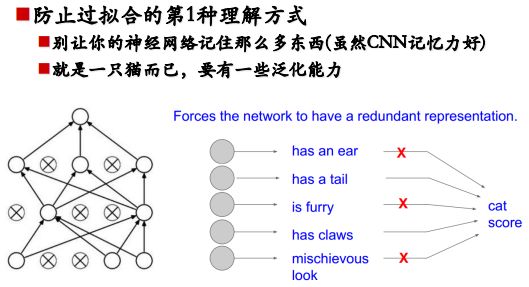
网络学到的东西(比如有耳朵、毛茸茸等等)可能是冗余的信息,只有一部分信息是真正有用的,而哪些信息是有用的呢?
Dropout是随机失活的,也就是说有时候的训练没有该神经元,也就是没有部分信息。如果有耳朵的信息判定的结果是一只猫,没有耳朵的信息判定结果也是一只猫,那么耳朵这个信息就是冗余的。
- 每次都关掉一部分感知器,相当于每次得到一个新模型,最后做模型融合,多个模型的投票或平均得到结果

《Dropout: A Simple Way to Prevent Neural Networks from Overfitting》