如何用 Python 和深度迁移学习做文本分类?

本文为你展示,如何用10几行 Python 语句,把 Yelp 评论数据情感分类效果做到一流水平。
疑问
在《如何用 Python 和 fast.ai 做图像深度迁移学习?》一文中,我为你详细介绍了迁移学习给图像分类带来的优势,包括:
用时少
成本低
需要的数据量小
不容易过拟合
有的同学,立刻就把迁移学习的这种优势,联系到了自己正在做的研究中,问我:
老师,迁移学习能不能用在文本分类中呢?正在为数据量太小发愁呢!
好问题!
答案是可以。
回顾《如何用机器学习处理二元分类任务?》一文,我们介绍过文本分类的一些常见方法。
首先,要把握语义信息。方法是使用词嵌入预训练模型。代表词语的向量,不再只是一个独特序号,而能够在一定程度上,刻画词语的意义(具体内容,请参见《如何用Python处理自然语言?(Spacy与Word Embedding)》和《如何用 Python 和 gensim 调用中文词嵌入预训练模型?》)。

其次,上述方法只能表征单个词语含义,因此需要通过神经网络来刻画词语的顺序信息。
例如可以使用一维卷积神经网络(One Dimensional Convolutional Neural Network, 1DCNN):

或者使用循环神经网络(Recurrent Neural Network, RNN):
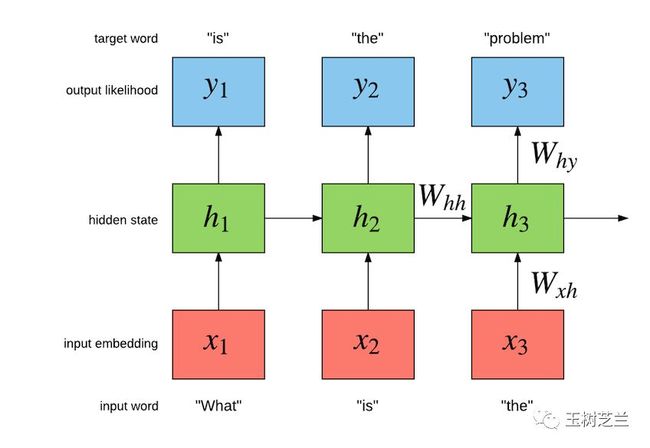
还有的研究者,觉得为了表征句子里词语顺序,用上 CNN 或者 LSTM 这样的复杂结构,有些浪费。
于是 Google 干脆提出了 Universal Sentence Encoder ,直接接受你输入的整句,然后把它统一转换成向量形式。这样可以大幅度降低用户建模和训练的工作量。

困难
这些方法有用吗?当然有。但是 Jeremy Howard 指出,这种基于词(句)嵌入预训练的模型,都会有显著缺陷,即领域上下文问题。
这里为了简化,咱们只讨论英文这一种语言内的问题。
假设别人是在英文 Wikipedia 上面训练的词嵌入向量,你想拿过来对 IMDB 或 Yelp 上的文本做分类。这就有问题了。因为许多词语,在不同的上下文里面,含义是有区别的。直接拿来用的时候,你实际上,是在无视这种区别。
那怎么办?直觉的想法,自然是退回去,我不再用别人的预训练结果了。使用目前任务领域的文本,从头来训练词嵌入向量。
可是这样一来,你训练工作量陡增。目前主流的 Word2vec , Glove 和 fasttext 这几个词嵌入预训练模型,都出自名门。其中 word2vec 来自于 Google,Glove 来自于斯坦福,fasttext 是 facebook 做的。因为这种海量文本的训练,不仅需要掌握技术,还要有大量的计算资源。
同时,你还很可能遭遇数据不足的问题。这会导致你自行训练的词嵌入模型,表现上比之前拿来别人的,结果更差。维基百科之所以经常被使用来做训练,就是因为文本丰富。而一些评论数据里面,往往不具备如此丰富的词汇。
怎么办呢?
迁移
Jeremy Howard 提出了一种方法,叫做“用于文本分类的通用语言模型微调(ULMFiT)”。论文在这里:Howard, J., & Ruder, S. (2018). Universal language model fine-tuning for text classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (Vol. 1, pp. 328-339).

在这篇文章里,他提出了一个构想。
有人(例如早期研究者,或者大机构)在海量数据集(例如Wikipedia)上训练语言模型。之后发布这个模型,而不只是词嵌入向量的表达结果;
普通用户拿到这个模型后,把它在自己的训练文本(例如 Yelp 或者 IMDB 评论)上微调,这样一来,就有了符合自己任务问题领域上下文的语言模型;
之后,把这个语言模型的头部,加上一个分类器,在训练数据上学习,这就有了一个针对当前任务的完整分类模型;
如果效果还不够好,可以把整个儿分类模型再进行微调。
文中用了下图,表达了上述步骤。
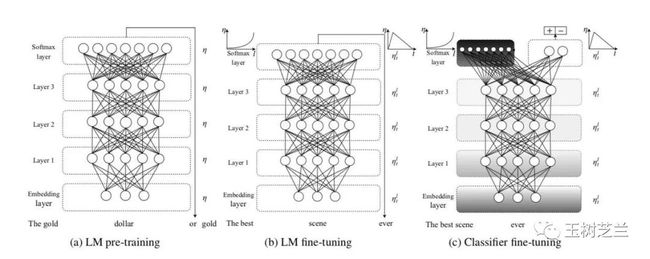
注意在这个语言模型中,实际上也是使用了 AWD-LSTM 作为组块的(否则无法处理词语的顺序信息)。但是你根本就不必了解 AWD-LSTM 的构造,因为它已经完全模块化包裹起来了,对用户透明。
再把我们那几个比方拿出来说说,给你打打气:
你不需要了解显像管的构造和无线信号传输,就可以看电视和用遥控器换台;
你不需要了解机械构造和内燃机原理,就可以开汽车。
用 Python 和 fast.ai 来做迁移学习,你需要的,只是看懂说明书而已。

下面,我们就来实际做一个文本分类任务,体会一下“通用语言模型微调”和深度迁移学习的威力。
数据
我们使用的文本数据,是 Yelp reviews Polarity ,它是一个标准化的数据集。许多文本分类的论文,都会采用它进行效果对比。
我们使用的版本,来自于 fast.ai 开放数据集,存储在 AWS 上。它和 Yelp reviews Polarity 的原始版本在数据内容上没有任何区别,只不过是提供的 csv ,从结构上符合 fast.ai 读取的标准化需求(也就是每一行,都把标记放在文本前面)。
点击这个链接,你就能看到 fast.ai 全部开放数据内容。

其中很多其他数据类别,对于你的研究可能会有帮助。
我们进入“自然语言处理”(NLP)板块,查找到 Yelp reviews - Polarity 。

这个数据集有几百兆。不算小,但是也算不上大数据。你可以把它下载到电脑中,解压后查看。
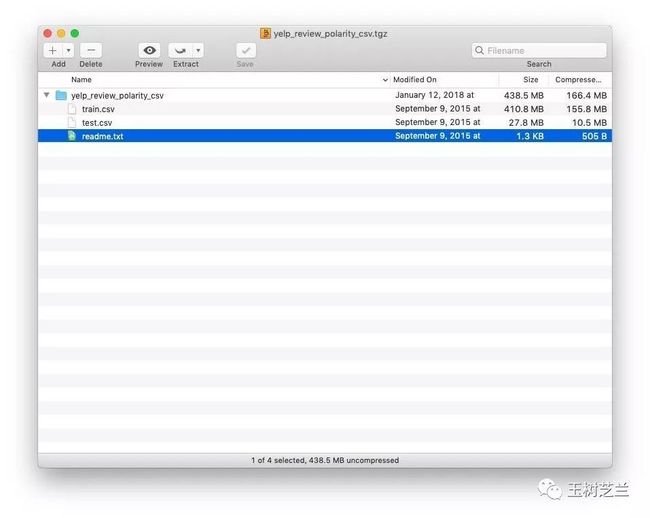
注意在压缩包里面,有2个 csv 文件,分别叫做 train.csv(训练集)和 test.csv(测试集)。
我们打开 readme.txt 看看,其中数据集的作者提到:
The Yelp reviews polarity dataset is constructed by considering stars 1 and 2 negative, and 3 and 4 positive. For each polarity 280,000 training samples and 19,000 testing samples are take randomly. In total there are 560,000 trainig samples and 38,000 testing samples. Negative polarity is class 1, and positive class 2.
之所以叫做极性(Polarity)数据,是因为作者根据评论对应的打分,分成了正向和负向情感两类。因此我们的分类任务,是二元的。训练集里面,正负情感数据各 280,000 条,而测试集里面,正负情感数据各有 19,000 条。
网页上面,有数据集作者的论文链接。该论文发表于 2015 年。这里有论文的提要,包括了不同方法在相同数据集上的性能对比。

如图所示,性能是用错误率来展示的。 Yelp reviews - Polarity 这一列里面,最低的错误率已经用蓝色标出,为 4.36, 那么准确率(accuracy)便是 95.64%。
注意,写学术论文的时候,一定要注意引用要求。如果你在自己的研究中,使用该数据集,那么需要在参考文献中,添加引用:
Xiang Zhang, Junbo Zhao, Yann LeCun. Character-level Convolutional Networks for Text Classification. Advances in Neural Information Processing Systems 28 (NIPS 2015).
环境
为了运行深度学习代码,你需要一个 GPU 。但是你不需要去买一个,租就好了。最方便的租用方法,就是云平台。
在《如何用 Python 和 fast.ai 做图像深度迁移学习?》一文中,我们提到了,建议使用 Google Compute Platform 。每小时只需要 0.38 美元,而且如果你是新用户, Google 会先送给你300美金,1年内有效。
我为你写了个步骤详细的设置教程,请使用这个链接访问。

当你的终端里面出现这样的提示的时候,就证明一切准备工作都就绪了。

我把教程的代码,已经放到了 github 上面,请使用以下语句,下载下来。
git clone https://github.com/wshuyi/demo-nlp-classification-fastai.git
之后,就可以呼叫 jupyter 出场了。
jupyter lab
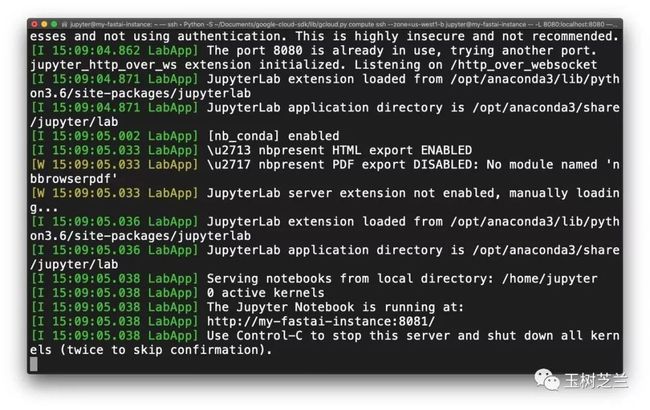
注意因为你是在 Google Compute Platform 云端执行 jupyter ,因此浏览器不会自动弹出。
你需要打开 Firefox 或者 Chrome,在其中输入这个链接(http://localhost:8080/lab?)。

打开左侧边栏里面的 demo.ipynb。
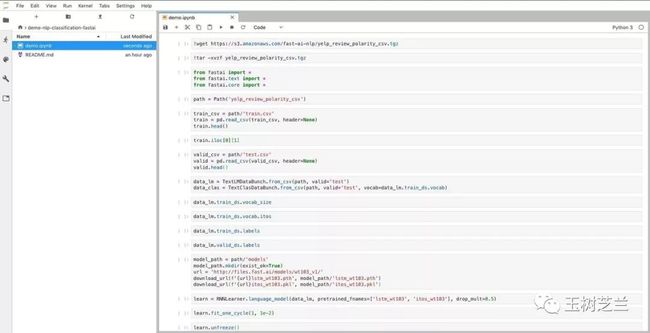
本教程全部的代码都在这里了。当然,你如果比较心急,可以选择执行Run->Run All Cells,查看全部运行结果。

但是,跟之前一样,我还是建议你跟着教程的说明,一步步执行它们。以便更加深刻体会每一条语句的含义。
载入
在 Jupyter Lab 中,我们可以使用 !+命令名称 的方式,来执行终端命令(bash command)。我们下面就使用 wget 来从 AWS 下载 Yelp 评论数据集。
!wget https://s3.amazonaws.com/fast-ai-nlp/yelp_review_polarity_csv.tgz
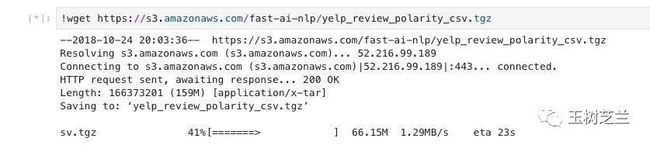
在左边栏里,你会看到 yelp_review_polarity_csv.tgz 这个文件,被下载了下来。

对于 tgz 格式的压缩包,我们采用 tar 命令来解压缩。
!tar -xvzf yelp_review_polarity_csv.tgz

左侧边栏里,你会看到 yelp_review_polarity_csv 目录解压完毕。

我们双击它,看看内容。
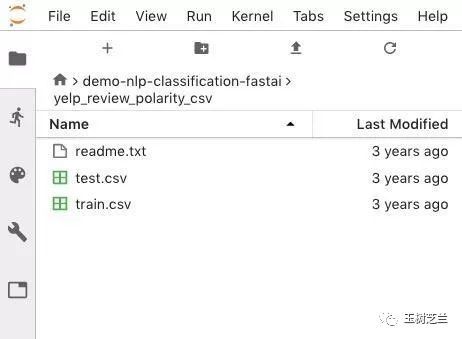
文件下载和解压成功。下面我们从 fast.ai 调用一些模块,来获得一些常见的功能。
from fastai import *
from fastai.text import *
from fastai.core import *
我们设置 path 指向数据文件夹。
path = Path('yelp_review_polarity_csv')
然后我们检查一下训练数据。
train_csv = path/'train.csv'
train = pd.read_csv(train_csv, header=None)
train.head()

每一行,都包括一个标签,以及对应的评论内容。这里因为显示宽度的限制,评论被折叠了。我们看看第一行的评论内容全文:
train.iloc[0][1]

对于验证集,我们也仿照上述办法查看。注意这里数据集只提供了训练集和“测试集”,因此我们把这个“测试集”当做验证集来使用。
valid_csv = path/'test.csv'
valid = pd.read_csv(valid_csv, header=None)
valid.head()

下面我们把数据读入。
data_lm = TextLMDataBunch.from_csv(path, valid='test')
data_clas = TextClasDataBunch.from_csv(path, valid='test', vocab=data_lm.train_ds.vocab)
注意,短短两行命令,实际上完成了若干功能。
第一行,是构建语言模型(Language Model, LM)数据。
第二行,是构建分类模型(Classifier)数据。
它们要做以下几个事儿:
语言模型中,对于训练集的文本,进行标记化(Tokenizing)和数字化(Numericalizing)。这个过程,请参考我在《如何用Python和机器学习训练中文文本情感分类模型?》一文中的介绍;
语言模型中,对于验证集文本,同样进行标记化(Tokenizing)和数字化(Numericalizing);
分类模型中,直接使用语言模型中标记化(Tokenizing)和数字化(Numericalizing)之后的词汇(vocabs)。并且读入标签(labels)。
因为我们的数据量有数十万,因此执行起来,会花上几分钟。
结束之后,我们来看看数据载入是否正常。
data_lm.train_ds.vocab_size

训练数据里面,词汇一共有60002条。
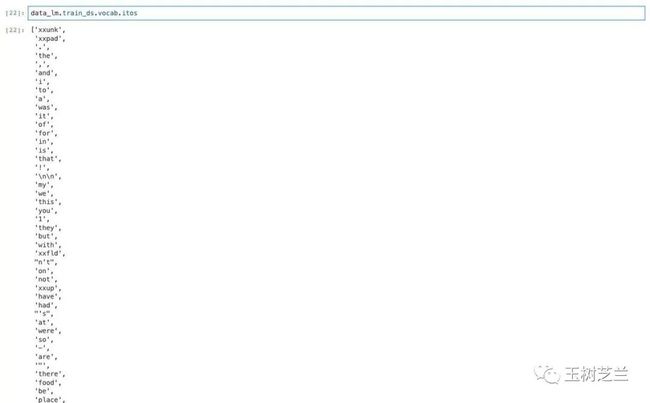
我们看看,词汇的索引是怎么样的:
data_lm.train_ds.vocab.itos
分类器里面,训练集标签正确载入了吗?
data_lm.train_ds.labels

验证集的呢?
data_lm.valid_ds.labels

数据载入后,我们就要开始借来预训练语言模型,并且进行微调了。
语言模型
本文使用 fast.ai 自带的预训练语言模型 wt103_v1,它是在 Wikitext-103 数据集上训练的结果。
我们把它下载下来:
model_path = path/'models'
model_path.mkdir(exist_ok=True)
url = 'http://files.fast.ai/models/wt103_v1/'
download_url(f'{url}lstm_wt103.pth', model_path/'lstm_wt103.pth')
download_url(f'{url}itos_wt103.pkl', model_path/'itos_wt103.pkl')

左侧边栏里,在数据目录下,我们会看到一个新的文件夹,叫做 models 。

其中包括两个文件:

好了,现在数据、语言模型预训练参数都有了,我们要构建一个 RNNLearner ,来生成我们自己的语言模型。
learn = RNNLearner.language_model(data_lm, pretrained_fnames=['lstm_wt103', 'itos_wt103'], drop_mult=0.5)
这里,我们指定了语言模型要读入的文本数据为 data_lm,预训练的参数为刚刚下载的两个文件,第三个参数 drop_mult 是为了避免过拟合,而设置的 Dropout 比例。
下面,我们还是让模型用 one cycle policy 进行训练。如果你对细节感兴趣,可以点击这个链接了解具体内容。
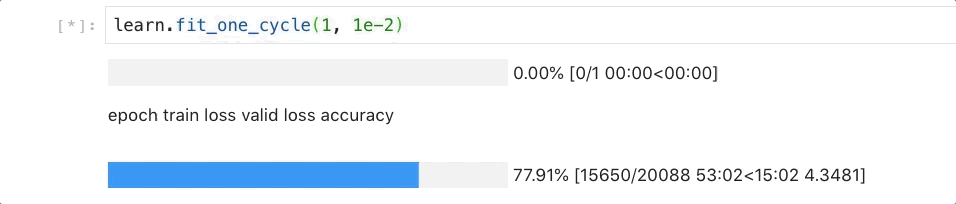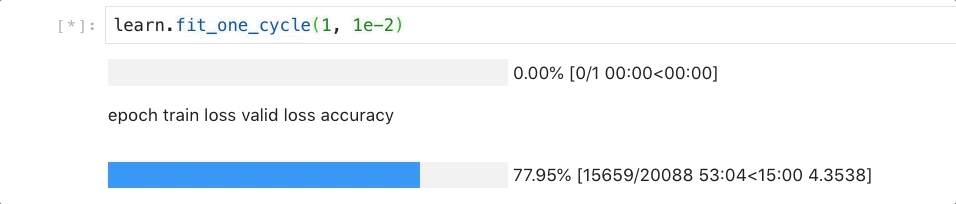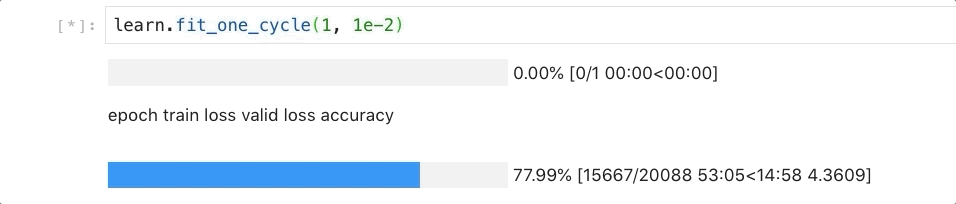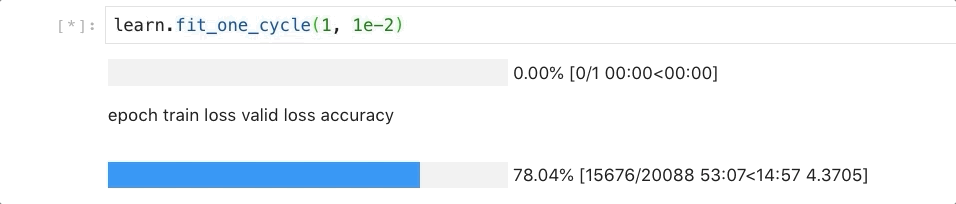
learn.fit_one_cycle(1, 1e-2)
因为我们的数据集包含数十万条目,因此训练时间,大概需要1个小时左右。请保持耐心。

50多分钟后,还在跑,不过已经可以窥见曙光了。
当命令成功执行后,我们可以看看目前的语言模型和我们的训练数据拟合程度如何。

你可能会觉得,这个准确率也太低了!
没错,不过要注意,这可是语言模型的准确率,并非是分类模型的准确率。所以,它和我们之前在这张表格里看到的结果,不具备可比性。
我们对于这个结果,不够满意,怎么办呢?
方法很简单,我们微调它。
回顾下图,刚才我们实际上是冻结了预训练模型底层参数,只用头部层次拟合我们自己的训练数据。
微调的办法,是不再对预训练的模型参数进行冻结。“解冻”之后,我们依然使用“歧视性学习速率”(discriminative learning rate)进行微调。
如果你忘了“歧视性学习速率”(discriminative learning rate)是怎么回事儿,请参考《如何用 Python 和 fast.ai 做图像深度迁移学习?》一文的“微调”一节。
注意这种方法,既保证靠近输入层的预训练模型结构不被破坏,又尽量让靠近输出层的预训练模型参数尽可能向着我们自己的训练数据拟合。
learn.unfreeze()
learn.fit_one_cycle(1, 1e-3)
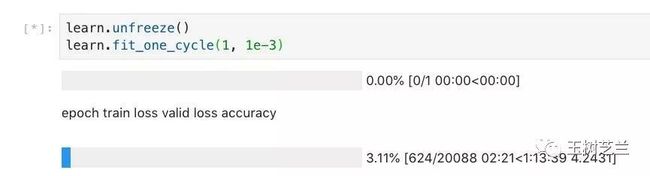
好吧,又是一个多小时。出去健健身,活动一下吧。
当你准时回来的时候,会发现模型的效能已经提升了一大截。
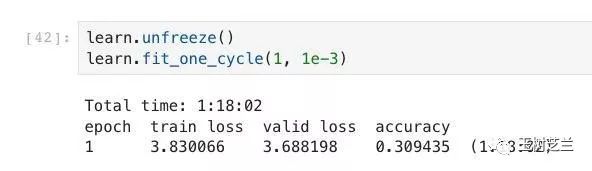
前前后后,你已经投入了若干小时的训练时间,就为了打造这个符合任务需求的语言模型。
现在模型训练好了,我们一定不能忘记做的工作,是把参数好好保存下来。
learn.save_encoder('ft_enc')
这样,下次如果你需要使用这个任务的语言模型,就不必拿 wt103_v1 从头微调了。而只需要读入目前存储的参数即可。
分类
语言模型微调好了,下面我们来构造分类器。
learn = RNNLearner.classifier(data_clas, drop_mult=0.5)
learn.load_encoder('ft_enc')
learn.fit_one_cycle(1, 1e-2)
虽然名称依然叫做 learn ,但注意这时候我们的模型,已经是分类模型,而不再是语言模型了。我们读入的数据,也因应变化成了 data_clas ,而非 data_lm 。
这里,load_encoder 就是把我们的语言模型参数,套用到分类模型里。
我们还是执行 "one cycle policy" 。

这次,在20多分钟的训练之后,我们语言模型在分类任务上得出了第一次成绩。
接近95%的准确率,好像很不错嘛!
但是,正如我在《文科生用机器学习做论文,该写些什么?》一文中给你指出的那样,对于别人已经做了模型的分类任务,你的目标就得是和别人的结果去对比了。
回顾别人的结果:
对,最高准确率是 95.64% ,我们的模型,还是有差距的。
怎么办?
很简单,我们刚刚只是微调了语言模型而已。这回,我们要微调分类模型。
先做一个省事儿的。就是对于大部分层次,我们都保持冻结。只把分类模型的最后两层解冻,进行微调。
learn.freeze_to(-2)
learn.fit_one_cycle(1, slice(5e-3/2., 5e-3))
半小时以后,我们获得了这样的结果:
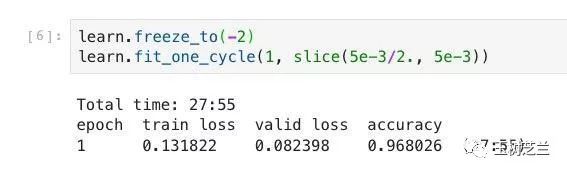
这次,我们的准确率,已经接近了97% ,比别人的 95.64% 要高了。
而且,请注意,此时训练损失(train loss)比起验证损失(valid loss)要高。没有迹象表明过拟合发生,这意味着模型还有改进的余地。
你如果还不满意,那么咱们就干脆把整个儿模型解冻,然后再来一次微调。
learn.unfreeze()
learn.fit_one_cycle(1, slice(2e-3/100, 2e-3))
因为微调的层次多了,参数自然也多了许多。因此训练花费时间也会更长。大概一个小时以后,你会看到结果:

准确率已经跃升到了 97.28%。
再次提醒,此时训练损失(train loss)依然比验证损失(valid loss)高。模型还有改进的余地……
对比
虽然我们的深度学习模型,实现起来非常简单。但是把咱们2018年做出来的结果,跟2015年的文章对比,似乎有些不大公平。
于是,我在 Google Scholar 中,检索 yelp polarity ,并且把检索结果的年份限定在了2017年以后。

对第一屏上出现的全部文献,我一一打开,查找是否包含准确率对比的列表。所有符合的结果,我都列在了下面,作为对比。
下表来自于:Sun, J., Ma, X., & Chung, T. S. (2018). Exploration of Recurrent Unit in Hierarchical Attention Neural Network for Sentence Classification. 한국정보과학회 학술발표논문집, 964-966.

注意这里最高的数值,是 93.75 。
下表来自于:Murdoch, W. J., & Szlam, A. (2017). Automatic rule extraction from long short term memory networks. arXiv preprint arXiv:1702.02540.
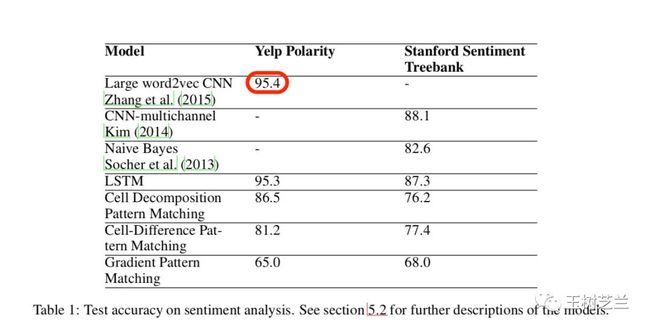
这里最高的数值,是 95.4 。
下表来自于:Chen, M., & Gimpel, K. (2018). Smaller Text Classifiers with Discriminative Cluster Embeddings. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers) (Vol. 2, pp. 739-745).
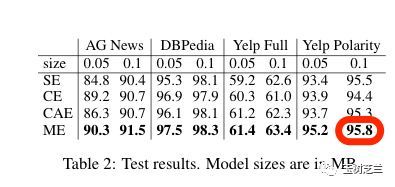
这里最高的数值,是 95.8 。
下表来自于:Shen, D., Wang, G., Wang, W., Min, M. R., Su, Q., Zhang, Y., … & Carin, L. (2018). Baseline needs more love: On simple word-embedding-based models and associated pooling mechanisms. arXiv preprint arXiv:1805.09843.

这里最高的数值,是 95.81 。
这是一篇教程,并非学术论文。所以我没有穷尽查找目前出现的最高 Yelp Reviews Polarity 分类结果。
另外,给你留个思考题——咱们这种对比,是否科学?欢迎你在留言区,把自己的见解反馈给我。
不过,通过跟这些近期文献里面的最优分类结果进行比较,相信你对咱们目前达到的准确率,能有较为客观的参照。
小结
本文我们尝试把迁移学习,从图像分类领域搬到到了文本分类(自然语言处理)领域。
在 fast.ai 框架下,我们的深度学习分类模型代码很简单。刨去那些预处理和展示数据的部分,实际的训练语句,只有10几行而已。
回顾一下,主要的步骤包括:
获得标注数据,分好训练集和验证集;
载入语言模型数据,和分类模型数据,进行标记化和数字化预处理;
读入预训练参数,训练并且微调语言模型;
用语言模型调整后的参数,训练分类模型;
微调分类模型
值得深思的是,在这种流程下,你根本不需要获得大量的标注数据,就可以达到非常高的准确率。
在 Jeremy Howard 的论文里,就有这样一张对比图,令人印象非常深刻。
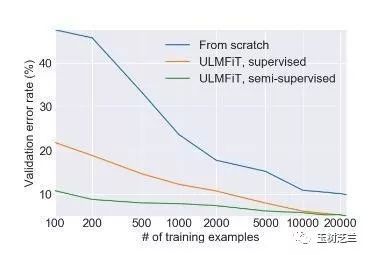
同样要达到 20% 左右的验证集错误率,从头训练的话,你需要超过1000个数据,而如果使用半监督通用语言模型微调(ULMFiT, semi-supervised),你只需要100个数据。如果你用的是监督通用语言模型微调(ULMFiT, supervised),100个数据已经能够直接让你达到10%的验证集错误率了。
这给那些小样本任务,尤其是小语种上的自然语言处理任务,带来了显著的机遇。
Czapla 等人,就利用这种方法,轻松赢得了 PolEval'18 比赛的第一名,领先第二名 35% 左右。

感兴趣的话,他们的论文在这里。
Google 给你的300美金,应该还剩余一些吧?
找个自己感兴趣的文本分类任务,实际动手跑一遍吧。
祝(深度)学习愉快!
喜欢请点赞和打赏。还可以微信关注和置顶我的公众号“玉树芝兰”(nkwangshuyi)。
如果你对 Python 与数据科学感兴趣,不妨阅读我的系列教程索引贴《如何高效入门数据科学?》,里面还有更多的有趣问题及解法。
由于微信公众号外部链接的限制,文中的部分链接可能无法正确打开。如有需要,请点击文末的“阅读原文”按钮,访问可以正常显示外链的版本。
知识星球入口在这里:
