基于Web开发模式的信息抽取
基于Web 开发模式的信息抽取
李海波 2010-12-27
说明:转载请注明作者和出处;未经许可,不得在平面媒体上发表。 这是本人在信息抽取方面的一些心得和总结,希望对于有志于互联网Web信息抽取的朋友一点启发,有任何问题可以发邮件给我或者加我msn一起讨论。
信息抽取是一个互联网自然语言处理的一个首要环节,信息抽取的准确度会直接影响到后续的处理。信息抽取的目标是去除噪音,获取网页有价值的信息如网页的标题、时间、正文、链接等信息。
主流算法介绍
网页信息抽取的方法有很多,比如从算法上分:基于模板的,基于信息量、基于视觉的、基于语义挖掘的、基于统计的。从HTML 处理上分为:基于行块、基于DOM 树。下面我逐一介绍。
1. 基于模板,一般由人工维护一个URL 和HTML 的模板。当URL 匹配到某个URL 模板时,利用对应的HTML 的模板来抽取其中的信息。这种方法见效快、准确度高,抓取少量站可以使用,可以做一些模板设置工具来减少工作量,大量站需要较多人力维护模板列表。
2. 基于信息量(信息量的解释我下面会说),见基于行块分布函数的正文抽取 ,计算正文在源码哪些行上分布较多,取正文较多的行;另外,也有算法是根据行的正文密度来计算的,简单点说就是正文长度/ 标签数量。基于信息量也有另一种方法,就是建立Dom 树,把行函数变为Dom 树上某个节点的评估函数。对于资讯类网站,这个方法会工作得很好,但是需要考虑到抽取网页信息并不代表文字多就好,比如正文下有一段版权信息或者网站说明,如何去除这些信息?另外,游戏下载网站分为游戏的结构化信息、描述信息、游戏操作说明等部分,信息是分散的,而不是集中的,这类信息如何处理?
3. 基于基于视觉的页面分割算法 ,是基于分块的算法的一种具体实现方式,这是微软亚洲研究院的一个算法,用于微软搜索引擎Bing 上。我比较喜欢这个算法,因为提出了两个好的想法:一是根据视觉来分块,二是根据视觉来进行块合并。基于视觉处理较复杂,需要用到CSS 、Javascript 等引擎,需要用浏览器内核库来处理HTML ,性能可能不高。另外,这个算法的结果只是告诉大家网页大概可以分为多少块,每一块的位置、大小是什么,而哪块和哪块是正文还需要进一步计算。
4. 基于语义的正文抽取,根据锚文本和页面标题等不容易出错的信息去发现正文块,这类算法有效,但是仍有局限性。
5. 基于统计的,基于分块和统计相结合的新闻正文抽取 和 基于同层网页相似性去除网页噪音 。前者利用统计是找到同一网页里面的正文块,后者是链接同一路径下的不同网页的相似度去除噪音,两者是有区别的。基于统计,可以减少个别网页的差异带来的误差,提高准确度。
站在Web 开发者角度考虑
以上的这些方法,都是从网页中的规律考虑,能解决一部分问题,而问题的根源是Web 页面是Web 工程师开发出来的,研究他们的Web 开发习惯和模式对于信息抽取是最根本的,而本人则做过Web 开发,所以总结出来几个对信息抽取有用的几个模式:
模式1 :同类页面用一套模板。互联网的网站,大体上分为CMS 系统(如帝国CMS )、博客系统(如Wordpress )、论坛系统(如Discuzz ),不管是什么系统,同一类的网页都是根据相同的模板和后台数据生成的静态或动态页面,结构上是一样的,而内容是不一样的。如果有改版,也是统一修改,纯手工制作的页面已经很少了。
模式2 :不同功能的信息用块标签。凡是分块的都用块标签(组标签),HTML 的标签中具有块属性的有DIV 、TABLE 、FORM 、CENTER 、UL 、LI 等。
模式3 :重复结构用循环。 列表数据、论坛、博客评论,一般都是获取数据行,然后根据行进行循环输出。
模式4 :按照信息来组织块。一是样式上有区分,导航、正文、相关文章、评论、左侧导航、右侧广告样式都有区别;而回帖、回复的样式都是一样的。二是块之间越相关,块就挨的越近,正文、相关文章、评论就挨的很近,而正文离右侧广告就很远。
模式5 :不管是Web 开发者水平不高,还是网站比较流氓,很多正文并不干净,恨不得广告中夹点正文。
根据以上的分析,结合上面的一些参考算法,提出了基于Web 开发模式的信息抽取算法,这个算法可以很通用的解决信息抽取中的准确度和干净度的问题。注:准确度 指正文完整;干净度 指正文中不包含噪音。
基于Web 开发模式的信息抽取的算法描述
1. 根据“模式1 “收集同一域名或者路径下的n 个(n>=1 )网页,同一域名或者路径下的网页具有同一模板的可能性较高。如果n=1 ,则退化为单个网页的信息抽取,单个网页抽取,对于快讯、短博客抽取难度大,如果有一组网页合并后抽取则可以较好的解决这个问题。
2. 根据“模式2 “分别按照HTML 的块标签建立n 个Dom 树。这棵树不是所有的HTML 标签都是一个节点,只有块标签的可视节点 才能建立一个节点,既能满足信息抽取需要,又能提高效率。下图是建立的5 个Dom 树。
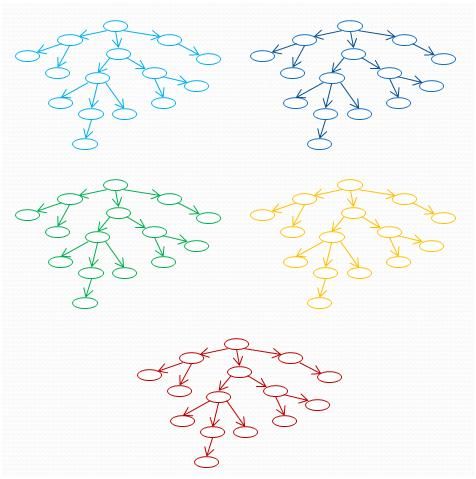
图1
3. 判断这n 个Dom 是否相似,主要是选取Dom 树的上各分支较高层数的节点来判断其结构是否相似,取相似的Dom 树合并其节点特征,可能n 个Dom 属于多个模板,则可以合并多个Dom 树,逐一计算即可。特征为:正文长度、链接数量、链接中文本长度、图片大小、标签数量。假设合并后的Dom 树为D 。如果某个路径的节点在不同的Dom 树中,其特征完全一样,则此节点可被忽略(去掉版权、网站说明等重复噪音信息)。
4. 根据“模式4 “,对D 进行相似正文块的合并,比如图2 中,节点7 下面有10 、11 、12 都是正文块(可以根据节点特征来计算),具有相同的父节点,则可以合并到节点7 。这一步主要是有某些博客或者网站,其正文分布在几个块中,如果不进行合并,则抽取的正文会不全。
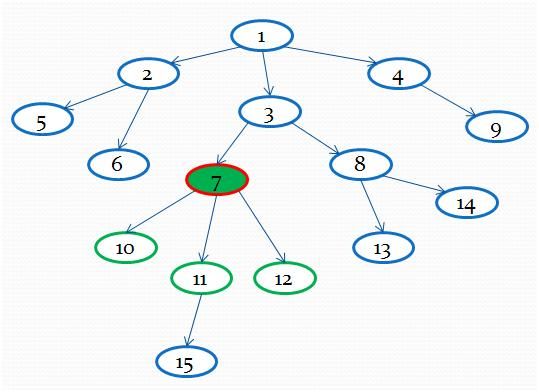
图2
5. 根据“模式3 “,对D 中循环连续的块进行合并,这一类主要是针对评论、论坛的信息,如图3 ,节点2 、3 、4 、5 、6 是相同结构的节点,合并为节点2 。如果不合并,则会抽取到其中的一小块,导致信息不全。同时,对于循环连续块,需要有一个降权的处理,某些博文和评论,评论的权重会比博文大,不降权,会抽取到评论而不是博文。
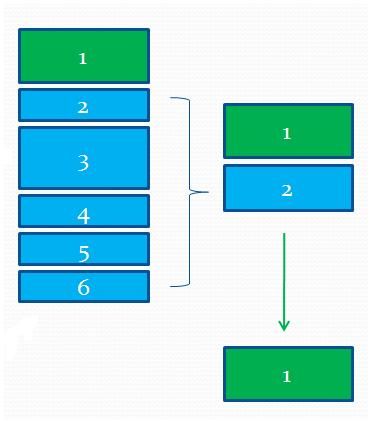
图3
6. 找到信息量最大的块。这里解释一下信息量的概念,信息量是由文字、链接、图片、视频、动画以及他们的样式传达给使用者的信息的量化标准 。说白了,就是网页想给用户什么信息,内容页给用户的是内容,而导航页给用户的是链接,信息量的计算公式是不一样的。图4 是一个网页的结构,根节点1 下面有3 个节点:2 、3 、4 ;根据信息量计算公式,节点3 信息量最大,取节点3 ;节点3 下有7 、8 两个节点,7 最大;7 下面是11 ,所以取节点11 为正文节点。为什么不取节点15 呢,有两种可能,一种是节点15 在第4 步中已经被合并到节点11 上了,另外一种是节点15 信息量占节点11 的信息量比太少,不会被选择。
信息量公式 = 正文信息 + 链接信息 + 图片信息 + 视频(包括Flash )信息 + 标签信息
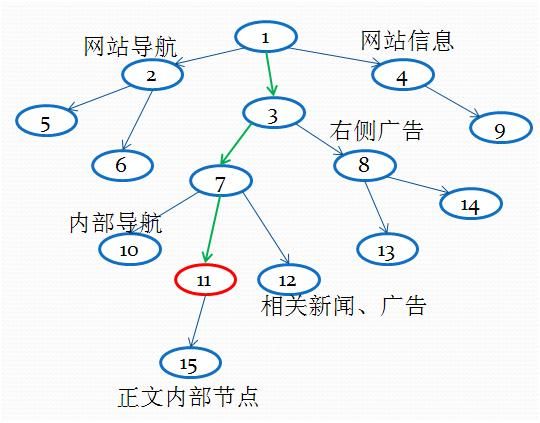
图4
7. 根据“模式5 “,找到了正文节点只是说明正文是包含在正文节点中,找到的正文节点中依然包含噪音,比如正文块中夹杂广告信息,比如正文块中包含太多相关链接信息等等。这时候,需要对于正文块进行进一步的清洗,剔除噪音信息。对于论坛,如果只需要帖子本身的信息,而不要用户信息,可以根据论坛回帖重复的特点,计算每个回复块中各个块的信息量方差,方差大的为帖子块(因为帖子的长度差别很大),方差小的是用户信息块(用户信息块差异较小)。
算法优势分析
1. 用组标签以及标签中css进行分块,代替VIPS中的颜色、大小、位置等信息,简化了计算过程,效率较高,这么计算,在实际应用中效果也较好。如果能把颜色、位置、大小因素考虑进去,会更进一步提高准确率。是否需要处理css,看实际需要。
2. 利用同一个模板下不同页面的结构相似性,和页面内循环块的相似性,来进行信息提取,比单一的页面,单一的块进行信息提取,其准确率的提升在3%以上(估计值)。比如快讯(只有一句话)较难处理,比如只提取论坛中的帖子内容(左侧个人信息、签名档都不要),比如提取博文而不要评论等...,通过观察一组相似结构来处理信息 ,这个思路可以延伸到其他类型的页面信息提取。
3. 算法较通用,只需要根据不同的算法把类似的块进行合并以及设计合理的信息量公式,可以为不同的应用场景提供各类提取后的信息,比如提取文本、图片和视频,链接和结构化的内容。
4. 更进一步的优化,在结构相似性的基础上,可以把网页结构的特征和网页信息模板 保留下来,以备无法提取信息的网页使用,特别是对于论坛和博客等回帖数不固定的页面更是重要。
实际应用效果
实际应用中,正文抽取部分,对于上万个站点(包括资讯、博客、论坛站点)的数据抽样进行检测,准确率能达到96% 以上。
此算法用于HUB 的链接分析部分,分析HUB 页中的需要爬取的网页链接,不包含左右两侧的热门、导航等链接,几万个Hub 页测试,其准确率也达到了92% 。-- 如果把块的位置考虑进去,效果会更好。
信息提取时的其他一些问题
标签容错性: 本算法不识别Attribute的内容,不识别CSS和Script的内容,只需要处理标签匹配即可,即便是标签匹配错误也无所谓,只要能提取信息即可。
编码识别:可以提取header中的charset,如果没有则可以用mozilla的charset探测组件来自动识别。编码建议都转为utf-8。
语言识别:可以利用utf-8的中日韩的编码区间来计算字符的分布在哪个语言区间的概率来判别。
标题提取和净化:锚文本和title相结合,根据规则截断标题,把“_新闻中心_新浪网”等无意义的去掉,也可以根据相似网页的标题共同部分去掉来截取。
日期时间识别:正文区域上下不远的地方,用正则来匹配即可。如果有多个时间,可以取大于某个时间(2000年以后?)离现在最近的但不超过当前时间的时间。
图片提取:提取正文区域的大图片链接,图片的介绍文字可以提取图片下方的文字或者图片周围的文字以及标题的文字。
链接提取:提取链接最多的块,如果链接+简介+缩略图的HUB页,可以把文字和图片作为权重计算进去。HUB页也是形式多样,难度不比正文提取小。
其他:以后想到再补充
附录:下面是文档部分,一并共享之,供参考。
基于Web开发模式的信息抽取
Web Page Information Extractor