以太坊源码解读(22)merkle-Patricia Tries(MPT)默克前缀树原理
MPT是以太坊中一种使用很广泛的数据结构,用来管理以太坊账户的状态、状态的变更、交易和收据等。
在以太坊中MPT有以下几个应用的场景:
1、交易树:记录交易的状态和变化。缓存到MTP
2、收据树(交易收据):交易收据的存储
3、状态树(账户信息):帐户中各种状态的保存。如余额等。
4、账户中的Storage树。
这是数据都持有一个接口,即trie Trie:
type Trie struct {
db *Database
root node
cachegen, cachelimit uint16
}Trie结构相当于是一个缓存,最根本的还是以key-Value的形式储存在数据库中,只是在我们运行的时候会从数据库中调用数据重新组装成这个结构,也就是说Trie是当程序运行起来储存在内存中的,而不是在硬盘里的。上面几种树,本质上是一样的,只是value不同而已。交易树的value是交易,收据树的value是receipts,状态树的value是accout{}。
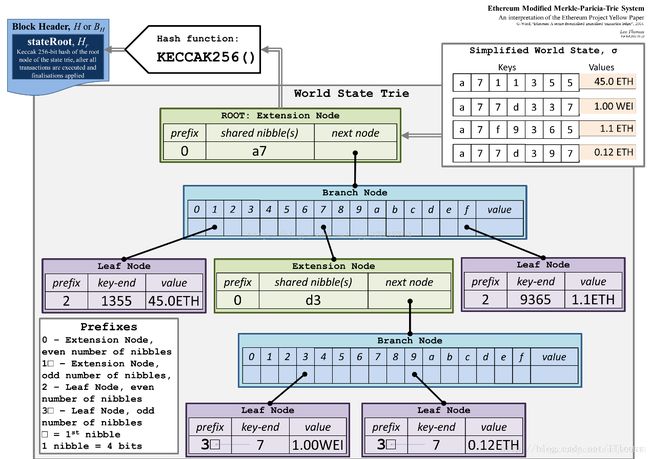
上图是官方对MPT的阐释图,什么意思?这里面有三种节点,扩展节点、分支节点和叶子节点。其中我们最终要存的是【a711355:45.0ETH】、【a77d337:1.00wei】、【a7f9365:1.1ETH】、【a77d397:0.12ETH】这4个键值对:
【叶子节点(leaf)】表示为 [ key,value ] 的一个键值对。key是16进制编码出来的字符串,value是RLP编码的数据;
【扩展节点(extension)】也是 [ key,value ] 的一个键值对,但是这里的value是其他节点的hash值,通过hash链接到其他节点;
【分支节点(branch)】因为MPT树中的key被编码成一种特殊的16进制的表示,再加上最后的value,所以分支节点是一个长度为17的数组。前16个元素对应着key中的16个可能的十六进制字符,如果某个key在这个节点的共享前缀刚好结束,那么这个键值对的value就存在数组的最后一位。
【prefix】prefix是一个4bit的数值,用来区分扩展节点和叶子节点。因为扩展节点和叶子节点的数据结构类似,所以需要进行区分。其中第三位为节点标记,如果是0则表示Extension Node,如果是1则表示leaf Node。最后一位为奇偶性,如果key-end为奇数,则为1,ken-end为偶数则为0。
所以对照上面的图,奇数extension Node的prefix为00010000,偶数extension Node为00000000,key-end为1355的leaf Node的prefix为00100000,key-end为7的leaf Node的prefix为00110000。
MPT节点种类即储存
那么,上面的结构在数据库中是怎么储存的呢?我们先看下在以太坊中这些节点的结构:
type node interface {
fstring(string) string
cache() (hashNode, bool)
canUnload(cachegen, cachelimit uint16) bool
}
type (
fullNode struct {
Children [17]node // Actual trie node data to encode/decode (needs custom encoder)
flags nodeFlag
}
shortNode struct {
Key []byte
Val node
flags nodeFlag
}
hashNode []byte
valueNode []byte
)
type nodeFlag struct {
hash hashNode // cached hash of the node (may be nil)
gen uint16 // cache generation counter
dirty bool // whether the node has changes that must be written to the database
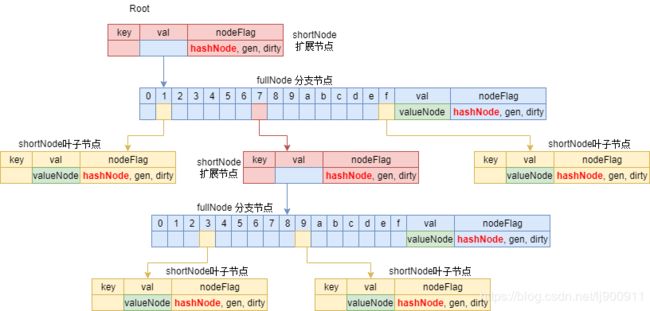
}我们看到这里的fullNode就是图中的分支节点,而shortNode就代表只有一个子节点的节点,也就是叶子节点或扩展节点。叶子节点的子节点是valueNode;而扩展节点的子节点则为一个分支节点,即fullNode。
hashNode与valueNode都是[]byte的别名,长度都是32字节,但储存的内容有很大不同:
1、valueNode储存的是真正value值的hash值,hashNode储存的则是fullNode和shortNode的hash值;
2、valueNode由叶子节点持有,也可以由fullNode的节点持有,储存在children数组的最后一个位置;
3、hashNode由每一个fullNode和shortNode所持有。
最终,value的RLP编码值就以valueNode的[]byte为key储存在数据库中,fullNode和shortNode的RLP编码值也以hashNode为key储存在数据库里。所以所有的节点最终都以[hash,RLPdata]的形式储存在数据库中。
最终的MPT树的根hash以一种类似与merkle树的方式形成,即子节点的hash值组合起来进行hash运算,得到的hash值再与其他同级的hash组合起来再进行hash,以此类推直到最后只有一个hash,即为根hash。通过root hash从数据库中找到root节点,再从root节点恢复出其子节点的hash,再从数据库中取出子节点,以此类推,最终可以恢复整棵树。
不同的是merkle是二叉树,而以太坊中不是二叉树,比如fullNode有可能存在16个子节点,但是处理原理都是讲这些子节点的hash值组合然后进行hash。
源码分析
MPT的序列化和反序列化
先从Trie树的初始化开始,New()函数接受一个根hash值和一个Database参数,初始化一个trie。函数调用了resolveHash()方法,从数据库中取回了rootnode。
func New(root common.Hash, db *Database) (*Trie, error) {
if db == nil {
panic("trie.New called without a database")
}
trie := &Trie{
db: db,
originalRoot: root,
}
if (root != common.Hash{}) && root != emptyRoot {
rootnode, err := trie.resolveHash(root[:], nil)
if err != nil {
return nil, err
}
trie.root = rootnode
}
return trie, nil
}resolveHash()方法旨在通过hash解析出node的RLP值,它在Trie的序列化和反序列化过程中多次使用:
1、New():新建一个树时用于获取根节点;
2、tryGet():通过给定的key去找对应的value,从根节点递归想想查询,当查到了hashNode的时候将该hashNode对应的Node找出来,基于该Node进一步去查询,直到找到valueNode;
3、insert():插入节点遍历到hashNode时,说明该节点还没有被载入内存,此时调用resolveHash取出该Node,进一步执行insert();
4、delete():删除节点遍历到hashNode时,用途与insert()类似。
func (t *Trie) resolveHash(n hashNode, prefix []byte) (node, error) {
cacheMissCounter.Inc(1)
hash := common.BytesToHash(n)
//通过hash解析出node的RLP值
enc, err := t.db.Node(hash)
if err != nil || enc == nil {
return nil, &MissingNodeError{NodeHash: hash, Path: prefix}
}
return mustDecodeNode(n, enc, t.cachegen), nil
}下面我们看看MPT如何序列化和反序列化,即如何编码和解码,又或者说如何储存和读取。
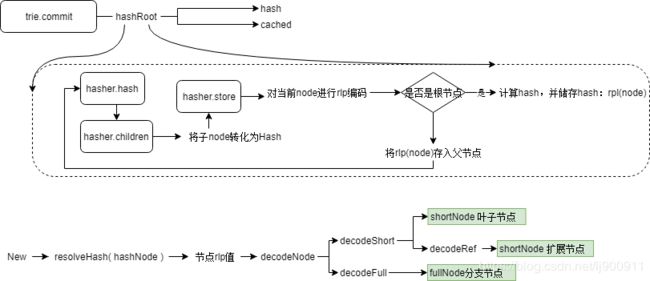
trie.Commit()方法进行序列化并得到一个hash值(root),它的主要流程通过hasher.go中的hash()方法来实现。
func (t *Trie) Commit(onleaf LeafCallback) (root common.Hash, err error) {
if t.db == nil {
panic("commit called on trie with nil database")
}
hash, cached, err := t.hashRoot(t.db, onleaf)
if err != nil {
return common.Hash{}, err
}
t.root = cached // 更新了t.root,将节点的hash值放在了root节点的node.flag.hash中
t.cachegen++
return common.BytesToHash(hash.(hashNode)), nil
}
// 该函数返回的是根hash和存入了hash值的trie的副本
func (t *Trie) hashRoot(db *Database, onleaf LeafCallback) (node, node, error) {
if t.root == nil {
return hashNode(emptyRoot.Bytes()), nil, nil
}
h := newHasher(t.cachegen, t.cachelimit, onleaf)
defer returnHasherToPool(h)
return h.hash(t.root, db, true)
}根hash是通过遍历shortNode和fullNode,将其中的子节点rlp编码值转换为hash值,构成了一个全部由hash组成的树;同时将每个节点的hash值存入每个节点的node.flag.hash中,构成了一个包含了hash的副本Trie,并传给cache。hash和cache就是我们所需要的。
这里hash()方法是关键。hash()方法是所谓“折叠”的入口,即将node折叠为hash。它的基本逻辑是:
1、从root节点开始,调用hashChildren()将子节点折叠成hashNode,替换到子节点原来所在父节点中的位置,直到所有的子节点都变为hash值;
2、上面的过程是一个递归调用,通过hash()调用hashChildren(),hashChildren()判断如果不是valueNode则递归调用hash(),这样使得整个折叠的过程从valueNode开始,最后终结于root。
3、调用store()方法对这个全部由子节点hash组成的node进行RLP编码,并进行哈希计算,得到该节点的hashNode;同时以hashNode为key,以本node的RLP编码的值为value存入数据库。
func (h *hasher) hash(n node, db *Database, force bool) (node, node, error) {
// If we're not storing the node, just hashing, use available cached data
if hash, dirty := n.cache(); hash != nil {
if db == nil {
return hash, n, nil
}
if n.canUnload(h.cachegen, h.cachelimit) {
cacheUnloadCounter.Inc(1)
return hash, hash, nil
}
if !dirty {
return hash, n, nil
}
}
// 对所有子节点进行处理,将本节点中所有的节点都替换为节点的hash
collapsed, cached, err := h.hashChildren(n, db)
if err != nil {
return hashNode{}, n, err
}
// 将hash和rlp编码的节点存入数据库
hashed, err := h.store(collapsed, db, force)
if err != nil {
return hashNode{}, n, err
}
cachedHash, _ := hashed.(hashNode)
switch cn := cached.(type) {
case *shortNode:
cn.flags.hash = cachedHash
if db != nil {
cn.flags.dirty = false
}
case *fullNode:
cn.flags.hash = cachedHash
if db != nil {
cn.flags.dirty = false
}
}
return hashed, cached, nil
}上面是将Trie存入数据库,下面再看看如何从数据库中取出节点,重构Trie。上面的resolveHash() 方法中通过db.Node(hash)取值指定hash的node的RLP值。
decodeNode方法,这个方法根据rlp的list的长度来判断这个编码到底属于什么节点,如果是2个字段那么就是shortNode节点,如果是17个字段,那么就是fullNode,然后分别调用各自的解析函数。
// decodeNode parses the RLP encoding of a trie node.
func decodeNode(hash, buf []byte, cachegen uint16) (node, error) {
if len(buf) == 0 {
return nil, io.ErrUnexpectedEOF
}
elems, _, err := rlp.SplitList(buf)
if err != nil {
return nil, fmt.Errorf("decode error: %v", err)
}
switch c, _ := rlp.CountValues(elems); c {
case 2:
n, err := decodeShort(hash, buf, elems, cachegen)
return n, wrapError(err, "short")
case 17:
n, err := decodeFull(hash, buf, elems, cachegen)
return n, wrapError(err, "full")
default:
return nil, fmt.Errorf("invalid number of list elements: %v", c)
}
}decodeShort方法,通过key是否有终结符号来判断到底是叶子节点还是扩展节点。如果有终结符那么就是叶子结点,通过SplitString方法解析出来val然后生成一个shortNode。 不过没有终结符,那么说明是扩展节点, 通过decodeRef来解析剩下的节点,然后生成一个shortNode。
func decodeShort(hash, buf, elems []byte, cachegen uint16) (node, error) {
// kbuf代表compact key
// rest代表shortnode的value
kbuf, rest, err := rlp.SplitString(elems)
if err != nil {
return nil, err
}
flag := nodeFlag{hash: hash, gen: cachegen}
key := compactToHex(kbuf)
if hasTerm(key) {
// value node
val, _, err := rlp.SplitString(rest)
if err != nil {
return nil, fmt.Errorf("invalid value node: %v", err)
}
return &shortNode{key, append(valueNode{}, val...), flag}, nil
}
r, _, err := decodeRef(rest, cachegen)
if err != nil {
return nil, wrapError(err, "val")
}
return &shortNode{key, r, flag}, nil
}decodeRef方法根据数据类型进行解析,如果类型是list,那么有可能是内容<32的值,那么调用decodeNode进行解析。 如果是空节点,那么返回空,如果是hash值,那么构造一个hashNode进行返回,注意的是这里没有继续进行解析,如果需要继续解析这个hashNode,那么需要继续调用resolveHash方法。 到这里decodeShort方法就调用完成了。
func decodeRef(buf []byte, cachegen uint16) (node, []byte, error) {
kind, val, rest, err := rlp.Split(buf)
if err != nil {
return nil, buf, err
}
switch {
case kind == rlp.List:
// 'embedded' node reference. The encoding must be smaller
// than a hash in order to be valid.
// len(buf) - len(rest)得到的结果应该是类型加内容的长度
if size := len(buf) - len(rest); size > hashLen {
err := fmt.Errorf("oversized embedded node (size is %d bytes, want size < %d)", size, hashLen)
return nil, buf, err
}
n, err := decodeNode(nil, buf, cachegen)
return n, rest, err
case kind == rlp.String && len(val) == 0:
// empty node
return nil, rest, nil
case kind == rlp.String && len(val) == 32:
return append(hashNode{}, val...), rest, nil
default:
return nil, nil, fmt.Errorf("invalid RLP string size %d (want 0 or 32)", len(val))
}
}
decodeFull方法。根decodeShort方法的流程差不多。
func decodeFull(hash, buf, elems []byte, cachegen uint16) (*fullNode, error) {
n := &fullNode{flags: nodeFlag{hash: hash, gen: cachegen}}
for i := 0; i < 16; i++ {
cld, rest, err := decodeRef(elems, cachegen)
if err != nil {
return n, wrapError(err, fmt.Sprintf("[%d]", i))
}
n.Children[i], elems = cld, rest
}
val, _, err := rlp.SplitString(elems)
if err != nil {
return n, err
}
if len(val) > 0 {
n.Children[16] = append(valueNode{}, val...)
}
return n, nil
}MPT的增删查
insert()
delete()
tryGet()
insert()
Trie树的插入,这是一个递归调用的方法,从根节点开始,一直往下找,直到找到可以插入的点,进行插入操作。
参数:
1、node是当前插入的节点;
2、prefix是当前已经处理完的部分key
3、key是还没有处理玩的部分key, 完整的key = prefix + key;
4、value是需要插入的值。
返回值:
1、bool是操作是否改变了Trie树(dirty);
2、node是插入完成后的子树的根节点;
3、error是错误信息;
流程:
1、如果节点类型是nil(一颗全新的Trie树的节点就是nil的),这个时候整颗树是空的,直接返回shortNode{key, value, t.newFlag()}, 这个时候整颗树的跟就含有了一个shortNode节点。
2、如果当前的根节点类型是shortNode(也就是叶子节点),
a. 计算公共前缀,如果公共前缀就等于key,那么说明这两个key是一样的,如果value也一样的(dirty == false),那么返回错误;
b. 如果没有错误就更新shortNode的值然后返回。如果公共前缀不完全匹配,那么就需要把公共前缀提取出来形成一个独立的节点(扩展节点),扩展节点后面连接一个branch节点,branch节点后面看情况连接两个short节点。首先构建一个branch节点(branch := &fullNode{flags: t.newFlag()}),然后再branch节点的Children位置调用t.insert插入剩下的两个short节点。
3、如果当前的节点是fullNode(也就是branch节点),那么直接往对应的孩子节点调用insert方法,然后把对应的孩子节点只想新生成的节点。
4、如果当前节点是hashNode, hashNode的意思是当前节点还没有加载到内存里面来,还是存放在数据库里面,那么首先调用 t.resolveHash(n, prefix)来加载到内存,然后对加载出来的节点调用insert方法来进行插入。
func (t *Trie) insert(n node, prefix, key []byte, value node) (bool, node, error) {
if len(key) == 0 {
if v, ok := n.(valueNode); ok {
return !bytes.Equal(v, value.(valueNode)), value, nil
}
return true, value, nil
}
switch n := n.(type) {
case *shortNode:
matchlen := prefixLen(key, n.Key)
// If the whole key matches, keep this short node as is
// and only update the value.
if matchlen == len(n.Key) {
dirty, nn, err := t.insert(n.Val, append(prefix, key[:matchlen]...), key[matchlen:], value)
if !dirty || err != nil {
return false, n, err
}
return true, &shortNode{n.Key, nn, t.newFlag()}, nil
}
// Otherwise branch out at the index where they differ.
branch := &fullNode{flags: t.newFlag()}
var err error
_, branch.Children[n.Key[matchlen]], err = t.insert(nil, append(prefix, n.Key[:matchlen+1]...), n.Key[matchlen+1:], n.Val)
if err != nil {
return false, nil, err
}
_, branch.Children[key[matchlen]], err = t.insert(nil, append(prefix, key[:matchlen+1]...), key[matchlen+1:], value)
if err != nil {
return false, nil, err
}
// Replace this shortNode with the branch if it occurs at index 0.
if matchlen == 0 {
return true, branch, nil
}
// Otherwise, replace it with a short node leading up to the branch.
return true, &shortNode{key[:matchlen], branch, t.newFlag()}, nil
case *fullNode:
dirty, nn, err := t.insert(n.Children[key[0]], append(prefix, key[0]), key[1:], value)
if !dirty || err != nil {
return false, n, err
}
n = n.copy()
n.flags = t.newFlag()
n.Children[key[0]] = nn
return true, n, nil
case nil:
return true, &shortNode{key, value, t.newFlag()}, nil
case hashNode:
// We've hit a part of the trie that isn't loaded yet. Load
// the node and insert into it. This leaves all child nodes on
// the path to the value in the trie.
rn, err := t.resolveHash(n, prefix)
if err != nil {
return false, nil, err
}
dirty, nn, err := t.insert(rn, prefix, key, value)
if !dirty || err != nil {
return false, rn, err
}
return true, nn, nil
default:
panic(fmt.Sprintf("%T: invalid node: %v", n, n))
}
}Trie树的Get方法,基本上就是很简单的遍历Trie树,来获取Key的信息。
func (t *Trie) tryGet(origNode node, key []byte, pos int) (value []byte, newnode node, didResolve bool, err error) {
switch n := (origNode).(type) {
case nil:
return nil, nil, false, nil
case valueNode:
return n, n, false, nil
case *shortNode:
if len(key)-pos < len(n.Key) || !bytes.Equal(n.Key, key[pos:pos+len(n.Key)]) {
// key not found in trie
return nil, n, false, nil
}
value, newnode, didResolve, err = t.tryGet(n.Val, key, pos+len(n.Key))
if err == nil && didResolve {
n = n.copy()
n.Val = newnode
n.flags.gen = t.cachegen
}
return value, n, didResolve, err
case *fullNode:
value, newnode, didResolve, err = t.tryGet(n.Children[key[pos]], key, pos+1)
if err == nil && didResolve {
n = n.copy()
n.flags.gen = t.cachegen
n.Children[key[pos]] = newnode
}
return value, n, didResolve, err
case hashNode:
child, err := t.resolveHash(n, key[:pos])
if err != nil {
return nil, n, true, err
}
value, newnode, _, err := t.tryGet(child, key, pos)
return value, newnode, true, err
default:
panic(fmt.Sprintf("%T: invalid node: %v", origNode, origNode))
}
}