图像超分辨率网络:EDSR

作者:石文华
编辑:陈人和
前 言
图像超分辨率(SR)问题,特别是单图像超分辨率(single image super-resolution,SISR)问题,最近十年来受到越来越多的研究关注。SISR的目的是从单个低分辨率图像I(LR)重建高分辨率图像I(SR)。通常,I(LR)与原始的高分辨率图像I(HR)之间的关系根据不同的情况是不同的。许多研究假设I(LR)是I(HR)的双三次降采样版本,但是其他降质因素,例如模糊,抽取或噪声在实际应用中也可以考虑。深度超分辨率网络EDSR是NTIRE2017超分辨率挑战赛上获得冠军的方案。
章节目录
存在问题
方法
上采样
网络架构
在NTIRE2017超分辨率挑战赛的结果
补充
01
存在问题
深度神经网络为SR问题中的峰值信噪比(PSNR)提供了显着的性能改进。但是,这样的网络在架构最优性方面有所限制。
(1)、神经网络模型的重建性能对架构的微小变化很敏感。同样的模型在不同的初始化和训练技术之下实现的性能水平不同。
(2)、大多数现有的SR算法将不同缩放因子的超分辨率问题作为独立的问题,没有考虑并利用SR中不同缩放之间的相互关系。 因此,这些算法需要许多scale-specific的网络,需要各自进行训练来处理各种scale。
(3)、SRResNet 成功地解决了计算时间和内存的问题,并且有很好的性能,但它只是采用了原始的ResNet架构,而原始的ResNet目的是解决更高层次的计算机视觉问题,例如图像分类和检测。因此,将ResNet架构直接应用于超分辨率这类低级视觉问题可能不是最佳的。
02
方法
为了解决上述那些问题,基于SRResNet架构,作者通过分析删除不必要的模块进行优化,把batch norm层移除掉(bn层的计算量和一个卷积层几乎持平,移除bn层后训练时可以节约大概40%的空间)以及相加后不经过relu层,同时为了保证训练更加稳定,残差块在相加前,经过卷积处理的一路乘以一个小数(比如作者用了0.1)。这些改变构造出更简单的结构,并且在计算效率上优于原始网络,最终的结构图如下:

新的resBlock代码:
import os
import sys
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
def conv(inp, oup, kernel_size, stride=1, dilation=1, groups=1, bias=True):
padding = ((kernel_size -1) * dilation + 1) // 2
return nn.Sequential(
nn.Conv2d(inp, oup, kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias),
)
class ResBlock(nn.Module):
def __init__(self, inp, kernel_size=3, bias=True, bn=False, act=nn.ReLU(True), res_scale=1):
super(ResBlock, self).__init__()
modules = []
for i in range(2):
modules.append(conv(inp, inp, kernel_size, bias=bias))
if bn:
modules.append(nn.BatchNorm2d(inp))
if i == 0:
modules.append(act)
self.body = nn.Sequential(*modules)
self.res_scale = res_scale
def forward(self, x):
res = self.body(x).mul(self.res_scale)
res += x
return res
resBlock=ResBlock(64)
resBlock
Out[1]:
ResBlock(
(body): Sequential(
(0): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(1): ReLU(inplace)
(2): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
)03
上采样
(1)Interpolation
比如SRCNN就用简单的三次样条插值进行初步的上采样,然后进行学习非线性映射 。
(2)deconvolution
比如FSRCNN在最后的上采样层,通过学习最后的deconvolution layer。但deconvolution本质上是可以看做一种特殊的卷积,理论上后面要通过stack filters才能使得性能有更大的提升,用deconvolution作为upscale手段的话,通常会带入过多人工因素进来(有不少论文提到这个)。
(3)亚像素卷积层(sub-pixel convolutional layer)
网络的输入是原始低分辨率图像,通过三个卷积层以后,得到通道数为r^2的与输入图像大小一样的特征图像。再将特征图像每个像素的r^2个通道重新排列成一个[r×r]大小的子块,从而大小为[H×W×r^2]的特征图像被重新排列成[rH×rW×1]的高分辨率图像。

如上图,可以看出r^2其实就是9,有9个通道,目的就是为了使分辨率增大原来的3倍,所以它从左到右、从上到下把对应的1*1*9的特征展开成3*3的特征,重组成一个新的特征图,上采样代码:
class Upsampler(nn.Sequential):
def __init__(self, scale, inp, bn=False, act=False, bias=True, choice=0):
modules = []
if choice == 0: #subpixel
if (scale & (scale - 1)) == 0: # Is scale = 2^n?
for _ in range(int(math.log(scale, 2))):
modules.append(conv(inp, 4 * inp, 3, bias=bias))
modules.append(nn.PixelShuffle(2))
if bn:
modules.append(nn.BatchNorm2d(inp))
if act:
modules.append(act())
elif scale == 3:
modules.append(conv(inp, 9 * inp, 3, bias=bias))
modules.append(nn.PixelShuffle(3))
if bn:
modules.append(nn.BatchNorm2d(inp))
if act:
modules.append(act())
else:
raise NotImplementedError
elif choice == 1: #decov反卷积
modules.append(nn.ConvTranspose2d(inp, inp, scale, stride=scale))
else: #bilinear #线性插值上采样
modules.append(nn.Upsample(mode='bilinear', scale_factor=scale, align_corners=True))
super(Upsampler, self).__init__(*modules)
# tail
scale=2
inp=64
output_channel=3
if scale > 1:
tail = nn.Sequential( *[ Upsampler(scale, inp, act = False, choice = 0), conv(inp, 3, output_channel) ] )
else:
tail = nn.Sequential( *[ conv(inp, 3, output_channel) ] )
tail
Out[2]:
Sequential(
(0): Upsampler(
(0): Sequential(
(0): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(1): PixelShuffle(upscale_factor=2)
)
(1): Sequential(
(0): Conv2d(64, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)04
网络架构
(1)、单尺度SR网络(EDSR)的架构
和SRResnet非常相似,但移除了残差块里的bn和大多数relu。最终的训练版本有B=32个残差块,F=256个通道。并且在训练*3,*4模型时,采用*2的预训练参数。
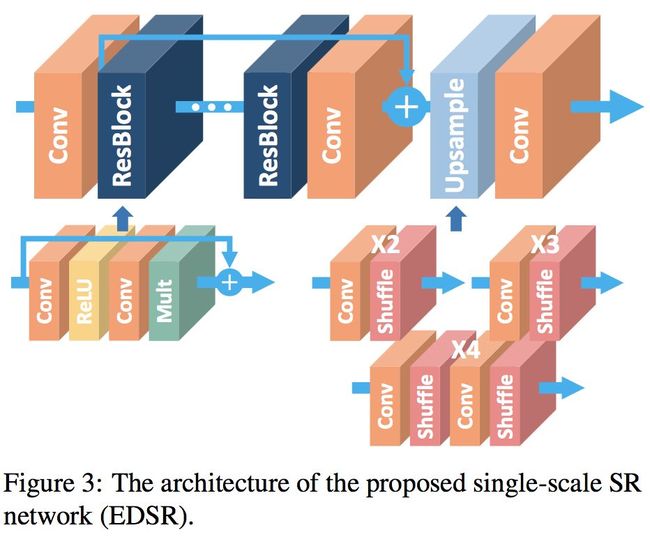
(2)、多尺度SR网络(MDSR)的架构
一开始每个尺度都有两个独自的残差块,之后经过若干个残差块,最后再用独自的升采样模块来提高分辨率。最终的训练版本有B=80个残差块,F=64个通道。

05
在NTIRE2017超分辨率挑战赛的结果
红色表示最优性能,蓝色表示其次。

06
补充:
(1)、PSNR,峰值信噪比
通常用来评价一幅图像压缩后和原图像相比质量的好坏,当然,压缩后图像一定会比原图像质量差的,所以就用这样一个评价指标来规定标准了。PSNR越高,压缩后失真越小。这里主要定义了两个值,一个是均方差MSE,另一个是峰值信噪比PSNR,公式如下:

(2)、SSIM(structural similarity index),结构相似性,是一种衡量两幅图像相似度的指标

代码地址
网络结构部分的代码详见:
https://github.com/cswhshi/super-resolution/blob/master/edsr_mdsr.py
参考:
https://blog.csdn.net/leviopku/article/details/84586446
https://www.cnblogs.com/ranjiewen/p/6390846.html
https://baike.baidu.com/item/SSIM/2091025?fr=aladdin
https://blog.csdn.net/Gavinmiaoc/article/details/80452229

END
往期回顾
【1】 语义分割网络经典:FCN与SegNet
【2】 绝对不容错过:最完整的检测模型评估指标mAP计算指南(附代码)在这里!
【3】【干货收藏】不要担心没数据!史上最全数据集网站汇总
【4】 人人必须要知道的语义分割模型:DeepLabv3+
【5】 network sliming:加快模型速度同时不损失精度
【6】 理解Batch Normalization(含实现代码)
机器学习算法工程师
一个用心的公众号

进群,学习,得帮助
你的关注,我们的热度,
我们一定给你学习最大的帮助
 你点的每个赞,我都认真当成了喜欢
你点的每个赞,我都认真当成了喜欢