2019中兴迪杰斯特拉比赛回顾与分析
1.赛题信息
已知条件:
1) 有一网格状拓扑(25*20,数据见gridtopo.txt),现在需要组建长期运输网;拓扑中链路的最大容量(最大承受带宽)已知;链路的单位质量业务的传输成本已知;
2) 有1000种蚁穴到蚁穴(源节点到终节点)的业务需要运输,每种业务的质量(带宽)已知;
3) 蚁巢王国在最初建立之时,城市规划师为每两个蚁穴之间规划了3条备选通道,用于蚁穴之间互访。即每种业务有3条备用通道供业务传输(每条路径由多段链路组成的,数据见request.txt),可是,随着时代的变迁,这些备选通道可能会存在不合理的地方,于是在业务传输的时候,小蚁们可以自己决定是否要选择合适的路径计算算法来计算新的路径进行传输,并不需要局限于当前的3条路径;
4 ) 每种业务需要从自己的备选通道(路径)或者新计算出的路径中选出一条有效路径完成业务传输,且该业务的传输成本可定义为:业务质量*路径传输单位质量业务成本,后者的定义为:路径上面包含的所有链路的单位质量业务的传输成本之和;
5 ) 每条链路被业务占用的容量(带宽)之和不能超过该链路的最大承受带宽的80%。
特别说明
1)同一条链路认为是双向的,即存在A->B和B->A两个方向,且互不影响,它们有各自的链路带宽,并假定带宽值相同;
2)两个网络节点之间最多仅存在一条链路,链路上下行方向的带宽相互独立互不影响且相同。例如对于节点A与B之间的链路,该条链路的带宽为1G,则表示A->B,B->A两个方向上的网络带宽分别为1G。
待解决问题:
如何从全局角度考虑,给每种业务选择一条通道(路径),在满足所有链路传输带宽要求(不超过80%)的情况下,使得1000种业务总的传输成本之和最小?(具体见下文评分机制).
2.程序输入与输出
网络拓扑如图所示:
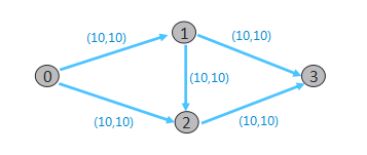
输入文件示例:
- gridtopo.txt(网络拓扑数据)
4 5 //注:4个网络节点,5条链路
0 1 10 10 //注:链路起始网络节点ID为0,链路终止网络节点为1,最大承受带宽为10,单位质量业务传输成本为10
0 2 10 10
1 3 10 10
1 2 10 10
2 3 10 10
2 request.txt(业务请求数据)
2 2 //一共2种业务,每中业务2条备用路径
0 1 //业务请求ID 为0,请求带宽1
0 1 3 //备用路径
0 2 3 //备用路径
1 3 //业务请求ID为1,请求带宽3
1 2 3 //备用路径
1 3 //备用路径
输出文件示例
输出文件为txt文件,命名result.txt;txt文件每行内以空格分隔,文件每行以换行符结尾
1)如果不存在满足条件的传输方案,则输出一行
NA
(文件结束)
- 如果存在满足条件的方案,则按如下格式输出
总的传输成本
业务ID 请求带宽
路径节点列表//(节点列表中间以空格分隔,如A B C)
.....................(若干行)
(文件结束)
- 输出示例
80 //总的传输成本为80
0 1 //业务请求ID为0,请求带宽为r1
0 1 3 //选择路径
1 3 //业务请求id为1,请求带宽为r2
1 2 3 //选择路径
特别说明:
- 输出路径按照业务id从小到大输出。
- 业务大小数据必须与输入文件中数据相吻合,且业务的路径也要符合要求,否则视为无效结果。
分析
本次比赛时间精力有限,采用的算法简单,成绩不是很理想。
先来简单分析一下题目,本次比赛在一张拓扑图中,需要满足带宽的限制,为每一个请求安排一条路径连接起点到终点,计算出该路径成本,寻找总成本最优的结果。
首先,刚开始被比赛方带偏了,比赛方给出的请求的参考路径其实没什么用,仅仅使用这些路径数据分配,测试用例的总成本较优解也就500多w。
要想有效的降低成本结果,需要摒弃输入中提供的路径,所有路径都由自己去分配。
首先我想到的可能是用迪杰斯特拉算法等,逐一的找寻最优路径,再交换顺序重新分配。
又或者是每次随机的选择路径,分配完成后,再随机的对一条路径进行优化,最后一点一点的逼近最优解。
但是经过测试之后,发现效果都不好。因为比赛要求1分钟完成计算解题,而搜索路径是极为耗时的操作,因而收敛慢,效果差。
采用的策略
经过多次尝试,我采用的策略如下:
1.首先不考虑带宽限制,运行一次Floyd计算各个请求的最短成本路径。
2.调整路径放置顺序,将路径按成本从小到大的先后顺序放入网络中,如果请求路径带宽超出限制,则不放。
3. 将所有能放下的放入后,对于剩余的请求,按照第一次的floyd路径的初始拟放置路径成本从小到大的顺序,依次计算迪杰斯特拉最短成本路径,并放入网络中,更新网络(主要是剩余带宽信息),继续布置下一个,直到最终所有请求都完成布置。
该方法测试用例能达到412w。该方法简单快捷,限制1分钟,实际只用了5秒左右,不具备自动调优的能力,对于同一输入,结果都是一致的。后面会讲讲优秀的同学的方法。其实对于规划路径排序依据我试了几个评判标准,比如路径的总带宽啊,最大边带宽啊,路径的边带宽与成本之比等等,最后发现还是根据成本排序效果最好。
代码实现
main函数
public static void main(String[] args) throws IOException, CloneNotSupportedException {
// LogUtil.printLog("Begin");
String girdPath = "D:\\资料\\中兴比赛\\迪杰斯特拉\\case1\\gridtopo.txt";
String reqPath = "D:\\资料\\中兴比赛\\迪杰斯特拉\\case1\\request.txt";
String address = "D:\\downloads\\1-迪杰斯特拉-网络均衡流量\\测试数据-对外公布\\case\\gridtopoAndRequest.txt";
String resPath = "D:\\downloads\\1-迪杰斯特拉-网络均衡流量\\测试数据-对外公布\\case\\结果1.txt";
// String[] grid = FileUtil.read(girdPath, null);
// String[] req = FileUtil.read(reqPath, null);
String[] input = FileUtil.read(address, null);
// String[] input = readText();
/*=============================处理Gridtopo.txt=================================== */
int totalNodeNum = Integer.parseInt(input[0].split(" ")[0]);
int totalPathNum = Integer.parseInt(input[0].split(" ")[1]);
int[][] RequestIdFromStart2End = new int[totalPathNum][totalPathNum];//起点到终点信息记录
// System.out.println(totalNodeNum+","+totalPathNum);
GridTopo topo = new GridTopo(totalNodeNum,totalPathNum);
topo.populateFrom(input);
/*=============================处理request.txt=================================== */
RequestInfos requestInfos = poputateRequestInfos(input,totalPathNum);
/*
* computeMiniPathGroup方法
*/
Floyd floyd = new Floyd(topo,requestInfos.getRequests());
// Floyd floyd = new Floyd(topo.getCosts(),topo.getTotalBWs(),new String[totalNodeNum][totalNodeNum],
// requestInfos.getRequests(),RequestIdFromStart2End);
floyd.computeMiniPathGroup();
// System.out.println(requestInfos.getRequests().get(0).getMinPath());
floyd=null;//释放内存
/*=============================分配=================================== */
/*
* 顺序先放小后放大
*/
QuickSort qs = new QuickSort(requestInfos.getRequests());
qs.sortCost(0, requestInfos.getRequests().size()-1);//快排,属性值带宽
System.out.println();
int costSum = Assign.assign(requestInfos,topo);
RequestInfos resRequestInfos = requestInfos;
int finalCostSum = costSum;
// System.out.println("全网最小成本:"+costSum);//
String[] result = new String[resRequestInfos.getTotalRequestNum()*2+1];
result[0] = String.valueOf(finalCostSum);
populateResult(result,resRequestInfos);
// int index1 = 1;
/*============================输出结果=======================================*/
// for(String s:result){
// System.out.println(s);
// }
System.out.println(finalCostSum);
FileUtil.write(resPath, result, false);
// LogUtil.printLog("End");
}Floyd方法计算最短路径和按照路径成本进行快排采用的是网上的经典模板改写的,这里就不再赘述。
说一下放置的实现。
public static int planPaths(RequestInfos requestInfos, GridTopo topo) {
int[][] leftBW = copyof(topo.getTotalBWs());
allPathCostSum = 0;
ArrayList failRequests = startPlaceFloydPath(requestInfos,leftBW);
System.out.println(failRequests.size());
planPathForRemainingRequests(failRequests,topo,leftBW);
return allPathCostSum;
}
private static ArrayList startPlaceFloydPath(RequestInfos requestInfos, int[][] leftBW) {
ArrayList failRequest = new ArrayList<>();
for(int i=0;i private static void planPathForRemainingRequests(ArrayList failRequests, GridTopo topo, int[][] leftBW) {
for(int i=0;i 接下来就可以按照格式,输出result文件了。
总结和反思
本次比赛,恰逢写毕业论文的繁忙期,所以最后很遗憾没有进入30强,但是赛后听取了大佬们的清奇思路。这里说两个排名比较厉害的选手的解题办法。
1. 排第一位的选手,选择首先在不考虑带宽限制的条件下,计算出各个请求的最短floyd成本路径(这一步跟我一样有木有!),然后根据网络中边的带宽分部情况,调节带宽超负载的边的成本值(此成本只用于规划路径,计算总成本是使用真实路径成本),成本值改变,那相应的计算出的最短路径就会改变。调节一个边的成本可能会使得许多条请求的最短路径改变。该大佬说样例,20次能收敛到比较好的解,真厉害。
这位选手说的是仅仅重新计算最短成本路径中包含带宽超负载的请求的路径【集合A】(我也觉得是这样,因为如果全部重新计算路径,1分钟内很难收敛,一分钟最多计算30-50次floyd左右)。
这里有一个问题是,到下一轮,A中重新规划的路径,必然会与其他的路径抢夺带宽资源,形成新的超负载带宽边,因此下一次重新规划路径是只重新计算上一次的分配路径集合A中剩余的仍然超带宽的请求,还是说将包含新的超带宽边的请求路径也添加进来,重新计算路径 。
另外,这个思路的关键之处是怎样根据一条边的带宽的过载程度来相应的增加成本以达到调节网络负载的目的,如何随着循环次数的增加动态的调节这个过程,使得最终收敛一个较好的结果。我尝试了一下,样例输入是430w多,不容易收敛,循环次数多了,反而结果变差,很难复刻他的效果。
2. 另一个高分选手的思路是,使用dijkstra为每一个请求依次分配最短路径。然后随机取出几个请求的路径,重新计算再填入,多次重复前面取出,重新分配的过程,逼近最优解。
资源下载
最后附上完整的程序下载链接,欢迎下载。
https://download.csdn.net/download/mtngt11/11647394