流处理旅程——storm的部署
核心:
1、环境准备
2、storm的本地启动模式
3、storm的分布安装
4、storm的参数介绍
5、storm启动
6、storm UI 各项属性介绍
7、storm的停止
1、环境
1、jdk1.7
2、zookeeper
3、SSH服务
4、python2.7
5、准备3台机器
master 192.168.18.144
slave1 192.168.18.145
slave2 192.168.18.146
6、zookeeper的安装请看
http://blog.csdn.net/paicmis/article/details/53264178
2、storm的启动模式
storm有两种模式可以启动操作:本地模式和分布式模式
2、1本地模式
本地模式在一个进程中使用线程模拟storm集群的所有功能,这样使用本地模式进行开发和测试将非常方便,本地模式运行topology与在集群上运行topology类似,但是提交拓扑任务是本地机器上,
简单地使用localcluster类,就能创建一个进程内(in-process)集群,例如
import backtype,Storm.LocalCluster;
LocalCluster cluster=new LocalCluster();
本地模式的常规配置需要主要如下几个参数
1、Config.TOPOLOGY_MAX_TASK_PARALLELISM:单个组件产生的最大线程数。在通常情况下,生产环境的拓扑有大量的并行线程(数百个线程);当尝试在本地模式测试拓扑时,它会使本地集群处于不合理负载,这个配置容易控制并行度。
2、Config.TOPOLOGY_DEBUG:当设置为true时,spout或bolt每发射一个消息,storm就记录一个消息,这对程序调试非常有用。
在启动storm后台进程时,需要对conf/storm.yaml配置文件中设置的storm.local.dir目录具有写权限。storm后台进程启动后,将在storm安装部署目录下的logs/子目录生成各个进程的日志文件
2、2 分布式模式
分布式模式提交的拓扑任务可以放在storm集群的任意一个节点执行,下面讲解的安装及部署均使用了此模式
3、安装部署storm集群
3、1先解压storm
[root@master software]# tar -xvf apache-storm-1.0.2.tar -C /opt/
3、2修改配置文件
进入storm目录下的conf目录修改storm.yaml文件
修改 conf/storm.yaml 里面的内容
########### These MUST be filled in for a storm configuration
storm.zookeeper.servers:
- "192.168.18.144"
- "192.168.18.145"
- "192.168.18.146"
nimbus.seeds: ["192.168.18.144"]
#
storm.local.dir: "/opt/storm/data"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
#
#
# ##### These may optionally be filled in:
#
## List of custom serializations
# topology.kryo.register:
# - org.mycompany.MyType
# - org.mycompany.MyType2: org.mycompany.MyType2Serializer
#
## List of custom kryo decorators
# topology.kryo.decorators:
# - org.mycompany.MyDecorator
#
## Locations of the drpc servers
# drpc.servers:
# - "server1"
# - "server2"
## Metrics Consumers
# topology.metrics.consumer.register:
# - class: "org.apache.storm.metric.LoggingMetricsConsumer"
# parallelism.hint: 1
# - class: "org.mycompany.MyMetricsConsumer"
# parallelism.hint: 1
# argument:
# - endpoint: "metrics-collector.mycompany.org"注意:
1、zookeeper集群的地址,如果zookeeper集群使用的不是默认端口,那么还需要storm.zookeeper.port选项来指定
2、storm.local.dir:Nimbus和Supervisor进程用于存储少量状态,如JAR、配置文件等的本地磁盘目录,需要提前创建目录并给以足够的访问权限,然后再storm.yaml中配置该目录
3、nimbus.host:storm集群Nimbus机器地址,各个Supervisor工作节点需要知道哪个节点是
Nimbus,以便下载Topology的JAR、配置等文件
4、storm的参数介绍
其他的参数默认值如下
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
########### These all have default values as shown
########### Additional configuration goes into storm.yaml
java.library.path: "/usr/local/lib:/opt/local/lib:/usr/lib"
### storm.* configs are general configurations
# the local dir is where jars are kept
storm.local.dir: "storm-local"
storm.zookeeper.servers:
- "localhost"
storm.zookeeper.port: 2181
storm.zookeeper.root: "/storm"
storm.zookeeper.session.timeout: 20000
storm.zookeeper.connection.timeout: 15000
storm.zookeeper.retry.times: 5
storm.zookeeper.retry.interval: 1000
storm.zookeeper.retry.intervalceiling.millis: 30000
storm.zookeeper.auth.user: null
storm.zookeeper.auth.password: null
storm.cluster.mode: "distributed" # can be distributed or local
storm.local.mode.zmq: false
storm.thrift.transport: "backtype.storm.security.auth.SimpleTransportPlugin"
storm.principal.tolocal: "backtype.storm.security.auth.DefaultPrincipalToLocal"
storm.group.mapping.service: "backtype.storm.security.auth.ShellBasedGroupsMapping"
storm.messaging.transport: "backtype.storm.messaging.netty.Context"
storm.nimbus.retry.times: 5
storm.nimbus.retry.interval.millis: 2000
storm.nimbus.retry.intervalceiling.millis: 60000
storm.auth.simple-white-list.users: []
storm.auth.simple-acl.users: []
storm.auth.simple-acl.users.commands: []
storm.auth.simple-acl.admins: []
storm.meta.serialization.delegate: "backtype.storm.serialization.GzipThriftSerializationDelegate"
### nimbus.* configs are for the master
nimbus.host: "localhost"
nimbus.thrift.port: 6627
nimbus.thrift.threads: 64
nimbus.thrift.max_buffer_size: 1048576
nimbus.childopts: "-Xmx1024m"
nimbus.task.timeout.secs: 30
nimbus.supervisor.timeout.secs: 60
nimbus.monitor.freq.secs: 10
nimbus.cleanup.inbox.freq.secs: 600
nimbus.inbox.jar.expiration.secs: 3600
nimbus.task.launch.secs: 120
nimbus.reassign: true
nimbus.file.copy.expiration.secs: 600
nimbus.topology.validator: "backtype.storm.nimbus.DefaultTopologyValidator"
nimbus.credential.renewers.freq.secs: 600
nimbus.impersonation.authorizer: "backtype.storm.security.auth.authorizer.ImpersonationAuthorizer"
### ui.* configs are for the master
ui.host: 0.0.0.0
ui.port: 8080
ui.childopts: "-Xmx768m"
ui.actions.enabled: true
ui.filter: null
ui.filter.params: null
ui.users: null
ui.header.buffer.bytes: 4096
ui.http.creds.plugin: backtype.storm.security.auth.DefaultHttpCredentialsPlugin
ui.http.x-frame-options: DENY
logviewer.port: 8000
logviewer.childopts: "-Xmx128m"
logviewer.cleanup.age.mins: 10080
logviewer.appender.name: "A1"
logs.users: null
drpc.port: 3772
drpc.worker.threads: 64
drpc.max_buffer_size: 1048576
drpc.queue.size: 128
drpc.invocations.port: 3773
drpc.invocations.threads: 64
drpc.request.timeout.secs: 600
drpc.childopts: "-Xmx768m"
drpc.http.port: 3774
drpc.https.port: -1
drpc.https.keystore.password: ""
drpc.https.keystore.type: "JKS"
drpc.http.creds.plugin: backtype.storm.security.auth.DefaultHttpCredentialsPlugin
drpc.authorizer.acl.filename: "drpc-auth-acl.yaml"
drpc.authorizer.acl.strict: false
transactional.zookeeper.root: "/transactional"
transactional.zookeeper.servers: null
transactional.zookeeper.port: null
### supervisor.* configs are for node supervisors
# Define the amount of workers that can be run on this machine. Each worker is assigned a port to use for communication
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
supervisor.childopts: "-Xmx256m"
supervisor.run.worker.as.user: false
#how long supervisor will wait to ensure that a worker process is started
supervisor.worker.start.timeout.secs: 120
#how long between heartbeats until supervisor considers that worker dead and tries to restart it
supervisor.worker.timeout.secs: 30
#how many seconds to sleep for before shutting down threads on worker
supervisor.worker.shutdown.sleep.secs: 1
#how frequently the supervisor checks on the status of the processes it's monitoring and restarts if necessary
supervisor.monitor.frequency.secs: 3
#how frequently the supervisor heartbeats to the cluster state (for nimbus)
supervisor.heartbeat.frequency.secs: 5
supervisor.enable: true
supervisor.supervisors: []
supervisor.supervisors.commands: []
### worker.* configs are for task workers
worker.childopts: "-Xmx768m"
worker.gc.childopts: ""
worker.heartbeat.frequency.secs: 1
# control how many worker receiver threads we need per worker
topology.worker.receiver.thread.count: 1
task.heartbeat.frequency.secs: 3
task.refresh.poll.secs: 10
task.credentials.poll.secs: 30
zmq.threads: 1
zmq.linger.millis: 5000
zmq.hwm: 0
storm.messaging.netty.server_worker_threads: 1
storm.messaging.netty.client_worker_threads: 1
storm.messaging.netty.buffer_size: 5242880 #5MB buffer
# Since nimbus.task.launch.secs and supervisor.worker.start.timeout.secs are 120, other workers should also wait at least that long before giving up on connecting to the other worker. The reconnection period need also be bigger than storm.zookeeper.session.timeout(default is 20s), so that we can abort the reconnection when the target worker is dead.
storm.messaging.netty.max_retries: 300
storm.messaging.netty.max_wait_ms: 1000
storm.messaging.netty.min_wait_ms: 100
# If the Netty messaging layer is busy(netty internal buffer not writable), the Netty client will try to batch message as more as possible up to the size of storm.messaging.netty.transfer.batch.size bytes, otherwise it will try to flush message as soon as possible to reduce latency.
storm.messaging.netty.transfer.batch.size: 262144
# Sets the backlog value to specify when the channel binds to a local address
storm.messaging.netty.socket.backlog: 500
# By default, the Netty SASL authentication is set to false. Users can override and set it true for a specific topology.
storm.messaging.netty.authentication: false
# default number of seconds group mapping service will cache user group
storm.group.mapping.service.cache.duration.secs: 120
### topology.* configs are for specific executing storms
topology.enable.message.timeouts: true
topology.debug: false
topology.workers: 1
topology.acker.executors: null
topology.tasks: null
# maximum amount of time a message has to complete before it's considered failed
topology.message.timeout.secs: 30
topology.multilang.serializer: "backtype.storm.multilang.JsonSerializer"
topology.skip.missing.kryo.registrations: false
topology.max.task.parallelism: null
topology.max.spout.pending: null
topology.state.synchronization.timeout.secs: 60
topology.stats.sample.rate: 0.05
topology.builtin.metrics.bucket.size.secs: 60
topology.fall.back.on.java.serialization: true
topology.worker.childopts: null
topology.executor.receive.buffer.size: 1024 #batched
topology.executor.send.buffer.size: 1024 #individual messages
topology.transfer.buffer.size: 1024 # batched
topology.tick.tuple.freq.secs: null
topology.worker.shared.thread.pool.size: 4
topology.disruptor.wait.strategy: "com.lmax.disruptor.BlockingWaitStrategy"
topology.spout.wait.strategy: "backtype.storm.spout.SleepSpoutWaitStrategy"
topology.sleep.spout.wait.strategy.time.ms: 1
topology.error.throttle.interval.secs: 10
topology.max.error.report.per.interval: 5
topology.kryo.factory: "backtype.storm.serialization.DefaultKryoFactory"
topology.tuple.serializer: "backtype.storm.serialization.types.ListDelegateSerializer"
topology.trident.batch.emit.interval.millis: 500
topology.testing.always.try.serialize: false
topology.classpath: null
topology.environment: null
topology.bolts.outgoing.overflow.buffer.enable: false
topology.disruptor.wait.timeout.millis: 1000
dev.zookeeper.path: "/tmp/dev-storm-zookeeper"5、storm启动
5、1创建local目录
[root@master conf]# mkdir /opt/storm/data5、2通过scp拷贝到其他服务器上
[root@master conf]# scp -r apache-storm-1.0.2/ 192.168.18.146:/opt/
[root@master conf]# scp -r apache-storm-1.0.2/ 192.168.18.145:/opt/5、3启动zookeeper
在启动storm之前需要启动zookeeper
[root@master conf]# sh /opt/zookeeper-3.4.5/bin/zkServer.sh start
5、4启动storm
5、4、1 先启动 nimbus
[root@master ~]# sh /opt/apache-storm-1.0.2/bin/storm nimbus >/dev/null 2>&1 &
5、4、2 启动supervisor
[root@slave2 apache-storm-1.0.2]# sh /opt/apache-storm-1.0.2/bin/storm supervisor >/dev/null 2>&1 &
5、4、3 启动ui
[root@master conf]# sh /opt/apache-storm-1.0.2/bin/storm ui >/dev/null 2>&1 &
5、5 用jps查看进程
[root@master conf]# jps
12731 QuorumPeerMain
13577 core
13675 Jps
13267 nimbus
13468 supervisor
[root@slave1 apache-storm-1.0.2]# jps
12562 QuorumPeerMain
12716 supervisor
12808 Jps
[root@slave2 apache-storm-1.0.2]# jps
12921 Jps
12829 supervisor
12667 QuorumPeerMain5、6查看UI
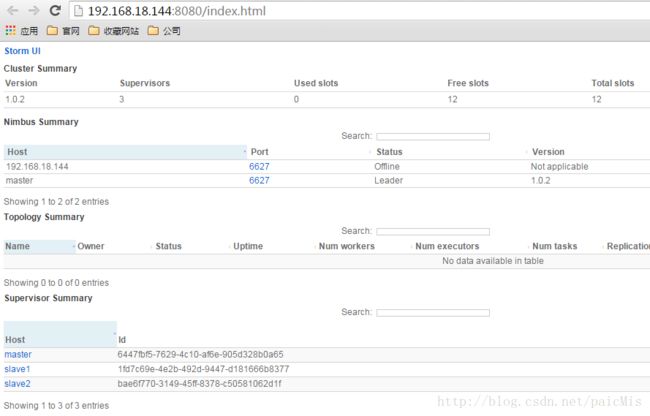
通过 http://192.168.18.144:8080/index.html 访问UI,在storm主控节点上运行,启动ui后台程序,并放在后台执行,启动后可以观察集群的worker资源使用情况、topology的运行状态等信息
6、storm UI 各项属性介绍
6、1 Cluster Summary 集群统计信息
Version :storm集群的版本
Supervisors :storm集群中supervisor的数量
used slots:使用的slot的数
free slots :剩余slot数
total slots :总的slot数
executors:执行者数量
tasks:运行的任务数
6、2 Topology Summary 拓扑统计信息
name :拓扑的名称
owner :那个用户提交的
status:拓扑的状态 包括 active 、inactive、killed、rebalancing等
uptime:拓扑运行的时间
num workers :运行的worker数
num executors :运行的执行者数
num tasks :运行的task数
replication count :副本数量
assigned Men :消耗的内存大小
scheduler info :运行的信息
6、3 Supervisor Summary工作节点统计信息
host:supervisor主机名
id:由storm生成的工作节点ID
uptime:supervisor启动的时间
slots:supervisor的slot数
used slots:使用的slot数
used Men :使用的内存
verison :storm的版本
7、停止storm集群
在本地模式下停止storm的方式比较简单,就是调用shutdown方法,
import backtype.storm.LocalCluster;
LocalCluster cluster=new LocalCluster();
cluster.shutdown();
分布式模式停止集群的方式比较麻烦,因为角色进程分布在不同的节点上,停止的方法是,直接杀掉每个节点运行的Nimbus或者Supervisor进程。