Liberal Event Extraction and Event Schema Induction
【文章来源】
http://anthology.aclweb.org/P/P16/P16-1025.pdf
我们提出了一种全新的“自由”事件提取范式,可以同时从任意输入语料库中提取事件和发现事件模式。我们结合符号(如抽象意义表示)和分布语义来检测和表示事件结构,并采用联合类型框架来同时提取事件类型和参数角色,发现事件模式。在一般和特定领域的实验表明,该框架可以构造具有许多事件和参数角色类型的高质量模式,涵盖了手动定义模式中的大部分事件类型和参数角色。我们表明,使用已发现的模式提取性能与根据预定义的事件类型从大量标记的数据中训练出来的监督模型相当。新的事件类型的提取质量也很有前途。
1 简介
事件提取旨在识别和键入触发词和参与者(参数)。它仍然是一项具有挑战性且成本高昂第一个问题是提取什么?TIPSTER(Onyshkevych等,1993),MUC(Grishman和Sundheim,1996),CoNLL(Tjong等,2003; Pradhan等,2011),ACE 1和TACKBP(Ji和Grishman,2011)程序被发现根据潜在用户的需要手动定义事件模式是可行的。 ACE事件模式示例如图1所示。此过程非常昂贵,因为消费者和专家语言学家需要在指定事件和参数角色的类型之前检查大量数据,并为模式中的每个类型编写详细的注释指南。手动定义的事件模式通常提供低覆盖率并且无法推广到新域。例如,尽管上述程序与用户有潜在的相关性,但它们的模式中都没有包括“捐赠”和“疏散”。
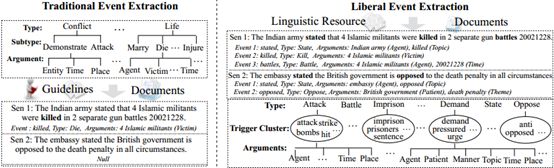
图1 ACE事件提取和自由事件提取之间的比较
在本文中,我们提出了自由事件提取,这是一种将人类带出循环并使系统能够以更自由的方式提取事件的新范例。它会自动发现为特定输入语料库定制的完整事件模式。图1比较了ACE事件提取范例和我们提出的Liberal事件提取范例。我们使用以下示例来解释和激励我们的方法,其中事件触发器以粗体显示,参数以斜体显示并加下划线:
E1. Two Soldiers were killed and one injured in the close-quarters fighting in Kut.
E2. Bill Bennet’s glam gambling loss changed my opinion.
E3. Gen. Vincent Brooks announced the capture of Barzan Ibrahim Hasan al-Tikriti, telling reporters he was an adviser to Saddam.
E4. This was the Italian ship that was captured by Palestinian terrorists back in 1985.
E5. Ayman Sabawi Ibrahim was arrested in Tikrit and was sentenced to life in prison.
我们寻求集群事件触发器和事件参数,以便每个集群代表一种类型。我们依赖于我们的聚类距离度量的分布相似性。分布式假设(Harris,1954)指出,在类似情境中经常出现的词往往具有相似的含义。我们专门为事件提取制定以下分布式假设,并相应地制定我们的方法。
表1 前8个最相似的单词(在3个集群中)

假设1:在类似的上下文中发生并且具有相同意义的事件触发器往往具有相似的类型。
按照分布式假设,当我们简单地从每个单词的大型语料库中学习一般单词嵌入时,我们获得类似于表1中所示的单词。我们可以看到类似的单词,例如以“伤害”和“战斗”为中心的单词,正在融合到类似的类型。然而,对于具有多种感官的单词,例如“射击”(射击或就业终止),类似的单词可以指示多种事件类型。因此,我们建议应用Word Sense Disambiguation(WSD)并为每种意义学习不同的嵌入(第2.3节)。
假设2:除了特定事件触发器的词汇语义之外,其类型还取决于其参数及其角色,以及与触发器在上下文中连接的其他单词。
例如,在E4中,患者角色是车辆(“意大利船”)而不是人(如E3和E5)这一事实表明事件触发器“已捕获”具有类型“转移所有权”,如反对“逮捕”。在E2中,我们知道“损失”事件发生在赌博场景中,因此我们可以将其类型确定为资金损失,而不是生命损失。
因此,我们建议通过在触发器的上下文中合并各种单词的分布表示来丰富每个触发器的表示。并非所有上下文单词都与事件触发类型预测相关,而其预测值的变化则不同。我们建议使用从文本的意义表示派生的语义关系,在事件触发器的上下文中仔细选择参数和其他单词。然后将这些单词合并到“全局”事件结构中以提示触发器。我们依靠语义关系来(1)指定相关上下文单词的分布语义如何对整个事件结构表示做出贡献; (2)确定相关语境词的分布语义被纳入事件结构的顺序(第2.4节)。
2 方法
2.1 概述

图2 自由事件提取概述
图2显示了自由事件提取的整体框架。给定一组输入文档,我们首先提取语义关系,应用WSD并学习词义嵌入。接下来,我们确定候选触发器和参数。
对于每个事件触发器,我们应用一系列组合函数来生成该触发器的事件结构表示。每个函数都特定于语义关系,并且对嵌入空间中的向量进行操作。参数表示作为副产品生成。
然后将触发器和参数表示传递给联合约束聚类框架。最后,我们命名每个触发器集群,并使用FrameNet,VerbNet(Kipper等人,2008)和Propbank(Palmer等人,2005)中的含义表示和语义角色描述之间的映射来命名每个触发器的参数。
我们比较了连接触发器的语义关系到上下文单词的设置,这些设置来自三个含义表示:
抽象意义表示(AMR)(Banarescu等,2013),Stanford Typed Dependencies(Marie-Catherine et al,2006)和FrameNet(Baker和Sato,2003)。我们分别使用CAMR(Wang et al,2015a),Stanford的依赖解析器(Manning,2003)和SEMAFOR(Das et al,2014)为这三种表示自动导出语义关系。
2.2 候选触发和参数识别
给定一个句子,我们认为所有被赋予OntoNotes(Hovy等,2006)的名词和动词概念都被WSD视为候选事件触发器。在FrameNet语料库中匹配语音和名义词汇单元的任何剩余概念也被视为候选事件触发器。这主要有助于识别更多名义上的触发器,如“扒手”和“罪恶”。
表2 事件相关AMR关系

对于每个候选事件触发器,我们将所有概念视为候选参数,其中一个手动选择的一组语义关系在其与事件触发器之间保持。对于AMR作为我们的意义表示的设置,我们选择了指定事件参数的所有AMR关系的子集,如表2所示。注意,一些AMR关系通常不指定事件参数,例如 “mode”,可以表示句子的言外之力,或“snt”,用于将多个句子组合成一个AMR图。当FrameNet是含义表示时,我们允许所有帧关系识别参数。对于依赖项,我们手动将依赖关系映射到AMR关系并使用表2。

图3 事件触发器和参数注释以及E1的AMR解析结果
例如,在E1中,“被杀”,“受伤”和“战斗”被确定为候选触发器,并且使用AMR关系将三个概念集识别为候选参数:“{两名士兵,非常大的导弹}”,“{1 ,Kut}“和”{Two Soldiers,Kut}“,如图3所示。
2.3 触发词和参数表示
基于假设1,我们使用连续的Skip-gram模型(Mikolov et al. 2013)从一个大数据集中学习基于sense的嵌入式(sense-based embedded)。具体来说,我们首先应用WSD,使用最先进的工具(Zhong and Ng, 2010)将WordNet中的每个单词与其意义联系起来,并将WordNet的意义输出映射到OntoNotes的意义。我们将每个触发候选映射到它的OntoNotes感知,并学习每个感知的不同嵌入。我们使用一般的词汇嵌入作为参数。
2.4 事件结构组成和表示
基于假设2,我们的目标是利用语言知识将事件和参数角色类型之间的依赖关系合并到我们的事件结构表示中。许多意义陈述可以在某种程度上提供这样的信息。我们使用AMR从含义表示中使用语义关系来说明构建事件结构的方法。在3.4节中,我们使用Stanford Typed Dependencies和FrameNet代替AMR来比较结果。我们以E2为例。基于AMR注释和表2,我们使用感知“lost-1”为事件触发器提取语义相关的单词,并构造整个事件的事件结构,如图4所示。
我们设计了基于Tensor的递归自动编码器(TRAE)(Socher等,2011)框架,以针对AMR语义关系的每个子集利用基于张量的合成函数,并基于多个功能应用构成事件结构表示。作者将手动选择该子集作为将触发器链接到有助于确定其类型的概念的关系集。类似地,我们使用相同的使用那些含义表示的实验标准选择了依赖关系和FrameNet关系的子集。

图4 E2的部分AMR和事件结构
图4显示了应用于事件结构以生成其表示的TRAE的实例。对于每个语义关系类型r,例如“:mod”,我们通过以下向量化符号定义张量积Z的输出:
![]()
其中![]() 是3阶张量,
是3阶张量,![]() 是两个输入字矢量。
是两个输入字矢量。![]() 是偏差项。[X; Y]表示两个向量X和Y的串联。张量的每个切片充当Z中的一个条目Zi的系数矩阵:
是偏差项。[X; Y]表示两个向量X和Y的串联。张量的每个切片充当Z中的一个条目Zi的系数矩阵:
![]()
我们使用统计平均值来组成由“:op”关系连接的单词(例如图4中的“Bill”和“Bennet”)。在组成X和Y的向量之后,我们对组合向量应用元素方式的S形激活函数并生成隐藏层表示Z。优化Z的一种方法是尝试通过生成来自Z的X’和Y’来重构向量X和Y,并且最小化输入VI = [X,Y]和输出层VO = [X’,Y’]之间的重建误差。基于欧几里德距离函数计算误差:
![]()
对于每对单词X和Y,重建误差通过参数Θr=(W’r,b’r,Wr,br)从其输出层反向传播到输入层。 设δO为输出层的残差,δH为隐层的误差:
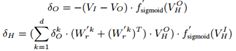
其中![]() 和
和![]() 表示隐藏层的输入和输出,
表示隐藏层的输入和输出,![]() 。
。![]() 是张量
是张量![]() 的第k个切片。为了最小化重建误差,我们利用梯度下降来迭代更新参数Θr:
的第k个切片。为了最小化重建误差,我们利用梯度下降来迭代更新参数Θr:

在基于X和Y计算Z1的合成矢量之后,对于下一层,它组成Z1和另一个新的单词矢量,例如Xgl。对于每种类型的关系r,我们随机抽样2,000对以训练优化的参数Θr。对于每个事件结构树,我们迭代地为每个层重复相同的步骤。对于每层的多个参数,我们按照它们到触发器的距离的顺序组成它们:最接近的参数首先组成。
2.5 联合触发和参数聚类
基于上述表示向量,我们计算了每一对触发器和参数之间的相似性,并将它们聚类成类型。回想一下,触发器的参数在2.2节中被识别出来。我们观察到,对于两个触发器t1和t2,如果它们的参数具有相同的类型和角色,则它们更可能属于相同类型,反之亦然。因此,我们引入约束函数f,以强制相互依赖的触发器和参数具有相干类型:
![]()
其中P1和P2是触发器。 Li的元素是形式(r,id(a))的对,其中id(a)是参数a的簇ID,其代表r与Pi的关系。 例如,让P1和P2触发“捕获”和“逮捕”(参见图5)。 如果Barzan Ibrahim Hasan al-Tikriti和Ayman Sabawi Ibrahim拥有相同的集群ID,则该对(arg1,id(Barzan Ibrahim Hasan al-Tikriti))将成为L1∩L2的成员。 这个论点重叠是“捕获”和“被捕”具有相同类型的证据。 我们定义f,其中Pi是参数,元素Li的定义与上面类似。

图5 E3,4,5的联合约束聚类
给定触发器集T及其对应的参数集A,我们计算两个触发器t1和t2之间的相似性以及两个参数a1和a2:
![]()
![]()
其中![]() 代表触发感应向量,
代表触发感应向量,![]() 代表参数向量。 Rt是在t的事件结构中设置的AMR关系,并且表示由对应于触发器t的语义关系r的最后应用组合函数产生的向量。λ是一个正则化参数,它控制这两种表示之间的权衡。 在我们的实验中,λ= 0.6。
代表参数向量。 Rt是在t的事件结构中设置的AMR关系,并且表示由对应于触发器t的语义关系r的最后应用组合函数产生的向量。λ是一个正则化参数,它控制这两种表示之间的权衡。 在我们的实验中,λ= 0.6。
我们设计了一种联合约束聚类方法,该方法基于上述约束迭代地产生新的聚类结果。为了找到一个全局最优值,它对应于触发器的近似最佳分区,设置为K簇![]() ,并且参数的分区设置为M个簇
,并且参数的分区设置为M个簇![]() ,我们最大限度地减少群集之间的协议以及群集内的分歧:
,我们最大限度地减少群集之间的协议以及群集内的分歧:
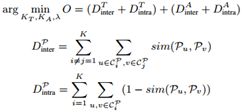
我们将光谱聚类算法(Luxburg,2007)结合到关节约束聚类过程中,以获得最终优化的聚类结果。算法1总结了详细的算法。

2.6 事件类型和参数角色命名
对于每个触发器集群,我们利用最接近集群质心的触发器作为事件类型名称。对于给定的事件触发器,我们为每个参数分配一个角色名称(在2.2节中标识)。此过程取决于使用哪个含义表示来选择参数。
表3 核心角色映射示例

对于AMR,我们首先将事件触发器的OntoNotes意义映射到PropBank,VerbNet和FrameNet。我们为每个参数分配一个角色名称如下。如果可能,我们将AMR核心角色(例如“:ARG0”,“ARG1”)映射到FrameNet,否则映射到VerbNet,如果没有到VerbNet的映射,最后映射到PropBank角色。近5%的AMR核心角色可以映射到FrameNet角色,55%可以映射到VerbNet角色,剩下的可以映射到PropBank。表3显示了一些映射示例。我们将非核心角色从AMR映射到FrameNet,如表4所示。
表4 非核心角色映射

当Stanford Typed Dependencies用于意义表示时,我们构建手动映射AMR关系并使用上述过程。当FrameNet用于含义表示时,我们只保留参数角色命名的FrameNet角色名称。
3 评估
3.1 数据
我们使用2014年8月11日的英语维基百科转储来学习触发感和参数嵌入。 为了评估,我们选择了ERE(实体关系事件)语料库(50个文档)的子集,它具有完美的AMR注释,因此我们可以比较完美AMR和系统生成的AMR的影响。为了与自动内容提取(ACE2005)数据的最新事件提取进行比较,我们遵循先前工作中的相同评估设置(Ji和Grishman,2008; Liao和Grishman,2010; Hong等,2011)并使用40个新闻专线文件作为我们的测试集。
3.2 架构发现
图6显示了一些示例,它们是从ERE数据集中发现的事件模式的一部分。每个聚类表示一个事件类型,带有一组事件提及和句子。每个事件提及也与一些论点及其角色相关联。样本句子的事件和参数角色注释可以作为基于示例的语料库定制的用于事件提取的“注释指南”。
表5 ACE和ERE的模式覆盖率比较
![]()
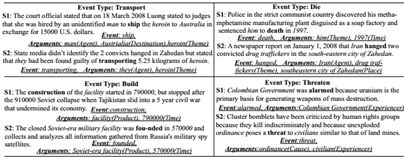
图6 事件模式的示例输出
表5将使用AMR作为含义表示的方法发现的事件模式的覆盖范围与预定义的ACE和ERE事件模式进行了比较。除了在ACE和ERE中定义的类型之外,这种方法还发现了许多新的事件类型,如Build和Threaten,如图6所示。我们的方法还可以发现给定事件类型的新参数角色。例如,对于攻击事件,除了在ACE中定义的五种类型的现有参数(攻击者,目标,仪器,时间和地点)之外,我们还发现了一种新类型的参数目的。例如,“荷兰政府面临强大的公共反战压力,表示它不会对伊拉克战争施加战斗力,但补充说它支持解除萨达姆武装的军事行动。”,“萨达姆解除武装”被认定为“广告系列”触发的攻击事件的目的。请注意,虽然FrameNet将“目标”指定为攻击的参数角色,但此类特定于“攻击”的信息不是AMR的一部分。
3.3 所有类型的事件提取
为了评估整个事件模式的性能,我们从ERE数据集中随机抽取100个句子,并要求两位语言专家将事件完全注释为参数。作为起点,使用金标准AMR从我们的Schema Discovery获得注释器输出。
对于每个句子,他们看到了事件触发器和相应的参数。他们的工作是通过标记错误标识的事件和参数以及添加缺少的事件和参数来纠正此输出。对于触发器,注释器间协议为83%,参数为79%。
表6 所有事件类型的ERE数据的自由事件提取的整体表现
![]()
为了评估触发器和参数识别,我们自动将此黄金标准与系统输出进行比较(参见表6)。为了评估触发器和参数类型,注释器手动检查系统输出并评估类型名称是否合理(参见表6)。请注意,系统和黄金标准输出之间的自动比较不适合打字;对于给定的群集,没有明确的“最佳”名称。
我们发现,我们的系统无法恢复的大多数事件触发器都是多字表达,例如“上台”或诸如“之前”和“以前”的副词。对于参数识别,我们的方法无法识别需要提取世界知识的一些论据。例如,在“反腐败法官Saul Pena表示Montesinos承认滥用权力指控”中,“Saul Pena”未被确定为事件“指控”的裁决者论点,因为它与事件触发器没有直接的语义关系。
3.4 语义信息和语义的影响
含义表示表7评估了各种类型语义信息的影响,并且还比较了每种类型的含义表示对打字任务的有效性。我们注意到,如果不使用基于WSD的嵌入,则F-measure下降14.4分。此外,指定核心和非核心角色的AMR关系对于学习不同的组合操作员是有用的。为了比较意义表示的输入结果,我们使用AMR和FrameNet解析器识别的触发器。使用Stanford Typed Dependencies,关系可能过于粗糙或缺乏足够的语义信息。因此,我们的方法无法利用事件触发器类型和参数角色之间的相互依赖性来实现纯触发器集群。与依赖关系相比,细粒度的AMR语义关系,例如:location,:manner,:topic,:instrument似乎更有助于推断出参数角色。例如,句子“在Sringar西南约25公里的2名武装分子在第二次枪战中丧生。”,“枪”被确定为基于AMR关系的“战斗”事件的工具:仪器。相反,依赖性解析将“枪”识别为“战斗”的复合修饰符。请注意,我们使用静态映射将依赖关系映射到AMR关系(请参阅第2.6节),而理想情况下,此映射将依赖于上下文。创建依赖于上下文的映射将构成构建AMR解析器的重要步骤。
表7 语义信息和表示对ERE数据类型的影响
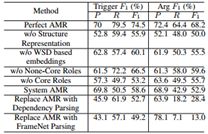
使用FrameNet会导致参数类型的调用率降低。 SEMAFOR的输出通常不能识别我们的注释器识别的所有参数。许多触发器与零个或一个参数相关联,因此没有足够的数据来学习事件结构表示。此外,SEMAFOR确定的大多数论点都是长篇短语。因为没有分配内部结构,我们只是简单地平均所有单个标记的向量来表示短语。但是,高精度可能是因为FrameNet关系旨在指定语义角色。
3.5 ACE / ERE类型的事件提取
我们在基于其注释指南的基于AMR的方法(ACE / ERE事件)发现的ACE和ERE评估集中手动选择事件触发器。如果触发器还没有金标准ACE / ERE注释,我们提供一个。对于每个此类事件,我们使用核心角色和Instrument / Possessor / Time / Place关系来检测参数。如果ACE / ERE注释不存在,则手动评估每个触发器和参数角色类型。我们通过将系统输出与手动注释进行比较来评估触发器和参数类型的方法,同时将同义标签视为等效(例如,我们的方法的类型为ACE的模具)。我们将我们的方法与以下最先进的监督方法进行比较,这些方法由529份ACE文件或336份ERE文件进行培训:
- DMCNN:基于分布式词表示的动态多池卷积神经网络(Chen et al。,2015)。
- Joint:基于符号语义特征的结构化感知器模型(Li et al。,2013)。
- LSTM:基于分布式语义特征的长期短期记忆神经网络(Hochreiter和Schmidhuber,1997)。
表8 ERE和ACE事件的性能。

表8显示了结果。在ACE事件中,DMCNN和Joint方法都优于我们的触发和参数提取方法。但是,当转移到ERE事件架构时,尽管基于ERE标记数据进行了重新训练,但它们的性能仍然会显着下降。以前的这些方法在很大程度上依赖于训练数据的质量和数量。当培训数据不足时(ERE培训文件包含1,068个事件和2,448个参数,而ACE培训文档包含4,700多个事件和9,700个参数),性能很低。相比之下,我们的方法是无监督的,可以自动识别事件,参数和分配类型/角色,并且不依赖于一个事件模式。
3.6 生物医学领域的事件提取
为了证明我们对新域的方法的可移植性,我们对14个生物医学文章(755个句子)进行了实验,并进行了完美的AMR注释(Garg等,2016)。我们利用来自PubMed7的所有论文摘要和来自PubMed Central Open Access子集的全文文档训练的word2vec model6。为了评估表现,我们随机抽取100个句子并要求生物医学科学家评估每个事件和论证角色的正确性。我们的方法在触发器标记(总共619个事件)和78.4%的参数标记精度(总共1,124个参数)上达到了83.1%的精度。它表明我们的方法可以快速适应新域并发现域丰富的事件模式。事件类型“Dissociate”的示例模式如图7所示。

图7 所发现的生物医学事件模式的示例输出
4 相关工作
以前的大多数事件提取工作都集中在基于符号特征的学习监督模型上(Ji和Grishman,2008; Miwa等,2009; Liao和Grishman,2010; Liu等,2010; Hong等,2011; McClosky et al。,2011; Sebastian and Andrew,2011; Chen and Ng,2012; Li et al。,2013)或通过深度学习的分布特征(Chen et al。,2015; Nguyen and Grishman,2015)。它们通常依赖于预定义的事件模式和大量的训练数据。与开放信息提取(Etzioni et al。,2005; Banko et al。,2007; Banko et al。,2008; Etzioni et al。,2011; Ritter et al。,2012),Preemptive IE(Shinyama)等其他范例相比和Sekine,2006),Ondemand IE(Sekine,2006)和基于语义框架的事件发现(Kim et al。,2013),我们的方法可以明确地命名每个事件类型和参数角色。最近的一些工作集中在通用模式发现上(Chambers和Jurafsky,2011; Pantel等,2012; Yao等,2012; Yao等,2013; Chambers,2013; Nguyen等,2015)。但是,从这些方法中发现的模式是相当静态的,并且它们不是针对任何特定输入语料库定制的。我们的工作还涉及使用句法结构组合单词嵌入的努力(Hermann和Blunsom,2013; Socher等,2013a; Socher等,2013b; Bowman等,2014; Zhao等,2015)。我们的触发感表示类似于Word Sense Induction(Navigli,2009; Bordag,2006; Pinto等,2007; Brody和Lapata,2009; Manandhar等,2010; Navigli和Lapata,2010; Van de Cruys和Apidianaki ,2011; Wang等,2015b)。除了词义之外,我们利用相关概念来丰富触发器表示。
5 结论和未来的工作
我们提出了一种新颖的Liberal事件提取框架,它结合了符号语义和分布式语义的优点。新闻和生物医学领域的实验表明,该框架可以发现明确定义的丰富事件模式,这些模式不仅涵盖现有手动定义的模式中的大多数类型,还覆盖新的事件类型和参数角色。还针对特定输入语料库定制事件类型的粒度。并且它可以在不使用带注释的训练数据的情况下同时生成高质量的事件注释。将来,我们会将此框架扩展到其他信息提取任务。