MNIST数据集介绍
MNIST数据集官网:http://yann.lecun.com/exdb/mnist/
MNIST数据库是非常经典的一个数据集,就像你学编程起初写一个“Hello Word”的程序一样,学Deep Learning你就会写识别MNIST数据集的Model。
MNIST数据集是由0〜9手写数字图片和数字标签所组成的,由60000个训练样本和10000个测试样本组成,每个样本都是一张28 * 28像素的灰度手写数字图片。如下图所示。

MNIST数据库一共有四个文件案,分别为
1. train-images-idx3-ubyte.gz:训练集图片(9912422字节),55000张训练集,5000张验证集
2. train-labels-idx1-ubyte.gz:训练集图片对应的标签(28881字节),
3. t10k-images-idx3-ubyte .gz:测试集图片(1648877字节),10000张图片
4. t10k-labels-idx1-ubyte.gz:测试集图片对应的标签(4542字节)
图片是指0〜9手写数字图片,而标签则是对应该图片之实际数字。
MNIST 数据集下载及可视化
TensorFlow提供了一个库可以对MNIST数据集进行下载和解压。具体的是使用TensorFlow中input_data.py脚本来读取数据及标签,使用这种方式时,可以不用事先下载好数据集,它会自动下载并存放到你指定的位置。具体程序如下所示:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import matplotlib.pyplot as plt
# MNIST_data指的是存放数据的文件夹路径,one_hot=True 为采用one_hot的编码方式编码标签
mnist = input_data.read_data_sets('../datasets/MNIST_data/', one_hot=True)
# load data
train_X = mnist.train.images
train_Y = mnist.train.labels
print(train_X.shape, train_Y.shape) # 输出训练集样本和标签的大小
# 查看数据,例如训练集中第一个样本的内容和标签
print(train_X[0]) # 是一个包含784个元素且值在[0,1]之间的向量
print(train_Y[0])
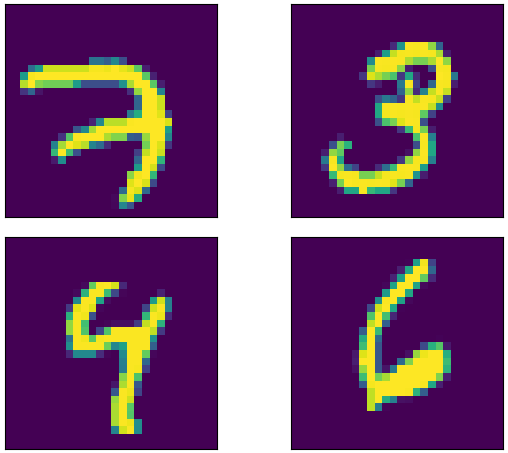
# 可视化样本,下面是输出了训练集中前4个样本
fig, ax = plt.subplots(nrows=2, ncols=2, sharex='all', sharey='all')
ax = ax.flatten()
for i in range(4):
img = train_X[i].reshape(28, 28)
# ax[i].imshow(img,cmap='Greys')
ax[i].imshow(img)
ax[0].set_xticks([])
ax[0].set_yticks([])
plt.tight_layout()
plt.show()
运行结果为:
输出训练样本和标签的大小
(55000, 784) (55000, 10)
查看第一个样本的数据(数据很多,做了部分省略):
[0. 0. 0. 0.3803922 0.37647063 0.3019608
0.46274513 0.2392157 0. 0. 0. 0.]
print("查看第一个样本的标签"):
[0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]
训练集中前4个样本图片显示:
计算机视觉联盟 报道 | 公众号 CVLianMeng