Github复现之SSD
之前有个关于解决SSD错误的博客,虽然针对错误贴出了解决方法还是有一群人没解决问题,有可能是不同的问题出现了相同的错误,那我这次直接自己重新复现一边吧,之前的找不到了,再贴下链接:https://github.com/amdegroot/ssd.pytorch
环境:CUDA9.0、cudnn7.0.5、python3、pytorch1.1.0
其实这个项目的错误里面已经给出了你有可能遇到的重要错误,基本可以完成复现,我想可能有人没注意到,不要怪我啰嗦,我写这个是想让没用过GitHub的人也能复现的
常见错误1:
这个错误要改的地方比较多,我把你们可能遇到的错误都归为一个,修改的地方有3个,下面是错误,2个报错,1个训练nan异常情况
Traceback (most recent call last):
File ".\train.py", line 257, in <module>
train()
File ".\train.py", line 180, in train
loss_l, loss_c = criterion(out, targets)
File "E:\anaconda3\lib\site-packages\torch\nn\modules\module.py", line 493, in __call__
result = self.forward(*input, **kwargs)
File "E:\ssd.pytorch-master\layers\modules\multibox_loss.py", line 97, in forward
loss_c[pos] = 0 # filter out pos boxes for now
IndexError: The shape of the mask [4, 8732] at index 0 does not match the shape of the indexed tensor [34928, 1] at index 0
Traceback (most recent call last):
File ".\train.py", line 255, in <module>
train()
File ".\train.py", line 183, in train
loc_loss += loss_l.data[0]
IndexError: invalid index of a 0-dim tensor. Use tensor.item() to convert a 0-dim tensor to a Python number
iter 60 || Loss: 22.5068 || timer: 1.1719 sec.
iter 70 || Loss: nan || timer: 1.1639 sec.
iter 80 || Loss: nan || timer: 1.1948 sec.
iter 90 || Loss: nan || timer: 1.1709 sec.
iter 100 || Loss: nan || timer: 1.1888 sec.
iter 110 || Loss: nan || timer: 1.2108 sec.
iter 120 || Loss: nan || timer: 1.1928 sec.
iter 130 || Loss: nan || timer: 1.1729 sec.
iter 140 || Loss: nan || timer: 1.1719 sec.
iter 150 || Loss: nan || timer: 1.1709 sec.
以上错误解决在这里:
https://github.com/amdegroot/ssd.pytorch/issues/173
对应文件

修改1
这个基本就解决了这个错误,在下面的文件里调换96,97行

修改2
同样在上述文件的最后改:

修改3
与此同时还要修改train.py文件

常见错误2:
File ".\train.py", line 262, in <module>
train()
File ".\train.py", line 165, in train
images, targets = next(batch_iterator)
File "E:\anaconda3\lib\site-packages\torch\utils\data\dataloader.py", line 559, in __next__
indices = next(self.sample_iter) # may raise StopIteration
StopIteration
上面这个错误解决在这:https://github.com/amdegroot/ssd.pytorch/issues/214
在train.py文件里做如下修改
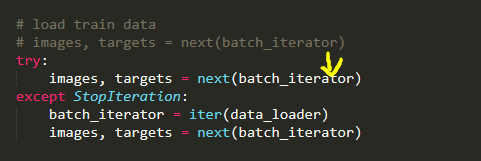
上面是解决主要错误的过程
下面把修改过的相关脚本贴出来,以防丢失,这里我复现还没用自己的数据,就是默认用了VOC2007,数据不大,需要的可以私信我,后面有时间试下自己的数据
常见错误3:
解决方法:https://github.com/amdegroot/ssd.pytorch/issues/224
下面这个错误是因为标注数据有问题,上面这个链接里有解决的方法
File ".\train.py", line 267, in <module>
train()
File ".\train.py", line 167, in train
images, targets = next(batch_iterator)
File "E:\anaconda3\lib\site-packages\torch\utils\data\dataloader.py", line 560, in __next__
batch = self.collate_fn([self.dataset[i] for i in indices])
File "E:\anaconda3\lib\site-packages\torch\utils\data\dataloader.py", line 560, in <listcomp>
batch = self.collate_fn([self.dataset[i] for i in indices])
File "E:\ssd.pytorch-master\data\voc0712.py", line 114, in __getitem__
im, gt, h, w = self.pull_item(index)
File "E:\ssd.pytorch-master\data\voc0712.py", line 133, in pull_item
img, boxes, labels = self.transform(img, target[:, :4], target[:, 4])
IndexError: too many indices for array
train.py
from data import *
from utils.augmentations import SSDAugmentation
from layers.modules import MultiBoxLoss
from ssd import build_ssd
import os
import sys
import time
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.optim as optim
import torch.backends.cudnn as cudnn
import torch.nn.init as init
import torch.utils.data as data
import numpy as np
import argparse
def str2bool(v):
return v.lower() in ("yes", "true", "t", "1")
parser = argparse.ArgumentParser(
description='Single Shot MultiBox Detector Training With Pytorch')
train_set = parser.add_mutually_exclusive_group()
parser.add_argument('--dataset', default='VOC', choices=['VOC', 'COCO'],
type=str, help='VOC or COCO')
parser.add_argument('--dataset_root', default=VOC_ROOT,
help='Dataset root directory path')
parser.add_argument('--basenet', default='vgg16_reducedfc.pth',
help='Pretrained base model')
parser.add_argument('--batch_size', default=6, type=int,
help='Batch size for training')
parser.add_argument('--resume', default=None, type=str,
help='Checkpoint state_dict file to resume training from')
parser.add_argument('--start_iter', default=0, type=int,
help='Resume training at this iter')
parser.add_argument('--num_workers', default=0, type=int,
help='Number of workers used in dataloading')
parser.add_argument('--cuda', default=True, type=str2bool,
help='Use CUDA to train model')
parser.add_argument('--lr', '--learning-rate', default=1e-3, type=float,
help='initial learning rate')
parser.add_argument('--momentum', default=0.9, type=float,
help='Momentum value for optim')
parser.add_argument('--weight_decay', default=5e-4, type=float,
help='Weight decay for SGD')
parser.add_argument('--gamma', default=0.1, type=float,
help='Gamma update for SGD')
parser.add_argument('--visdom', default=False, type=str2bool,
help='Use visdom for loss visualization')
parser.add_argument('--save_folder', default='weights/',
help='Directory for saving checkpoint models')
args = parser.parse_args()
if torch.cuda.is_available():
if args.cuda:
torch.set_default_tensor_type('torch.cuda.FloatTensor')
if not args.cuda:
print("WARNING: It looks like you have a CUDA device, but aren't " +
"using CUDA.\nRun with --cuda for optimal training speed.")
torch.set_default_tensor_type('torch.FloatTensor')
else:
torch.set_default_tensor_type('torch.FloatTensor')
if not os.path.exists(args.save_folder):
os.mkdir(args.save_folder)
def train():
if args.dataset == 'COCO':
if args.dataset_root == VOC_ROOT:
if not os.path.exists(COCO_ROOT):
parser.error('Must specify dataset_root if specifying dataset')
print("WARNING: Using default COCO dataset_root because " +
"--dataset_root was not specified.")
args.dataset_root = COCO_ROOT
cfg = coco
dataset = COCODetection(root=args.dataset_root,
transform=SSDAugmentation(cfg['min_dim'],
MEANS))
elif args.dataset == 'VOC':
if args.dataset_root == COCO_ROOT:
parser.error('Must specify dataset if specifying dataset_root')
cfg = voc
dataset = VOCDetection(root=args.dataset_root,
transform=SSDAugmentation(cfg['min_dim'],
MEANS))
if args.visdom:
import visdom
viz = visdom.Visdom()
ssd_net = build_ssd('train', cfg['min_dim'], cfg['num_classes'])
net = ssd_net
if args.cuda:
net = torch.nn.DataParallel(ssd_net)
cudnn.benchmark = True
if args.resume:
print('Resuming training, loading {}...'.format(args.resume))
ssd_net.load_weights(args.resume)
else:
vgg_weights = torch.load(args.save_folder + args.basenet)
print('Loading base network...')
ssd_net.vgg.load_state_dict(vgg_weights)
if args.cuda:
net = net.cuda()
if not args.resume:
print('Initializing weights...')
# initialize newly added layers' weights with xavier method
ssd_net.extras.apply(weights_init)
ssd_net.loc.apply(weights_init)
ssd_net.conf.apply(weights_init)
optimizer = optim.SGD(net.parameters(), lr=args.lr, momentum=args.momentum,
weight_decay=args.weight_decay)
criterion = MultiBoxLoss(cfg['num_classes'], 0.5, True, 0, True, 3, 0.5,
False, args.cuda)
net.train()
# loss counters
loc_loss = 0
conf_loss = 0
epoch = 0
print('Loading the dataset...')
epoch_size = len(dataset) // args.batch_size
print('Training SSD on:', dataset.name)
print('Using the specified args:')
print(args)
step_index = 0
if args.visdom:
vis_title = 'SSD.PyTorch on ' + dataset.name
vis_legend = ['Loc Loss', 'Conf Loss', 'Total Loss']
iter_plot = create_vis_plot('Iteration', 'Loss', vis_title, vis_legend)
epoch_plot = create_vis_plot('Epoch', 'Loss', vis_title, vis_legend)
data_loader = data.DataLoader(dataset, args.batch_size,
num_workers=args.num_workers,
shuffle=True, collate_fn=detection_collate,
pin_memory=True)
# create batch iterator
batch_iterator = iter(data_loader)
for iteration in range(args.start_iter, cfg['max_iter']):
if args.visdom and iteration != 0 and (iteration % epoch_size == 0):
update_vis_plot(epoch, loc_loss, conf_loss, epoch_plot, None,
'append', epoch_size)
# reset epoch loss counters
loc_loss = 0
conf_loss = 0
epoch += 1
if iteration in cfg['lr_steps']:
step_index += 1
adjust_learning_rate(optimizer, args.gamma, step_index)
# load train data
# images, targets = next(batch_iterator)
try:
images, targets = next(batch_iterator)
except StopIteration:
batch_iterator = iter(data_loader)
images, targets = next(batch_iterator)
if args.cuda:
images = Variable(images.cuda())
targets = [Variable(ann.cuda(), volatile=True) for ann in targets]
else:
images = Variable(images)
targets = [Variable(ann, volatile=True) for ann in targets]
# forward
t0 = time.time()
out = net(images)
# backprop
optimizer.zero_grad()
loss_l, loss_c = criterion(out, targets)
loss = loss_l + loss_c
loss.backward()
optimizer.step()
t1 = time.time()
# loc_loss += loss_l.data
# conf_loss += loss_c.data
temp1 = loss_l.item()
temp2 = loss_c.item()
loc_loss += temp1
conf_loss += temp2
if iteration % 10 == 0:
print('timer: %.4f sec.' % (t1 - t0))
# print('iter ' + repr(iteration) + ' || Loss: %.4f ||' % (loss.data), end=' ')
print('iter ' + repr(iteration) + ' || Loss: %.4f ||' % (loss.item()), end=' ')
if args.visdom:
# update_vis_plot(iteration, loss_l.data, loss_c.data,
# iter_plot, epoch_plot, 'append')
update_vis_plot(iteration, temp1, temp2,
iter_plot, epoch_plot, 'append')
if iteration != 0 and iteration % 5000 == 0:
print('Saving state, iter:', iteration)
torch.save(ssd_net.state_dict(), 'weights/ssd300_COCO_' +
repr(iteration) + '.pth')
torch.save(ssd_net.state_dict(),
args.save_folder + '' + args.dataset + '.pth')
def adjust_learning_rate(optimizer, gamma, step):
"""Sets the learning rate to the initial LR decayed by 10 at every
specified step
# Adapted from PyTorch Imagenet example:
# https://github.com/pytorch/examples/blob/master/imagenet/main.py
"""
lr = args.lr * (gamma ** (step))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
def xavier(param):
init.xavier_uniform(param)
def weights_init(m):
if isinstance(m, nn.Conv2d):
xavier(m.weight.data)
m.bias.data.zero_()
def create_vis_plot(_xlabel, _ylabel, _title, _legend):
return viz.line(
X=torch.zeros((1,)).cpu(),
Y=torch.zeros((1, 3)).cpu(),
opts=dict(
xlabel=_xlabel,
ylabel=_ylabel,
title=_title,
legend=_legend
)
)
def update_vis_plot(iteration, loc, conf, window1, window2, update_type,
epoch_size=1):
viz.line(
X=torch.ones((1, 3)).cpu() * iteration,
Y=torch.Tensor([loc, conf, loc + conf]).unsqueeze(0).cpu() / epoch_size,
win=window1,
update=update_type
)
# initialize epoch plot on first iteration
if iteration == 0:
viz.line(
X=torch.zeros((1, 3)).cpu(),
Y=torch.Tensor([loc, conf, loc + conf]).unsqueeze(0).cpu(),
win=window2,
update=True
)
if __name__ == '__main__':
train()
multibox_loss.py
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from data import coco as cfg
from ..box_utils import match, log_sum_exp
class MultiBoxLoss(nn.Module):
"""SSD Weighted Loss Function
Compute Targets:
1) Produce Confidence Target Indices by matching ground truth boxes
with (default) 'priorboxes' that have jaccard index > threshold parameter
(default threshold: 0.5).
2) Produce localization target by 'encoding' variance into offsets of ground
truth boxes and their matched 'priorboxes'.
3) Hard negative mining to filter the excessive number of negative examples
that comes with using a large number of default bounding boxes.
(default negative:positive ratio 3:1)
Objective Loss:
L(x,c,l,g) = (Lconf(x, c) + αLloc(x,l,g)) / N
Where, Lconf is the CrossEntropy Loss and Lloc is the SmoothL1 Loss
weighted by α which is set to 1 by cross val.
Args:
c: class confidences,
l: predicted boxes,
g: ground truth boxes
N: number of matched default boxes
See: https://arxiv.org/pdf/1512.02325.pdf for more details.
"""
def __init__(self, num_classes, overlap_thresh, prior_for_matching,
bkg_label, neg_mining, neg_pos, neg_overlap, encode_target,
use_gpu=True):
super(MultiBoxLoss, self).__init__()
self.use_gpu = use_gpu
self.num_classes = num_classes
self.threshold = overlap_thresh
self.background_label = bkg_label
self.encode_target = encode_target
self.use_prior_for_matching = prior_for_matching
self.do_neg_mining = neg_mining
self.negpos_ratio = neg_pos
self.neg_overlap = neg_overlap
self.variance = cfg['variance']
def forward(self, predictions, targets):
"""Multibox Loss
Args:
predictions (tuple): A tuple containing loc preds, conf preds,
and prior boxes from SSD net.
conf shape: torch.size(batch_size,num_priors,num_classes)
loc shape: torch.size(batch_size,num_priors,4)
priors shape: torch.size(num_priors,4)
targets (tensor): Ground truth boxes and labels for a batch,
shape: [batch_size,num_objs,5] (last idx is the label).
"""
loc_data, conf_data, priors = predictions
num = loc_data.size(0)
priors = priors[:loc_data.size(1), :]
num_priors = (priors.size(0))
num_classes = self.num_classes
# match priors (default boxes) and ground truth boxes
loc_t = torch.Tensor(num, num_priors, 4)
conf_t = torch.LongTensor(num, num_priors)
for idx in range(num):
truths = targets[idx][:, :-1].data
labels = targets[idx][:, -1].data
defaults = priors.data
match(self.threshold, truths, defaults, self.variance, labels,
loc_t, conf_t, idx)
if self.use_gpu:
loc_t = loc_t.cuda()
conf_t = conf_t.cuda()
# wrap targets
loc_t = Variable(loc_t, requires_grad=False)
conf_t = Variable(conf_t, requires_grad=False)
pos = conf_t > 0
num_pos = pos.sum(dim=1, keepdim=True)
# Localization Loss (Smooth L1)
# Shape: [batch,num_priors,4]
pos_idx = pos.unsqueeze(pos.dim()).expand_as(loc_data)
loc_p = loc_data[pos_idx].view(-1, 4)
loc_t = loc_t[pos_idx].view(-1, 4)
loss_l = F.smooth_l1_loss(loc_p, loc_t, size_average=False)
# Compute max conf across batch for hard negative mining
batch_conf = conf_data.view(-1, self.num_classes)
loss_c = log_sum_exp(batch_conf) - batch_conf.gather(1, conf_t.view(-1, 1))
# Hard Negative Mining
loss_c = loss_c.view(num, -1)
loss_c[pos] = 0 # filter out pos boxes for now
_, loss_idx = loss_c.sort(1, descending=True)
_, idx_rank = loss_idx.sort(1)
num_pos = pos.long().sum(1, keepdim=True)
num_neg = torch.clamp(self.negpos_ratio*num_pos, max=pos.size(1)-1)
neg = idx_rank < num_neg.expand_as(idx_rank)
# Confidence Loss Including Positive and Negative Examples
pos_idx = pos.unsqueeze(2).expand_as(conf_data)
neg_idx = neg.unsqueeze(2).expand_as(conf_data)
conf_p = conf_data[(pos_idx+neg_idx).gt(0)].view(-1, self.num_classes)
targets_weighted = conf_t[(pos+neg).gt(0)]
loss_c = F.cross_entropy(conf_p, targets_weighted, size_average=False)
# loss_c = F.cross_entropy(conf_p, targets_weighted, reduction='sum')
# Sum of losses: L(x,c,l,g) = (Lconf(x, c) + αLloc(x,l,g)) / N
# N = num_pos.data.sum()
N = num_pos.data.sum().double()
loss_l = loss_l.double()
loss_c = loss_c.double()
loss_l /= N
loss_c /= N
return loss_l, loss_c
注意:训练的时候如果还出现nan,试着调整一下batchsize,我调整过一次就再也没出现过nan,另外不要惊讶你的模型是ssd300_COCO_10000.pth,因为下面模型的名字可能没改喔

结果评价:
运行eval.py文件,可能报错:
Traceback (most recent call last):
File ".\eval.py", line 438, in <module>
thresh=args.confidence_threshold)
File ".\eval.py", line 413, in test_net
evaluate_detections(all_boxes, output_dir, dataset)
File ".\eval.py", line 418, in evaluate_detections
do_python_eval(output_dir)
File ".\eval.py", line 175, in do_python_eval
ovthresh=0.5, use_07_metric=use_07_metric)
File ".\eval.py", line 262, in voc_eval
with open(imagesetfile, 'r') as f:
FileNotFoundError: [Errno 2] No such file or directory: 'test.txt'
解决:https://github.com/amdegroot/ssd.pytorch/issues/350

训练只迭代了1万次,后面有时间再看看自己的数据如何
Saving cached annotations to ./data\VOCVOC2007\annotations_cache\annots.pkl
AP for aeroplane = 0.7152
AP for bicycle = 0.6121
AP for bird = 0.4393
AP for boat = 0.1189
AP for bottle = 0.0552
AP for bus = 0.2056
AP for car = 0.8091
AP for cat = 0.5082
AP for chair = 0.3174
AP for cow = 0.2603
AP for diningtable = 0.3664
AP for dog = 0.6777
AP for horse = 0.6479
AP for motorbike = 0.3117
AP for person = 0.5661
AP for pottedplant = 0.1818
AP for sheep = 0.3394
AP for sofa = 0.3152
AP for train = 0.7912
AP for tvmonitor = 0.2586
Mean AP = 0.4249
~~~~~~~~
Results:
0.715
0.612
0.439
0.119
0.055
0.206
0.809
0.508
0.317
0.260
0.366
0.678
0.648
0.312
0.566
0.182
0.339
0.315
0.791
0.259
0.425