一窥Memory测试算法及自我修复机制
摘要
为了满足新一代设备的需求,Memory的大小每三年就会增加4倍。深亚微米设备包含大量面积更小、访问速度更快的Memory。针对此类设计制定自动测试策略可以减少ATE(自动测试设备)的时间和成本。
内存故障的行为与经典的“Stuck-At”故障不同。因此,Memory的故障模型(由于其阵列结构)与标准逻辑的设计也是不同的。Memory测试除了进行故障检测和定位,还可以实现用冗余单元对故障单元的自修复。
同时,系统级的memory测试需要复用内部memory引脚,并将其引到外部引脚上进行测试,这种复杂操作使测试变得更具有挑战性。对memory进行功能测试或ATPG(自动测试图形向量生成)测试时,由于单元阵列的大小、密度及其相关的故障,要达到可接受的覆盖率通常需要大量的外部逻辑(external pattern sets)。
传统的DFT方法难以满足memory故障测试及其自修复功能的要求。一种有望摆脱此类困境的解决方案是Memory BIST。Memory BIST可以给memory添加测试和修复电路,达成可接受的良品率。本文将对MBIST的体系结构、各种内存故障模型、相关测试算法以及memory自修复机制进行介绍。
导论
由于需要内存系统存储大量数据,存储器构成了VLSI电路的很大一部分。存储器不包括逻辑门和触发器。因此,存储器的故障模型和测试算法也有别于常规测试。
MBIST是一种自测试和修复机制。通过有效的算法检测典型内存单元中可能存在的所有故障,包括卡死(SAF)、过渡延迟故障(TDF)、耦合(CF)或邻域模式敏感故障(NPSF)。使用内置的时钟、地址和数据生成器以及读/写控制器逻辑就可以生成需要的测试向量(test patterns)。
基础memory模型
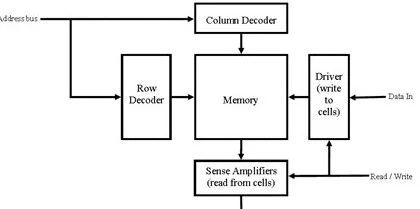
图1. memory模型
典型的存储器模型由二维阵列连接的存储器单元组成,我们需要在阵列结构的背景下分析存储器单元的性能。在阵列结构中,存储单元由两个基本组件组成:“存储节点”和“选择设备”。“选择设备”组件用于在阵列中进行读取/写入时对存储单元进行寻址。这两个组件都会影响内存的扩展。
如上图1所示,通过行和地址解码器确定需要访问的单元地址。根据行和列解码器上的地址,选择相应的行和列连接到感应放大器。感应放大器放大并发送数据。写访问存储单元数据的操作同理。
在存储器测试时,加入特殊电路可以从数据总线向单元中写入值。对于解码器,我们测试地址总线上的地址能否到访问正确单元。对于放大器和驱动器,我们测试是否可以正确地将值传递到单元或从单元传递值。
存储器测试中的常见错误类型:
-
Stuck-At fault:固定型故障,也称为粘着故障
-
Transition fault:跳变故障,也称为转换故障
-
Coupling fault: 耦合故障
-
Neighborhood pattern sensitive fault (NPSF):相邻图形敏感故障
-
Address decoder faults:地址译码故障
MBIST模型
 图2. MBIST模型
图2. MBIST模型
在ATE上测试芯片过程中需要使用外部test pattern作为激励,将被测设备的响应数据,与存储在test pattern中的golden data进行比对。MBIST通过把这些功能放置在芯片本身memory周围的测试电路中来简化上述操作,实现了一个有限状态机(FSM)来生成激励并解析从内存的响应数据。
这种额外的自检电路可以充当系统和内存之间的接口。该接口简化了可控性和可视性,从而将测试内嵌memory的挑战降至最低。有限状态机(FSM)提供用于内存测试的test pattern,大大减少了对外部test pattern集的依赖。
MBIST算法
用于测试RAM和ROM的算法有很多种。下面介绍两个最重要的算法:棋盘算法和March算法。这两种算法“性价比”很高:可以用最少的测试步骤和测试时间检测出最多错误。
棋盘算法
对存储单元进行0和1赋值,保证每个存储单元与相邻存储单元的值不同,这样就将整个存储阵列分成了两部分:A区和B区。棋盘算法主要用于存储单元因漏接、短接和SAF引发的错误。
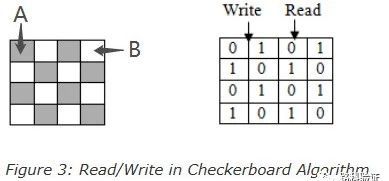
图3. 棋盘算法的读/写
棋盘算法执行步骤如下:
-
A区写入0,B区写入1;(如上图中所示)
-
读存储单元,并验证存储单元的内容是否匹配,如果匹配,则继续,否则,停止并报错;
-
A区写入1,B区写入0;
-
读存储单元,并验证存储单元的内容是否匹配,如果匹配,则继续,否则,停止并报错。
March算法
现存的测试RAM的不同算法中,March算法测试更简单、更快捷,是内存测试中最受欢迎的算法。March算法测试类型多样,覆盖率也各不相同。March测试是在内存地址上下移动,同时将值写入已知内存位置,之后读取。算法还需要确定内存的大小和位宽,来选择最合适的参数模型。
以标准的March1算法为例:该算法包括递增、递减地址,读、写内存单元等10个步骤。可以检测各种内存故障(Stuck-At、Transition、Address faults、Idempotent coupling faults)。
March算法执行步骤如下:
地址递增:
-
初始化写0
-
读0,写1,地址顺序递增
-
读1,写0,地址顺序递增
地址递减:
-
读0,写1,地址顺序降序
-
读1,写0,地址顺序降序
-
按降序读0
当前,大多数行业标准使用March和棋盘格算法的组合,通常称为SMarchCKBD算法。该算法使MBIST控制器能够进行快速行或列访问来检测内存故障。
内存内建自我修复 (BISR,Memory Built-in Self Repair)
memory在SoC中占据很大面积,并且排列紧密(smaller feature size)。因此存储器对芯片良率又重要影响。为了避免良率过低带来的损失,通常会在存储单元中添加冗余或备用的行和列,以便将故障单元重新映射到冗余单元。存储器修复包括行修复,列修复或两者的组合。
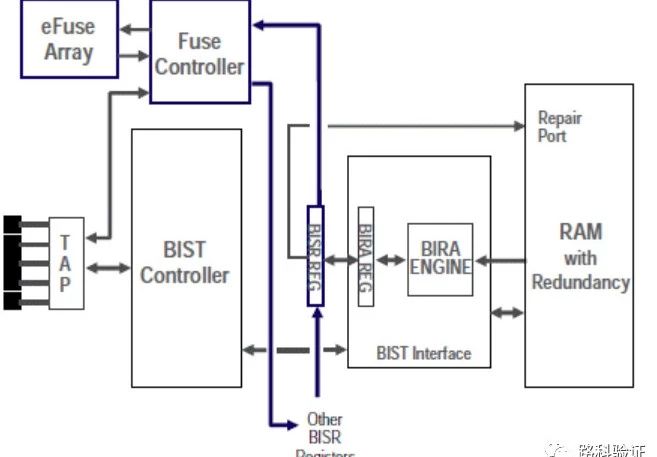 图4. BISR架构
图4. BISR架构
进行内存修复需要两步:首先在可修复内存测试期间,由MBIST控制器诊断出的故障。第二步是修复内存,确认修复签名。可修复的存储器都有带修复签名的寄存器。
BIRA(内置冗余分析)模块有助于基于内存故障数据和已实现的内存冗余方案来计算修复签名、确定存储器在生产测试环境中是否可修复。修复签名将存储在BIRA寄存器中,以供MBIST控制器或ATE进行进一步处理。
修复签名传递给修复寄存器的扫描链,用于后续的芯片级别的Fusebox程序。通过TAP(Test Access Port)控制器可以进行Fusebox的读写访问。修复寄存器的扫描链用来连接memory和fuse。然后,将修复信息从扫描链中扫描出来,进行压缩,即时烧结到eFuse阵列中。
芯片复位时,eFuse中的修复信息会自动加载到修复寄存器中并在其中解压缩,这些寄存器直接连接到memory。这样可以修复所有留有冗余的memory。最后,对修复后的内存进行MBIST测试,以验证内存的正确性。
总结
对高速、高密度memory的研究在持续发展。在未来几年中,摩尔定律将由不断挑战更小尺寸、更多晶体管数量的存储技术所驱动。这无疑将增加测试的复杂性。在不增加成本的情况下应对日益增加的测试复杂度,也是一项严峻的挑战。如本文所述,使用MBIST模型,合适的算法以及内存修复机制(包括BIRA和BISR),不失为一种低成本的有效解决方案。