BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation
Paper link: https://arxiv.org/abs/2001.00309
GitHub (PyTorch, 基于Detectron2): https://github.com/aim-uofa/adet
Introduction
实例分割任务需要执行dense per-pixel prediction,在完成像素级语义分类的同时,需要鉴别出目标实例鉴。基于深度学习的实例分割模型,通常包括Top-down架构与Bottom-up架构,两种结构各有优劣势。文章提出的BlendMask实例分割模型,以Anchor-free FCOS检测器为主体结构,通过融合High-level实例信息与Low-level逐像素预测结果,达到了SOTA的分割效果。mask mAP最高能到41.3,实时版本BlendMask mAP性能和速度分别为34.2和25FPS (1080ti GPU)。
-
Top-down架构:
Top-down模型先通过一些方法 (如RPN、detector等)获取bbox,然后从high-level特征区域中提取ROI特征,进而对区域内的像素进行mask提取,这种模型一般有以下几个问题:
- 由于使用了high-level特征图,位置信息容易损失;
- 特征和mask之间的局部一致性会丢失,容易导致mis-align;
- 冗余的特征提取,不同的bbox会重新提取一次mask;
以Mask-RCNN为例:
- 基于Faster-RCNN,属于two-stage架构,RPN获取的bbox用于提取ROI特征;
- mask分支与detection分支共享ROIAlign features;

- Bottom-up架构:
Bottom-up模型先对整图进行逐像素预测(per-pixel prediction),每个像素生成一维特征向量 (embedding)。由于进行的是逐像素级预测、且stride很小,局部一致性和位置信息可以很好的保存,但依然存在以下几个问题:
- 严重依赖逐像素预测的质量,context信息匮乏,容易导致非最优分割;
- 由于mask在低维提取,缺乏context信息,对于复杂场景的分割能力有限;
- 由于逐像素生成embedding,需要复杂的后处理方法;
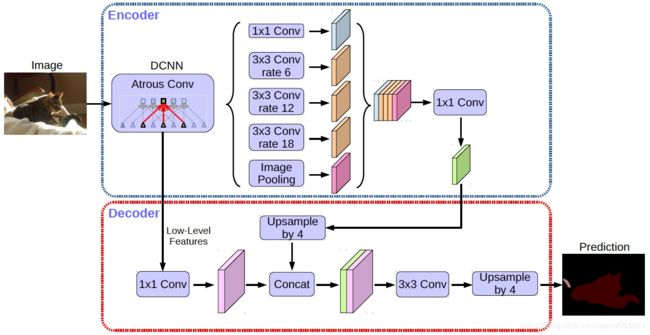
以Deeplab-v3+的Decoder为例 (语义分割):
- Decoder以low-level特征为输入,执行per-pixel prediction;
- "Two-stage vs. One-stage" and "Anchor-based vs. Anchor-free":
以Mask-RCNN作为对比模型:
- One-stage模型的执行效率更高;
- Anchor-free模型的优势:
- 避免了anchor相关的超参设置,包括aspect-ratio、scale以及anchor匹配阈值等;
- Anchor-free模型通常执行per-pixel预测,样本召回率更高;
- 节省了anchor相关的计算,尤其是anchor数目较多的情况下,能够提升执行效率;
BlendMask实现结构与算法原理
- 概述:
文章综合top-down和bottom-up方法,利用instance-level信息 (bbox)对low-level per-pixel prediction进行ROI截取、以及attention加权,进而预测输出instance mask,主要贡献有以下几点:
- 设计了blender,用于生成proposal-based instance mask,在COCO上对比YOLACT和FCIS,分别提升了1.9和1.3 mAP;
- 基于FCOS提出简洁的算法网络BlendMask;
- BlendMask的推理时间不会像two-stage detector一样,随着预测数量的增加而增加;
- BlendMask的准确率和速度都优于Mask-RCNN,且mask mAP比最好的全卷积实例分割网络Tensor-Mask高1.1;
- 结合instance-level信息,bottom模块能同时分割多种物体,因而BlendMask可直接用于全景分割;
- Mask-RCNN的mask输出固定为28×28,而BlendMask的mask输出像素可以很大;
- BlendMask通用且灵活,只要一些小修改,就可以用于其它instance-level识别任务,例如关键点检测;
- 基于FCOS的总体实现结构:
关键模块包括基于FCOS的top layers,执行per-pixel prediction的bottom module,以及融合instance信息与per-pixel score map的blender模块:
- Top-layers:
主体结构为FCOS目标检测模型,FPN输出的multi-level features一方面应用于常规目标检测,获得bbox与 cls score;另一方面接入conv. towers生成spatial attentions: ![]() 。
。
每个pixel位置的spatial attention属于3D结构: K*M*M。表示bottom module预测的per-pixel score map的embedding维度;M*M表示attention的二维空间维度(通常取值为4或8等),表明spatial attention具备捕获instance-level信息的能力,如目标的姿态、粗略形状信息等。
Top-layers基于cls score对不同目标的bbox与attention进行排序,筛选出Top-D个proposals,应用于blender的信息融合:
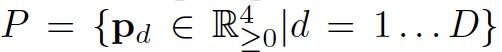
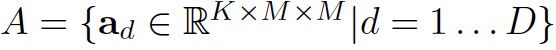
- Bottom Module:
Bottom module采用Deeplab-v3+的decoder结构,以backbone的C3、C5特征作为输入 (亦可用FPN特征),输出per-pixel score maps (记作B: bases):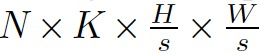 。表示per-pixel的embedding维度。
。表示per-pixel的embedding维度。
- Blender Module:
Blender是BlendMask的核心模块,其输入为bottom-level的基底B 以及选择的top-level attentions A、bbox P。首先,使用Mask R-CNN的ROIPooler截取每个bbox pd对应的基底区域,并resize成R*R 的特征图:

需要注意的是:训练阶段使用gt bbox作为proposals;而在推理时,使用FCOS的检测结果。
attention大小为M*M (小于R*R),因此需要对ad进行上采样插值:
![]()
然后沿K-dimension执行softmax归一化处理,获得attention weight map:
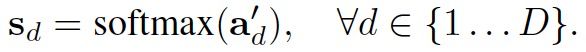
最后基于attention weight map,沿K-dimension对截取的bbox特征进行加权求和:
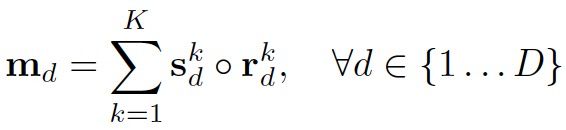
信息融合过程如下,沿K-dimension,每个attention可表示instance的某个部位:

- 超参数设置:
主要的超参数如下,文章根据R, M与K的设置,将模型标记为R_K_M:

实验结果
实验设置、Ablation对比及实验结果详见文章。