深入理解anchor
在博客SSD原理解读-从入门到精通中提到了anchor作用:通过anchor设置每一层实际响应的区域,使得某一层对特定大小的目标响应。很多人肯定有这么一个疑问:那anchor到底可以设置到多大呢?,本文尝试对anchor的大小进行了一系列的探索,同时借鉴了SSD的anchor机制,提出了MTCNN中的anchor机制,能够显著提高MTCNN的精度。
文章目录
- 理论感受野大小的计算
- 经典SSD网络anchor的设置
- anchor大小的探索
- AP
- loss
- 实验分析
- 滑动窗口,感受野与anchor的关系
- MTCNN中的anchor机制
- MTCNN训练机制的问题
- MTCNN中的anchor机制
- 实验结果与分析
- 结束语
理论感受野大小的计算
由于本文在讨论anchor大小的时候,都是与理论感受野大小相关的,这里有必要说一下理论感受野大小的计算。关于理论感受野大小的计算,有一篇很好的文章:A guide to receptive field arithmetic for Convolutional Neural Networks,国内也有这篇文章的翻译,在网上都可以找到。关于这篇文章就不展开说了。这里直接给出我用的计算感受野大小的python代码,直接修改网络参数就可以计算理论感受野大小,非常方便。
def outFromIn(isz, net, layernum):
totstride = 1
insize = isz
for layer in range(layernum):
fsize, stride, pad = net[layer]
outsize = (insize - fsize + 2*pad) / stride + 1
insize = outsize
totstride = totstride * stride
return outsize, totstride
def inFromOut(net, layernum):
RF = 1
for layer in reversed(range(layernum)):
fsize, stride, pad = net[layer]
RF = ((RF -1)* stride) + fsize
return RF
# 计算感受野和步长,[11,4,0]:[卷积核大小,步长,pad]
def ComputeReceptiveFieldAndStride():
net_struct = {'PNet': {'net':[[3,2,0],[2,2,0],[3,1,0],[3,2,0],[1,1,0]],'name':['conv1','pool1','conv2','conv3','conv4-3']}}
imsize = 512
print ("layer output sizes given image = %dx%d" % (imsize, imsize))
for net in net_struct.keys():
print ('************net structrue name is %s**************'% net)
for i in range(len(net_struct[net]['net'])):
p = outFromIn(imsize,net_struct[net]['net'], i+1)
rf = inFromOut(net_struct[net]['net'], i+1)
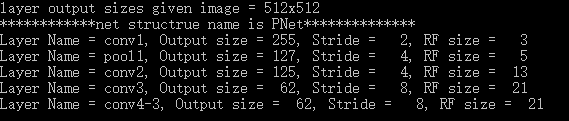
print ("Layer Name = %s, Output size = %3d, Stride = %3d, RF size = %3d" % (net_struct[net]['name'][i], p[0], p[1], rf))
运行结果如下
除了通过公式计算,还有一种更加方便的可以用于手工计算的方式。这里给出几条规则:
- 初始featuremap层的感受野是1
- 每经过一个convkxk s1(卷积核大小为k,步长为1)的卷积层,感受野 r = r+ (k - 1),常用k=3感受野 r = r + 2,k=5感受野r= r + 4
- 每经过一个convkxk s2的卷积层或max/avg pooling层,感受野 r = (r x 2) + (k -2),常用卷积核k=3, s=2,感受野 r = r x 2 + 1,卷积核k=7, s=2, 感受野r = r x 2 + 5
- 每经过一个maxpool2x2 s2的max/avg pooling下采样层,感受野 r = r x 2
- 经过conv1x1 s1,ReLU,BN,dropout等元素级操作不会改变感受野
- 经过FC层和GAP层,感受野就是整个输入图像
- 全局步长等于经过所有层的步长累乘
具体在计算的时候,采用bottom-up的方式。
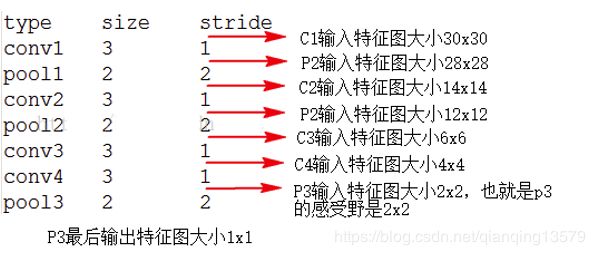
要计算哪一层的感受野,就将该层的输出设置为1,然后依次向前计算,比如下图中的网络结构中,要计算pool3的感受野,将pool3的输出设置为1,就可以得到conv1的输入大小为30x30,也就是P3的感受野大小为30。
按照这个算法,我们可以算出SSD300中conv4-3的理论感受野:
r =(((1 +2 +2+2+2 )x2 +2+2+2 )x2 +2+2 )x2 +2+2 = 108
注意:由于conv4-3后面接了3x3的卷积核做分类和回归,所以在计算感受野大小的时候,需要将用于分类和回归的3x3的卷积核也考虑进去。
经典SSD网络anchor的设置
下面我们来看一下经典网络中anchor大小是如何设置的
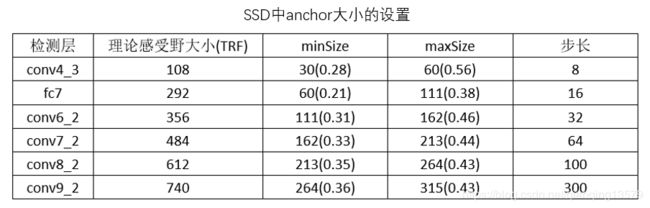
其中( )中的数字表示:anchor/理论感受野,下文中使用该数值表示anchor的大小。
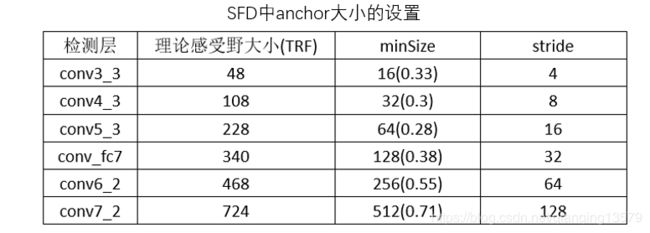
注:SFD:Single Shot Scale-invariant Face Detector
于老师开源的检测器:ShiqiYu/libfacedetection中anchor的设置
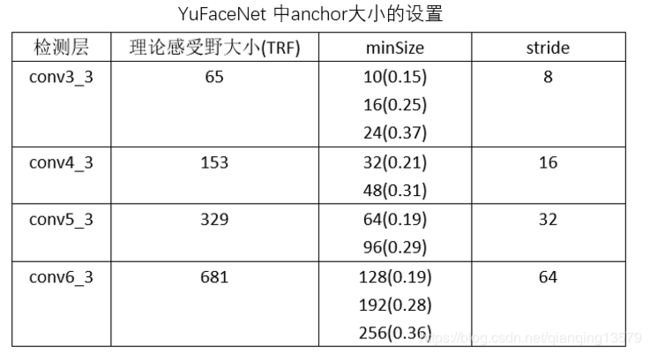

观察SSD,SFD,YuFace,RPN中的anchor设计,我们可以看出anchor的大小基本在[0.1,0.7]之间。RPN网络比较特别,anchor的大小超出了感受野大小。
anchor大小的探索
下面我做了一系列实验探索anchor大小的范围,分别在数据集A和数据集B上,使用SFD_VGG16和SSD_YuFaceNet两个模型,所有层的anchor大小分别设计为0.1~0.9,观察模型的AP和loss大小。
注:SFD_VGG16和SSD_YuFaceNet分别使用的是SFD开源的网络和ShiqiYu/libfacedetection开源的网络
AP
数据集A:
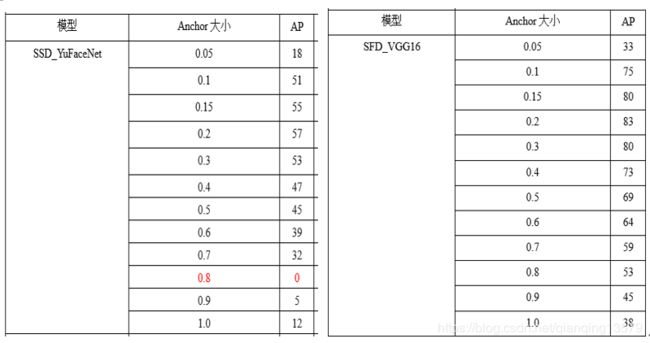
数据集B:

loss
数据集A:
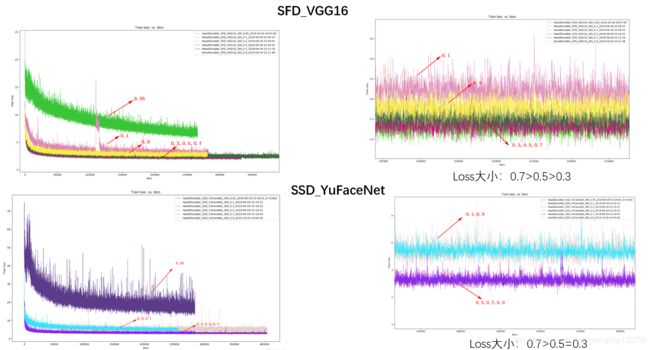
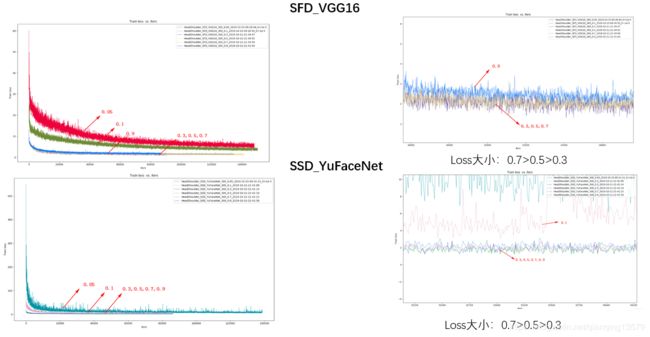
数据集B:
实验分析
通过对经典网络的分析,以及实验的结果,可以观察到以下现象:
- anchor可以设置的范围较大,从实验结果来看,0.05~1.0基本都可以收敛,这也解释了为什么FasterRCNN中的RPN网络anchor大小可以超过感受野。从loss来看,anchor太大或者大小收敛效果都不好,甚至会出现不收敛的情况。这一点也很好理解,如果anchor太大,导致目标上下文信息较少,而如果anchor太小,又会导致没有足够多的信息。
- 综合AP的值以及loss的大小,我们可以看出,anchor在0.2~0.7之间收敛效果较好,这个结论与SSD经典网络的设置基本一致。这个范围既可以保证目标有足够多的上下文信息,也不会因为目标太小没有足够多的信息。
注:由于目前实验数据还不够充分,这个范围可能并不准确,欢迎大家留言讨论。
滑动窗口,感受野与anchor的关系
首先区分一下这几个比较容易混淆的概念:
- 滑动窗口:使得某一层输出大小为1的输入大小就是该层的滑动窗口大小。比如MTCNN中PNet,滑动窗口大小为12x12
- 理论感受野:影响某个神经元输出的输入区域,也就是该层能够感知到的区域
- 有效感受野:理论感受野中间对输出有重要影响的区域
- anchor:预先设置的每一层实际响应的区域
滑动窗口大小和理论感受野是一个网络的固有属性,一旦网络结构确定了,这两个参数就确定了,有效感受野是可以通过训练改变的,anchor是通过人工手动设置的。理论感受野,有效感受野,滑动窗口是对齐的, anchor设置过程中也要与感受野对齐,否则会影响检测效果。检测层上每个像素点都会对应一个理论感受野,滑动窗口以及anchor。
MTCNN中的anchor机制
MTCNN训练机制的问题
熟悉MTCNN的朋友应该都知道,训练MTCNN的时候需要事先生成三类样本:positive,part,negative.这三类样本是根据groundtruth的IOU来区分的,原论文中的设置是IOU<0.3的为negative,IOU>0.65的为positve,0.4
上图中生成的positive样本为,图中红色框为groundtruth,蓝色框为候选框

其中回归任务回归的就是两者之间的offset

回归的4个偏移量(公式不唯一):
( x 1 − x 1 ’ ) / w (x1-x1’)/w (x1−x1’)/w
( y 1 − y 1 ’ ) / h (y1-y1’)/h (y1−y1’)/h
( x 2 − x 2 ’ ) / w (x2-x2’)/w (x2−x2’)/w
( y 2 − y 2 ’ ) / h (y2-y2’)/h (y2−y2’)/h
对于小目标或者类似头肩这种目标,会出现一些问题

生成的positive样本如下:

基本上是一块黑色区域,没有太多有效信息。
对于小目标:

生成的positive是
![]()
这样的图像,这些图像是非常不利于训练的,而且MTCNN在训练的时候输入分辨率都比较小(比如12,24,48),将这些生成的图像resize到12,24或者48之后会导致有效信息更少,为了解决这个问题,我们需要包含目标更多的上下文信息,会更加容易识别。

MTCNN中的anchor机制
借鉴SSD中anchor的思想,提出了MTCNN中的anchor
SSD在训练过程中通过anchor与groundtruth的匹配来确定每一个anchor的类别,具体匹配过程:计算与每个anchor的IOU最大(>阈值)的那个groundtruth,如果找到了,那么该anchor就匹配到了这个groundtruth,该anchor就是positive样本,anchor的类别就是该groundtruth的类别,回归的offset就是anchor与groundtruth之间的偏移量。由于SSD的anchor通常都比理论感受野小,所以SSD会包含较多的上下文信息,如下图所示。

联想到MTCNN,在生成训练样本的时候,我们可以将候选框当成anchor,生成positive的过程就是SSD中的匹配过程,由于需要包含更多上下文信息,最后会对anchor进行扩边生成最后的训练样本 。
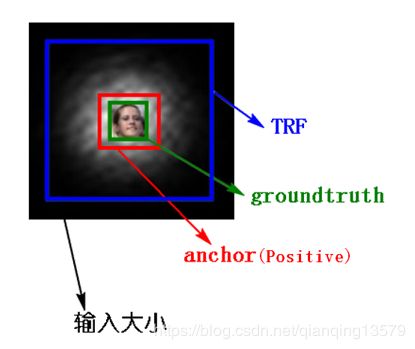
红色区域就是anchor也就是生成的positive样本,整个黑色区域就是对anchor做扩边后生成的训练样本,可以看到包含了更多的上下文信息。
实验结果与分析
在多种数据集上对anchor机制进行了实验。
数据集1:
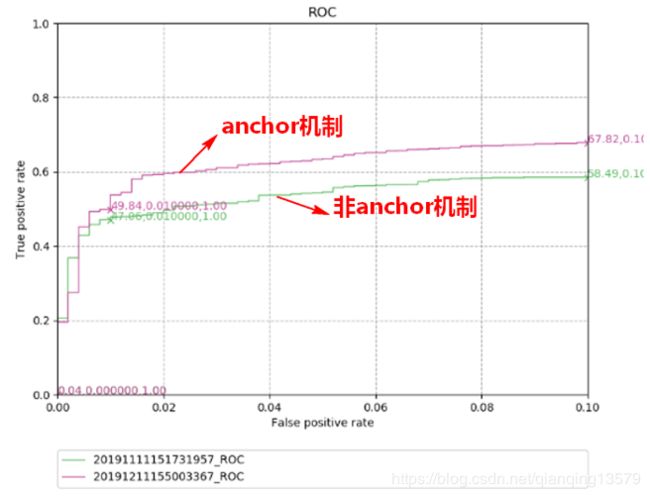
数据集2:
从实验结果我们可以看出,anchor机制可以显著提高检测器的精度。
结束语
关于anchor其实还有很多地方值得探索,本文只是总结了一下最近工作中对anchor的一些最新的认识,就当抛砖引玉,大家如果有关于anchor更好的解读欢迎一起讨论。
非常感谢您的阅读,如果您觉得这篇文章对您有帮助,欢迎扫码进行赞赏。
