python scrapy爬虫学习(包含集成django方法,以及在django页面中启动爬虫)
爬虫开发步骤
一、环境介绍
开发工具:pycharm(社区版本)
python版本:3.7.4
scrapy版本:1.7.3
二、整体步骤
1.创建项目:scrapy startproject xxx(项目名字,不区分大小写)
2.明确目标 (编写items.py):明确你想要抓取的目标
3.制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
4.存储内容 (pipelines.py):设计管道存储爬取内容
5.设置settings.py:
- USER_AGENT=网页中-F12-网络-找到爬取地址的请求-右侧看消息头-找到USER_AGENT填写到该处;
- ROBOTSTXT_OBEY=False忽略被爬取网站的允许爬取列表限制,Ture根据授权列表爬取,没有权限的不去爬取
- DOWNLOAD_DELAY=下载延迟,数值
- ITEM_PIPELINES=多个管道处理时设置优先级,根据:xx冒号后面的数值大小排序
6.启动程序的py文件(start.py):等同于此命令(scrapy crawl xxx -o xxx.json)
三、开发准备
1.在pycharm工具setting中安装scrapy插件
2.项目右键选择打开终端
3.在终端中输入爬虫创建命令

执行成功后在项目目录下生成爬虫项目
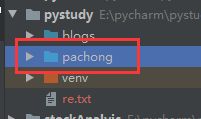
项目结构如下
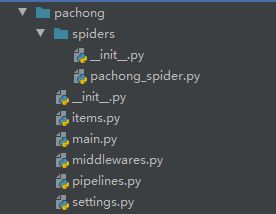
3.各个文件功能介绍
(1)iterms.py是用于封装爬虫爬取内容的实体,具体如下:
import scrapy
class PachongItem(scrapy.Item):
# define the fields for your item here like:
date = scrapy.Field()
open = scrapy.Field()
close = scrapy.Field()
height = scrapy.Field()
low = scrapy.Field()
updownd = scrapy.Field()
turnrate = scrapy.Field()
count = scrapy.Field()
如果要集成django,使用django的持久化对象以及其数据库操作能力的话,需要安装scrapy_djangoitem插件,然后做如下引用
import scrapy
from scrapy_djangoitem import DjangoItem
import blog.models as m # 保证django项目与爬虫项目在一个工程下,然后引用django的实体模型
class PachongItem(DjangoItem): # scrapy.Item
# define the fields for your item here like:
# date = scrapy.Field()
# open = scrapy.Field()
# close = scrapy.Field()
# height = scrapy.Field()
# low = scrapy.Field()
# updownd = scrapy.Field()
# turnrate = scrapy.Field()
# count = scrapy.Field()
django_model = m.Spider # m.spider是django中定义的实体
(2)pachong_spider.py爬虫主体方法,文件名可以自定义
from datetime import datetime
from decimal import Decimal
import scrapy
import pachong.items as items
# from items import PachongItem
# 命令行创建爬虫项目命令:scrapy startproject 项目名称
class PobotSpider(scrapy.Spider):
# 爬虫的名称,也就是该文件名称,不能乱写,写其他的会报错:找不到爬虫文件
name = 'pachong_spider'
# 爬虫允许抓取的域名
allowed_domains = ['quotes.money.163.com']
# 爬虫抓取数据地址,给调度器
start_urls = ['http://quotes.money.163.com/trade/lsjysj_600051.html?year=2018&season=1']
# *args(多个参数无key值,字符串列表), **kwargs(多个参数有key值,字典列表)
def __init__(self, *args, **kwargs):
super(PobotSpider, self).__init__(*args, **kwargs)
url = 'http://quotes.money.163.com/trade/lsjysj_600051.html?year='+kwargs['year']+'&season='+kwargs['jd']
self.start_urls = [url]
print(self.start_urls)
def parse(self, response):
# # 打印返回结果
# print(response.text)
# xpath语法:根据抓取网页的目录结构, 等到上面结果, 意思是选取class为article的div下, class为grid_view的ol下的所有li标签
# extract() 获取真实内容;extract_first()获取第一个匹配的真是内容;//全局匹配包含子节点孙子节点,全级别搜索;"/"根节
# 点匹配子节点不包含孙子节点,检索一级标签;属性匹配div[@id="name"];text()匹配标签内的文本;.get()/.getall()获取第一个匹配的文本/全部匹配的文本
# response.xpath(’//div[@class=“col1”]/div’)[0].xpath(’./a/div/span/text()’).getall();./或.//当前选择的标签内容中搜索
# ;../或..//父级标签内搜索子或孙子标签;
# response.xpath(’//div[@class=“col1”]/div’)[0].xpath(’./a/div/span/@class’).getall()获取选择标签的class属性值
# 支持切片
stock_list = response.xpath("//div[@class='area']//div[@class='inner_box']//table//tr")
for index, i_item in enumerate(stock_list):
if index == 0:
continue
stock_item = items.PachongItem()
# 1.DoubanItem() 模型初始化
# 2.douban_item['serial_number'] 设置模型变量serial_number值,
# 3.i_item.xpath(".//div[@class='item']//em/text()") 对返回结果进一步筛选, 并且以"." 开头表示拼接, 以text()结束表示获取其信息
# 4.extract_first() xpath匹配器返回的是一个list,即使只有一个值也是放在list中的,因此要想直接获取字符串,需要获取结果的第一个值
# 也就是用extract_fist(),也可以用索引xpath()[0]
stock_item['date'] = datetime.strptime(i_item.xpath(".//td[1]/text()").extract_first(), '%Y-%m-%d')
stock_item['open'] = Decimal(i_item.xpath(".//td[2]/text()").extract_first())
stock_item['height'] = Decimal(i_item.xpath(".//td[3]/text()").extract_first())
stock_item['low'] = Decimal(i_item.xpath(".//td[4]/text()").extract_first())
stock_item['close'] = Decimal(i_item.xpath(".//td[5]/text()").extract_first())
stock_item['updownd'] = Decimal(i_item.xpath(".//td[7]/text()").extract_first())
stock_item['count'] = Decimal(i_item.xpath(".//td[10]/text()").extract_first())
stock_item['turnrate'] = Decimal(i_item.xpath(".//td[11]/text()").extract_first())
# yield 就是一个集合对象,可以将多次返回的值存入到一个集合迭代器中。
yield stock_item
(3)pipelines.py用于持久化爬取的数据,并进行清洗过滤,可以有多个pipeline
不集成django的写法如下:
import pymysql
# pipeline管道,用于持久化爬取的数据,并进行清洗过滤,可以有多个pipeline
# 继承object类,重写了几个方法
# 可以多个pipeline 实现类,通过settings.py中的ITEM_PIPELINES配置格式:‘类路径’:级别(整型数值),与优先级系数来判定哪个先执行
# 带@classmethod的是类方法,类方法不实例化,可以理解为全局方法,重写时也需要带此注解
class PachongPipeline(object):
movieInsert = '''insert into blog_spider(date,open,close,height,low,updownd,turnrate,count)
values('{date}','{open}','{close}','{height}','{low}',
'{updownd}','{turnrate}','{count}')'''
def __init__(self):
self.conn = pymysql.connect(user='root', password='@bjive321',
host='59.110.138.8', port=3306,
database='blog', use_unicode=True,
charset='utf8')
self.cursor = self.conn.cursor()
self.conn.autocommit(True)
def process_item(self, item, spider):
# pymysql.escape_string用于转译,将字符串内的转义字符,转译
sql_text = self.movieInsert.format(
date=datetime.datetime.strptime(pymysql.escape_string(item['date']), '%Y-%m-%d'),
open=Decimal(pymysql.escape_string(item['open'])),
close=Decimal(pymysql.escape_string(item['close'])),
height=Decimal(pymysql.escape_string(item['height'])),
low=Decimal(pymysql.escape_string(item['low'])),
updownd=Decimal(pymysql.escape_string(item['updownd'])),
turnrate=Decimal(pymysql.escape_string(item['turnrate'])),
count=Decimal(pymysql.escape_string(item['count'])))
self.cursor.execute(sql_text)
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
集成django写法如下:
import pymysql
# pipeline管道,用于持久化爬取的数据,并进行清洗过滤,可以有多个pipeline
# 继承object类,重写了几个方法
# 可以多个pipeline 实现类,通过settings.py中的ITEM_PIPELINES配置格式:‘类路径’:级别(整型数值),与优先级系数来判定哪个先执行
# 带@classmethod的是类方法,类方法不实例化,可以理解为全局方法,重写时也需要带此注解
class PachongPipeline(object):
# movieInsert = '''insert into blog_spider(date,open,close,height,low,updownd,turnrate,count)
# values('{date}','{open}','{close}','{height}','{low}',
# '{updownd}','{turnrate}','{count}')'''
def __init__(self):
self.conn = pymysql.connect(user='root', password='@bjive321',
host='59.110.138.8', port=3306,
database='blog', use_unicode=True,
charset='utf8')
self.cursor = self.conn.cursor()
self.conn.autocommit(True)
def process_item(self, item, spider):
# # pymysql.escape_string用于转译,将字符串内的转义字符,转译
# sql_text = self.movieInsert.format(
# date=datetime.datetime.strptime(pymysql.escape_string(item['date']), '%Y-%m-%d'),
# open=Decimal(pymysql.escape_string(item['open'])),
# close=Decimal(pymysql.escape_string(item['close'])),
# height=Decimal(pymysql.escape_string(item['height'])),
# low=Decimal(pymysql.escape_string(item['low'])),
# updownd=Decimal(pymysql.escape_string(item['updownd'])),
# turnrate=Decimal(pymysql.escape_string(item['turnrate'])),
# count=Decimal(pymysql.escape_string(item['count'])))
# self.cursor.execute(sql_text)
item.save()
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
(4)settings.py用于爬虫配置信息的设置
如果集成django配置如下:
import os
import sys
import django
#======集成django需要增加以下内容,不集成则不需要===start======
sys.path.append(r"E:\pycharm\pystudy\blogs") # django项目的绝对路径
os.environ['DJANGO_SETTINGS_MODULE'] = 'blogs.settings' # Django工程名.settings
# 手动初始化Django:
django.setup()
#=====end=================================
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36'
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 0.5
#可以配置多个管道
ITEM_PIPELINES = {
'pachong.pipelines.PachongPipeline': 300,
}
(5)创建一个main.py用于启动爬虫
cmdline.execute('scrapy crawl pachong_spider'.split())
4.启动爬虫

ok
5.遇到的问题解决
引入包的时候可能会找不到路径,在工具,File->Settings->python console选中右侧红框内容

然后右键项目中引用涉及到的目录文件夹,选择如下:

即可。
四、django启动爬虫
如果需要在django页面启动爬虫的话需要安装scrapyd,安装方法请自定网查
安装好后执行scrapyd启动服务,默认端口是6800
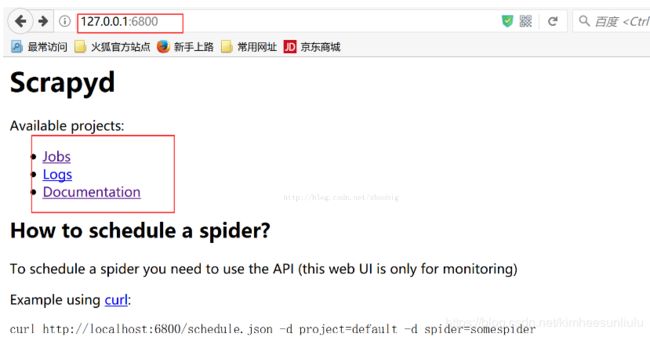
在django页面增加一个按钮,执行start请求,对应url与view中加入相关配置
启动方法代码如下:
#在线启动爬虫
def start_scrapy(request):
# 获取页面传参,要区分请求类型是POST还是GET,不同请求用不同的方法接收参数
year = request.POST.get('year')
jd = request.POST.get('jd')
url = 'http://127.0.0.1:6800/schedule.json'
# spider是执行scrapy list返回的名称,参数问题:除了内置key的参数外如project,spider等,其他参数均由爬虫初始化函数的kwargs接收
# 同时jobid也有kwargs接收,**kwargs是接收字典型的参数,带有key值的
data = {'project': 'pachong', 'spider': 'pachong_spider', 'year': year, 'jd': jd}
print(requests.post(url=url, data=data))
return JsonResponse({'result': 'ok'})
项目源代码:https://download.csdn.net/download/kimheesunliulu/11750758