使用SSD训练自己的数据集 实现多类别的目标检测 (Pytorch)
写在前面:刚刚入门时踩了不少坑,现在把我的经验总结起来给大家看,希望帮助到有需要的新手朋友们。我没有GPU,所以是基于colab训练的(colab是一个类似于jupyter notebook的平台,提供免费gpu),但这篇文章的方法win/mac/linux都适用。
我的torch版本:1.4.0,如果你是0.x版本,可能某些方法不适用,先看完文章再考虑修改吧!
我做了个详细的视频教程:https://www.bilibili.com/video/BV14Q4y1M7j3/
这篇文章的方法,我是边操作边记录的,所以一定可行,如果你有报错,请仔细检查有没有一步步按着做。
- 1. 准备VOC数据集
- 2. 在colab中下载ssd.pytorch源码并适当修改
- 2.1 初始化一些colab设置(不用colab的朋友请直接看2.2)
- 2.2 修改源码,使其适用于我们的训练样本
- 2.2.1 修改 data/\_\_init\_\_.py
- 2.2.2 修改 data/config.py
- 2.2.3 修改 data/voc0712.py
- 2.2.4 修改 layers/modules/multibox_loss.py
- 2.2.5 修改 ssd.py
- 2.2.6 修改 train.py
- 2.2.7 准备预训练的权重文件
- 2.2.8 放入自己的数据集
- 3. 开始训练
- 4. 评估模型
- 5. 测试模型
- 6. 用自己的图片进行测试
1. 准备VOC数据集
作为示例,我准备了5个类别(mouse, radio, camera, bag, clock),每类10张图像。
首先了解一下VOC数据集的形式,根据这篇文章的详细介绍,结合本实验的目的,我们这样准备VOC数据集
-
创建
VOC2007文件夹,位置先不用在意; -
在
VOC2007文件夹下,创建三个子文件夹:Annotations,ImageSets和JPEGImages;在ImageSets文件夹下创建子文件夹Main; -
把
jpg格式的图片都放到JPEGImages文件夹下,最好用000001.jpg、000002.jpg这样的格式重命名一下; -
使用
labelimg标注图像。这个工具可以去https://github.com/tzutalin/labelImg 自行下载安装。安装与使用教程很多,在此不赘述。打开labelimg后,左栏的【打开目录】定位到/VOC2007/JPEGImages这个路径,【改变存放目录】定位到/VOC2007/Annotations这个路径。然后就开始进行标注吧!生成的xml标注文件会自动放到目标路径中。注意:标注时类名中不能有大写英文字母,不然会报错。 -
最后,要把样本分割为训练集、验证集、测试集等。分割情况会在
/VOC2007/ImageSets/Main文件夹内的txt文件中进行记录。这里应该有4个txt文件,分别是:train.txt(用于训练的样本,25%)、val.txt(用于验证的样本,25%)、trainval.txt(train与val的合集)、test.txt(用于测试的样本,50%)。我这里提供一个
make_txt.py文件(在文末),把它放到/VOC2007路径下,然后运行这个python文件,就可以得到样本的分割结果。
最后的文件目录应该是这样,对照一下,不要有错:
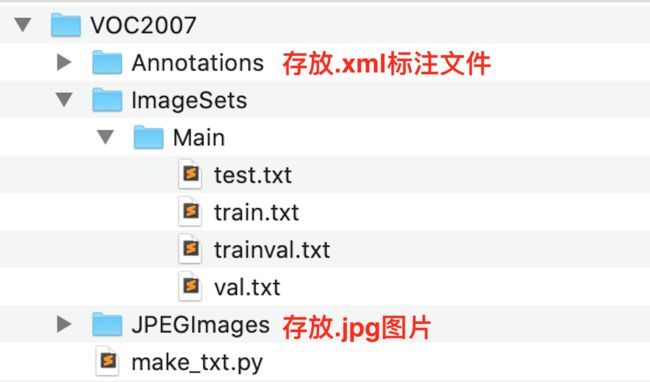
2. 在colab中下载ssd.pytorch源码并适当修改
2.1 初始化一些colab设置(不用colab的朋友请直接看2.2)
说明:我个人习惯使用“备份与同步”功能,所以我会在本地的共享文件夹中修改代码,然后随时同步至云端。如果你不习惯这样,也可以在本地都修改好之后一起放到云盘中。
-
在“我的云端硬盘”新建文件夹
SSD,进入文件夹,新建一个colab笔记本。 -
打开笔记本,依次点击 修改–笔记本设置,硬件加速器选择GPU,点击保存。
-
挂载Google Drive云端硬盘(需要按提示粘贴授权码):
from google.colab import drive drive.mount('/content/drive') -
更改路径到SSD文件夹:
import os os.chdir('drive/My Drive/SSD') -
拷贝ssd.pytorch的github项目到SSD文件夹下:
!git clone 'https://github.com/amdegroot/ssd.pytorch.git' -
现在我的本地共享文件夹中,SSD目录已经同步过来了,打开一看,ssd.pytorch也同步好了,现在就可以对源码开始进行修改了。(Untitled0.ipynb是刚刚新建的colab笔记本)
2.2 修改源码,使其适用于我们的训练样本
在pycharm中打开刚刚拷贝的ssd.pytorch项目。进行以下修改(以下有些修改不适用于0.x版本的pytorch):
2.2.1 修改 data/__init__.py
把第3行代码from .coco import COCODetection, COCOAnnotationTransform, COCO_CLASSES, COCO_ROOT, get_label_map注释掉,因为不用COCO数据集。
2.2.2 修改 data/config.py
第15行的num_classes改成你的类别数+1,因为还有个背景类。比如我有5类数据,所以我这里改成6。
2.2.3 修改 data/voc0712.py
- 第20行开始的
VOC_CLASSES改成你自己的类名,比如我改成了:VOC_CLASSES = ('bag', 'radio', 'camera', 'clock', 'mouse')。 - 源码中的
VOC_ROOT = osp.join(HOME, "data/VOCdevkit/")我这里会报错,猜测是colab的路径具有特殊性,所以我改成了VOC_ROOT = './data/VOCdevkit/'。如果你也有报错,可以参考我这个改法。 - 源码中的98行是
image_sets=[('2007', 'trainval'), ('2012', 'trainval')],由于没有VOC2012数据集,所以要把后面的2012删掉,变成image_sets=[('2007', 'trainval')]
2.2.4 修改 layers/modules/multibox_loss.py
- 在第97行
loss_c[pos] = 0的前面加上一行loss_c = loss_c.view(num, -1) - 来到文件的最后位置,从原来的:
改成:N = num_pos.data.sum() loss_l /= N loss_c /= N return loss_l, loss_cN = num_pos.data.sum().double() loss_l = loss_l.double() loss_c = loss_c.double() loss_l /= N loss_c /= N return loss_l, loss_c
2.2.5 修改 ssd.py
- 第32行,
num_classes从21改成你的类别数+1。我的样本有5类,所以我改成6。 - 第198行,
num_classes也从21改成你的类别数+1。
2.2.6 修改 train.py
- 搜索
data[0],一共有5处,把[0]全部删掉,也就是说把所有的data[0]改成data。 - 把第84、85行的以下代码注释掉,不然会报错说找不到coco:
if args.dataset_root == COCO_ROOT: parser.error('Must specify dataset if specifying dataset_root') - 第165行的源码是
images, targets = next(batch_iterator),要修改一下,不然训练几百次就报错了。改成这样子:try: images, targets = next(batch_iterator) except StopIteration: batch_iterator = iter(data_loader) images, targets = next(batch_iterator) - 接下来是最后两处修改~ 其实这两处不改也行,看你习惯了。首先,直接搜
5000,来到这一行,可以看到源码是iteration % 5000 == 0,意思是迭代5000次保存一次生成的权重文件。这个次数,看你自己喜好进行修改。
然后从这行开始往下数两行,你可以看到'weights/ssd300_COCO_',这是保存的权重文件的名称,按你喜好可以改一下,我改成了'weights/ssd300_VOC_'。
不过我真心给使用colab的朋友一个提醒:那个数字,最好改小一点,比如迭代500、1000次就保存一次,因为colab不一定什么时候就断了,或者限制你使用GPU了,数字改小一点,便于重连后从前一次保存的权重文件开始训练,节约时间。(我之前训练了3w次,期间断开连接三次,被限制使用GPU两次。前者重新连接,然后从上一次保存的权重文件开始训练就可以,后者要等12~24个小时才能重新连接上。原来资本主义的羊毛也不是那么容易薅的)
2.2.7 准备预训练的权重文件
在ssd.pytorch文件夹下新建weights文件夹,把预训练好的权重文件vgg16_reducedfc.pth放进去,下载链接在文末。
2.2.8 放入自己的数据集
在ssd.pytorch/data文件夹下新建VOCdevkit文件夹,把我们刚刚准备的VOC2007文件夹整个拖进去就可以了。
3. 开始训练
进入ssd.pytorch路径,开始训练。在colab命令行中,我输入:
!python3 train.py
就开始训练了。在train.py中,一些参数的默认值如下:

如果你想修改默认值,比如把batch_size改为16,learning rate改为1e-4,就这样写:
!python3 train.py --batch_size=16 --lr=1e-4
如果训练不小心中断了,怎么在上一次保存的权重文件的基础上开始训练呢?
我们每次保存的权重文件都在weights文件夹里,比如我训练了700次中断,上一次保存的权重文件名为ssd300_VOC_500.pth,那么可以这样输入:
!python3 train.py --resume='weights/ssd300_VOC_500.pth'
我的运行过程截图:
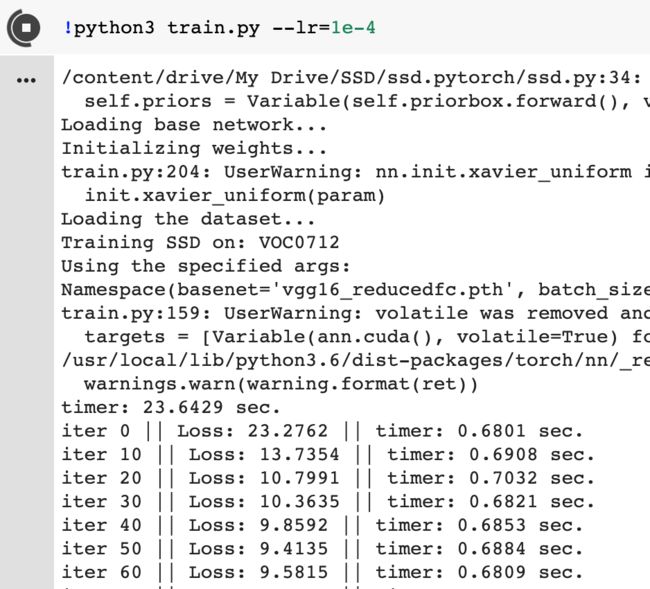
默认训练是12w轮,这个数字可以在train.py文件中找到。其实不用那么多轮,你觉得loss不再明显下降的时候就可以停了(比如我这里训练了1500次时,loss就在1左右不下降了)。
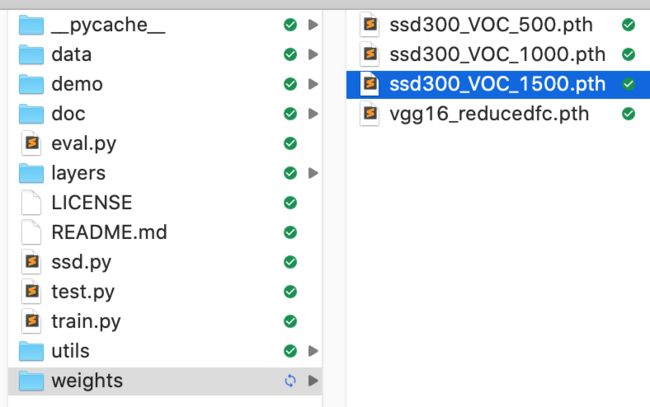
最后生成的模型(权重文件)在weights文件夹里,保留最后一次生成的文件就行,别的都可以删掉。如下,除了ssd300_VOC_1500.pth,别的都可以删掉。
4. 评估模型
使用eval.py进行评估。这个文件不需要改,只需要在运行的时候,把trained_model改为你刚刚训练好的模型就可以。比如我最后的保存的模型为ssd300_VOC_1500.pth,就像这样写:
!python3 eval.py --trained_model='weights/ssd300_VOC_1500.pth'
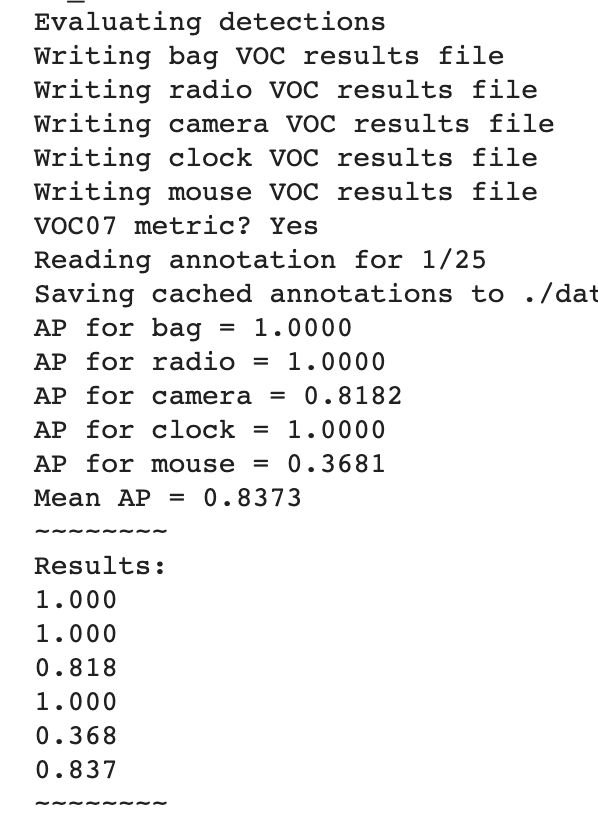
结果展示如下(AP指平均精度,mean AP是所有类别的平均精度均值):
5. 测试模型
使用test.py进行测试。和评估的过程一样,这个文件也不需要改,只需要在运行的时候,把trained_model改为你刚刚训练好的模型就可以。
!python3 test.py --trained_model='weights/ssd300_VOC_1500.pth'
测试完以后,结果保存在eval/test1.txt中,部分截图如下:

6. 用自己的图片进行测试
源码提供了ssd.pytorch/demo/demo.ipynb可以进行测试。我想尝试在本地用训练好的模型直接进行测试,就改了一下代码,写了个demo.py,放到ssd.pytorch/demo/路径下,直接运行就行。代码在文末,要改的地方我都标出来了。
(我在ssd.pytorch路径下创建了一个my_img文件夹,用于测试的图片都在里面。)
结果展示如下(mouse的准确率很低,因为我样本没找好…样本数量本来就少,不够准确+训练次数少的话就会像我这样):

OK了,教程到此结束。以下是一些代码和权重文件。
make_txt.py(不用修改,直接用)
import os
import random
trainval_percent = 0.5
train_percent = 0.5
xmlfilepath = './Annotations/'
txtsavepath = './ImageSets/Main/'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open(txtsavepath+'/trainval.txt', 'w')
ftest = open(txtsavepath+'/test.txt', 'w')
ftrain = open(txtsavepath+'/train.txt', 'w')
fval = open(txtsavepath+'/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
demo.py(要进行3处修改,都标出来了)
# 使用SSD(Pytorch)进行目标检测
import os
import sys
import torch
from torch.autograd import Variable
import numpy as np
import cv2
from ssd import build_ssd
from data import VOC_CLASSES as labels
from matplotlib import pyplot as plt
# 定位到ssd.pytorch这个路径
module_path = os.path.abspath(os.path.join('..'))
if module_path not in sys.path:
sys.path.append(module_path)
if torch.cuda.is_available():
torch.set_default_tensor_type('torch.cuda.FloatTensor')
# 构建架构,指定输入图像的大小(300),和要评分的对象类别的数量(X+1类)
net = build_ssd('test', 300, X+1) # 【改1】这里改一下,如果有5类,就改成6
# 将预训练的权重加载到数据集上
net.load_weights('../weights/xxx.pth') # 【改2】这里改成你自己的模型文件
# 加载多张图像
# 【改3】改成你自己的文件夹
imgs = '../my_img/'
img_list = os.listdir(imgs)
for img in img_list:
# 对输入图像进行预处理
current_img = imgs + img
image = cv2.imread(current_img)
rgb_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
x = cv2.resize(image, (300, 300)).astype(np.float32)
x -= (104.0, 117.0, 123.0)
x = x.astype(np.float32)
x = x[:, :, ::-1].copy()
x = torch.from_numpy(x).permute(2, 0, 1)
# 把图片设为变量
xx = Variable(x.unsqueeze(0))
if torch.cuda.is_available():
xx = xx.cuda()
y = net(xx)
# 解析 查看结果
top_k = 10
plt.figure(figsize=(6, 6))
colors = plt.cm.hsv(np.linspace(0, 1, 21)).tolist()
currentAxis = plt.gca()
detections = y.data
scale = torch.Tensor(rgb_image.shape[1::-1]).repeat(2)
for i in range(detections.size(1)):
j = 0
while detections[0, i, j, 0] >= 0.6:
score = detections[0, i, j, 0]
label_name = labels[i-1]
display_txt = '%s: %.2f'%(label_name, score)
print(display_txt)
pt = (detections[0,i,j,1:]*scale).cpu().numpy()
coords = (pt[0], pt[1]), pt[2]-pt[0]+1, pt[3]-pt[1]+1
color = colors[i]
currentAxis.add_patch(plt.Rectangle(*coords, fill=False, edgecolor=color, linewidth=2))
currentAxis.text(pt[0], pt[1], display_txt, bbox={'facecolor':color, 'alpha':0.5})
j += 1
plt.imshow(rgb_image)
plt.show()
预训练的权重文件:vgg16_reducedfc.pth 密码:4cfd
有问题请留言,看到就会回。