ESP32开发(6)esp-adf:百度语音识别
前言
本例程基于官方例程esp-adf/example/speech_recognition/asr修改而来。asr例程是一个本地语音识别例程,已经帮助我们读取到了所需要的原始语音数据,我们只要稍作修改,将它通过HTTP协议上传到百度语音识别接口,就可以实现语音识别啦。
准备工作
开发环境:Linux-Ubuntu16
开发平台:ESP32_LyraT开发板。这款开发板上面的模组是ESP32-WROVER,额外带有4M RAM,可以用来缓存语音数据。
获取Access Token
在百度开发者平台上创建一个语音识别应用,具体操作参考百度语音合成例程,我这里语音识别和语音合成是一个应用,记录下API key和Secret Key。在Linux中创建一个shell脚本,输入以下命令:
#!/bin/bash
curl -i -k 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=******&client_secret=******' >>receive_token.json
其中"client_id"是API key,"client secret"是Secret Key,执行脚本,在重定向生成的receive_token.json文件中找"access_token"这一项,记录下后面那一长串字符。注意:这个access_token只有一个月的有效期,需要定期更新。
实现思路
在实现之前,建议先阅读一下百度的官方语音识别文档REST API,了解一下两种上传方式的区别,我们采用RAM方式上传,不用计算JSON,节省内存开销。
因为asr例程是本地语音识别,所以我们还需要往程序中添加一些其他组件,比如基本的wifi连接配置,HTTP客户端配置,这些我们就不做讨论了。我们直接来看改动的主要部分。
while (1)
{
if(get_key_value() == 0)
{
char *buff = (char *)heap_caps_malloc(96 * 1024, MALLOC_CAP_SPIRAM);
if (NULL == buff)
{
ESP_LOGE(EVENT_TAG, "Memory allocation failed!");
return;
}
memset(buff, 0, 96 * 1024);
ESP_LOGI(TAG, "have key");
for(size_t i = 0; i < 12; i++)
{
raw_stream_read(raw_read, (char *)buff + i * 8 * 1024, 8 * 1024);
}
esp_http_client_config_t config =
{
.url = "http://vop.baidu.com/server_api?dev_pid=1536&cuid=ESP32_HanChenen521&token=24.5af78a8f13afcd9a592624865bbd5eac.2592000.1562320078.282335-15514068",
.event_handler = _http_event_handler,
};
esp_http_client_handle_t client = esp_http_client_init(&config);
esp_http_client_set_method(client, HTTP_METHOD_POST);
esp_http_client_set_post_field(client, (const char *)buff, 96 * 1024);
esp_http_client_set_header(client, "Content-Type", "audio/pcm;rate=16000");
esp_err_t err = esp_http_client_perform(client);
if (err == ESP_OK)
{
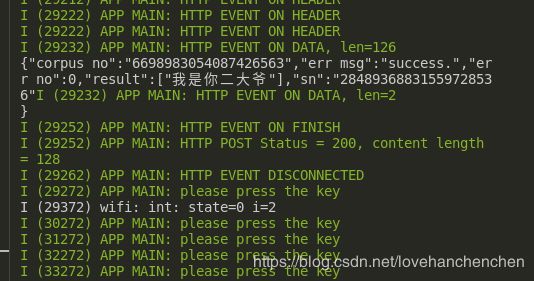
ESP_LOGI(TAG, "HTTP POST Status = %d, content_length = %d",
esp_http_client_get_status_code(client),
esp_http_client_get_content_length(client));
}
else
{
ESP_LOGE(TAG, "HTTP POST request failed: %s", esp_err_to_name(err));
}
esp_http_client_cleanup(client);
free(buff);
buff = NULL;
}
ESP_LOGI(TAG, "please press the key");
vTaskDelay(100);
首先判断按键是否按下,按下后开始录音。要使用外部RAM,需用heap_caps_malloc()函数来分配内存,16KHz的16位单声道音频数据每秒钟字节数是32K,我们要录制3秒的话就得分配96K字节的内存,因为前面raw流配置的缓冲buff是8*1024,所以我们需要循环读取12次,才能将所有数据读入外部RAM,循环读入的时候注意移动指针。然后根据百度官方文档配置HTTP请求参数,上传音频数据,最终得到正确的返回结果。
注:程序中的token大概在7月份过期,目前还可以用。
写的比较匆忙,有疑问的地方大家可以留言评论,到后面还会继续更新其他实用的ESP32应用,欢迎大家持续关注以及批评指正。
目前,正在建设自己的git仓库,后面会把有关程序开源到git上,敬请期待。。。