TensFlow深度学习(DNN)实现MNIST手写图片识别
许多开发者向新手建议:如果你想要入门机器学习,就必须先了解一些关键算法的工作原理,然后再开始动手实践。但我不这么认为。
我觉得实践高于理论,新手首先要做的是了解整个模型的工作流程,数据大致是怎样流动的,经过了哪些关键的结点,最后的结果在哪里获取,并立即开始动手实践,构建自己的机器学习模型。至于算法和函数内部的实现机制,可以等了解整个流程之后,在实践中进行更深入的学习和掌握。
那么问题来了,既然作为初学者不需要掌握算法细节,但实现模型的过程中又必须用到相关算法,怎么办呢?答案就是借助TensorFlow。
TensorFlow是谷歌开源的一个非常强大的用来做大规模数值计算的库。其所擅长的任务之一就是实现以及训练神经网络。
当我们开始学习编程的时候,第一件事往往是学习打印"Hello World"。就好比编程入门有Hello World,机器学习入门有MNIST。MNIST是一个入门级的计算机视觉数据集,它包含各种手写数字图片:

每一张图片包含28X28个像素点。我们可以用一个数字数组来表示上图中数字为7的图片:

我们把这个数组展开成一个向量,长度是 28x28 = 784。如何展开这个数组(数字间的顺序)不重要,只要保持各个图片采用相同的方式展开。从这个角度来看,MNIST数据集的图片就是在784维向量空间里面的点。
因此,在MNIST训练数据集中,mnist.train.images 是一个形状为 [60000, 784] 的张量,第一个维度数字用来索引图片,第二个维度数字用来索引每张图片中的像素点。在此张量里的每一个元素,都表示某张图片里的某个像素的强度值,值介于0和1之间。

现在,我们准备好可以开始构建我们的模型啦!
1、准备数据
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
可能会报错,如下:
URLError:
解决办法有三个:
- 科学上网,这样应该没有问题。
- 直接下载数据集,下载地址:http://yann.lecun.com/exdb/mnist/
train-images-idx3-ubyte.gz 训练集图片 - 55000 张 训练图片, 5000 张 验证图片
train-labels-idx1-ubyte.gz 训练集图片对应的数字标签
t10k-images-idx3-ubyte.gz 测试集图片 - 10000 张 图片
t10k-labels-idx1-ubyte.gz 测试集图片对应的数字标签
然后把文件存放到同级工程目录MNIST_data下,再执行以下代码:
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets(‘./MNIST_data’, one_hot=True)
- 修改一个py文件,文件路径:Python36\Lib\site-packages\tensorflow\contrib\learn\python\learn\datasets\mnist.py,修改变量DEFAULT_SOURCE_URL
# CVDF mirror of http://yann.lecun.com/exdb/mnist/
#DEFAULT_SOURCE_URL = 'https://storage.googleapis.com/cvdf-datasets/mnist/'
DEFAULT_SOURCE_URL = 'http://yann.lecun.com/exdb/mnist/'
2、构建神经网络
一个最简单的训练网络结构,只有输入层和输出层,如图:
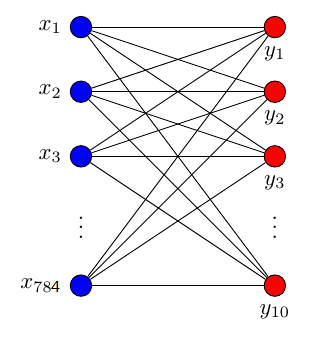
其中输入数据是784个特征,输出数据是10个特征,激活函数采用softmax函数。
prediction = add_layer(xs, 784, 10, activation_function=tf.nn.softmax)
3、定义损失函数
loss函数(即损失函数)选用交叉熵函数。交叉熵用来衡量预测值和真实值的相似程度,如果完全相同,它们的交叉熵等于零。公式如下:
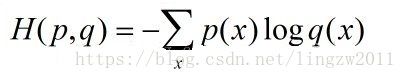
其中p(x)在机器学习中为样本label,q(x)为模型的预估,分别代表训练样本和模型的分布。
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction), reduction_indices=[1]))
4、梯度下降法

首先来看看梯度下降的一个直观的解释。比如我们在一座大山上的某处位置,由于我们不知道怎么下山,于是决定走一步算一步,也就是在每走到一个位置的时候,求解当前位置的梯度,沿着梯度下降的方向,也就是当前最陡峭的位置向下走一步,然后继续求解当前位置梯度,向这一步所在位置沿着最陡峭最易下山的位置走一步。这样一步步的走下去,一直走到觉得我们已经到了山脚。当然这样走下去,有可能我们不能走到山脚,而是到了某一个局部的山峰低处。
所以梯度下降法就是沿梯度下降的方向求解极小值。
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
5、训练模型
每次只取100张图片,免得数据太多训练太慢。
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={xs: batch_xs, ys: batch_ys})
6、评估模型
首先让我们找出那些预测正确的标签。tf.argmax 是一个非常有用的函数,它能给出某个tensor对象在某一维上的其数据最大值所在的索引值。由于标签向量是由0,1组成,因此最大值1所在的索引位置就是类别标签,比如tf.argmax(y,1)返回的是模型对于任一输入x预测到的标签值,而 tf.argmax(y_,1) 代表正确的标签,我们可以用 tf.equal 来检测我们的预测是否真实标签匹配(索引位置一样表示匹配)。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
这行代码会给我们一组布尔值。为了确定正确预测项的比例,我们可以把布尔值转换成浮点数,然后取平均值。例如,[True, False, True, True] 会变成 [1,0,1,1] ,取平均值后得到 0.75.
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
最后,我们计算所学习到的模型在测试数据集上面的正确率,每训练50次输出一次。
if i % 50 == 0:
print(compute_accuracy(
mnist.test.images, mnist.test.labels))
这个最好结果值应该大约是87.47%。
这个结果好吗?并不太好。事实上,这个结果是很差的。这是因为我们仅仅使用了一个非常简单的模型。会在后续的学习中会慢慢改进!
以下是详细的代码:
# -*- coding:utf8 -*-
'''
TensorFlow分类学习
1、准备数据
2、构建神经网络
3、定义损失函数
4、梯度下降法
5、训练模型
6、模型评估
'''
# import tools
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# -----------------------------准备数据-----------------------------
# 数据下载到本地同级目录,下载地址 http://yann.lecun.com/exdb/mnist/
# train-images-idx3-ubyte.gz 训练集图片 - 55000 张 训练图片, 5000 张 验证图片
# train-labels-idx1-ubyte.gz 训练集图片对应的数字标签
# t10k-images-idx3-ubyte.gz 测试集图片 - 10000 张 图片
# t10k-labels-idx1-ubyte.gz 测试集图片对应的数字标签
mnist = input_data.read_data_sets('./MNIST_data', one_hot=True)
# -----------------------------构建神经网络层-----------------------------
# 定义输入输出占位符
xs = tf.placeholder(tf.float32, [None, 784]) # 28x28
ys = tf.placeholder(tf.float32, [None, 10])
def add_layer(inputs, in_size, out_size, activation_function=None):
'''
添加层
这里是784个输入,10个输出
:param inputs:
:param in_size:
:param out_size:
:param activation_function:
:return:
'''
# tf.random_normal 从正态分布中输出随机值,相当于权重值
weights = tf.Variable(tf.random_normal([in_size, out_size]))
# tf.zeros 创建一个数组并初始化它们都为0,然后每个都加0.1,相当于偏差
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)
# tf.matmul矩阵相乘 [100,784]*[784,10]=[100,10],类似方程f(x) = wx + b
equation = tf.matmul(inputs, weights) + biases
# 输出加上激活函数,这里是softmax函数
if activation_function is None:
outputs = equation
else:
outputs = activation_function(equation)
return outputs
# 添加一层神经网络
# tf.nn.softmax Softmax函数,将多个神经元的输出,映射到(0,1)区间内,而这些值的累和为1
prediction = add_layer(xs, 784, 10, activation_function=tf.nn.softmax)
# -----------------------------定义损失函数-----------------------------
# 使用交叉熵公式
# tf.log 取对数
# tf.reduce_sum 压缩求和,用于降维,reduction_indices标识在哪一维上求解,[1]表示按行求和,
# tf.reduce_mean 如果不设置axis,所有维度上的元素都会被求平均值,返回一个只有一个元素的张量。
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction), reduction_indices=[1]))
# -----------------------------梯度下降法-----------------------------
# tf.train.GradientDescentOptimizer 创建一个梯度下降优化器对象,学习速率是0.5
# minimize()函数处理了梯度计算(compute_gradients)和参数更新(apply_gradients)两个操作
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
# -----------------------------模型评估-----------------------------
# 计算精确度的方法
def compute_accuracy(v_xs, v_ys):
global prediction
# 测试特征直接传入模型预测
y_pre = sess.run(prediction, feed_dict={xs: v_xs})
# tf.argmax 返回最大的那个数值所在的下标
# 0是最大的范围,所有的数组都要进行比较
# 1只会比较每个数组内的数的大小,结果也会根据有几个数组,产生几个结果
# tf.equal(A, B)是对比这两个矩阵或者向量的相等的元素,如果相等返回True,否则返回False,返回的值的矩阵维度和A是一样的
correct_prediction = tf.equal(tf.argmax(y_pre,1), tf.argmax(v_ys,1))
# tf.cast 将前面的数据转换为后面的格式.原来的数据格式是bool,将其转化成float以后,就能够将其转化成0和1的序列
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
result = sess.run(accuracy, feed_dict={xs: v_xs, ys: v_ys})
return result
# -----------------------------训练模型-----------------------------
'''
当我们构建完图后,需要在一个会话中启动图,启动的第一步是创建一个Session对象。
为了取回(Fetch)操作的输出内容, 可以在使用 Session 对象的 run()调用执行图时,
传入一些 tensor, 这些 tensor 会帮助你取回结果。
'''
# 创建一个会话,当上下文管理器退出时会话关闭和资源释放自动完成。
sess = tf.Session()
# 初始化模型的参数d
sess.run(tf.global_variables_initializer())
for i in range(1000):
# 每次取100张图片
batch_xs, batch_ys = mnist.train.next_batch(100)
# 训练
sess.run(train_step, feed_dict={xs: batch_xs, ys: batch_ys})
# -----------------------------模型评估-----------------------------
if i % 50 == 0:
print(compute_accuracy(mnist.test.images, mnist.test.labels))
# -----------------------------训练结果-----------------------------
'''
0.1102
0.6597
0.7555
0.7911
0.8134
0.8255
0.8322
0.8406
0.8479
0.8548
0.8535
0.8604
0.8626
0.865
0.8668
0.8694
0.8736
0.8734
0.8701
0.8747
模型准确率最高是87.47%
'''
菜鸟一枚,发表博客的主要目的是为了记录tensorflow机器学习中的点滴,方便自己以后查阅,如果有错误的地方,还请大家多提宝贵意见。