机器学习项目(二) 人工智能辅助信息抽取(五)
条件随机场
概率图模型
概率图模型是指一种用图结构来描述多远随机变量之间条件独立关系的概率模型
图中的每个节点都对应一个随机变量,可以是观察变量,隐变量或是位置参数等;每个链接表示两个随机变量之间具有依赖关系。

有向图 代表两个随机变量之间存在因果关系
无向图 但是有条件依赖关系
概率图模型
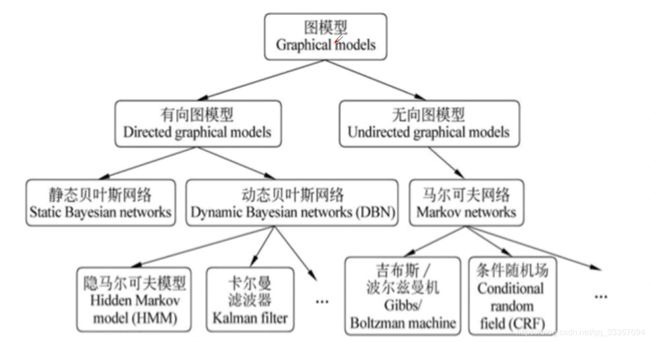
有向图VS无向图
有向图
联合概率分布可以利用条件概率来表示
P ( v 1 d , … , v n d ) = ∏ i = 1 n P ( v i d ∣ v π i d ) P\left(v_{1}^{d}, \ldots, v_{n}^{d}\right)=\prod_{i=1}^{n} P\left(v_{i}^{d} | v_{\pi i}^{d}\right) P(v1d,…,vnd)=i=1∏nP(vid∣vπid)
无向图
通过因子分解将无向图所描述的联合概率分布表示为若干个子联合概率的乘积
P ( Y ) = 1 Z ∏ C ψ C ( Y C ) P(Y)=\frac{1}{Z} \prod_{C} \psi_{C}\left(Y_{C}\right) P(Y)=Z1C∏ψC(YC)
因子分解
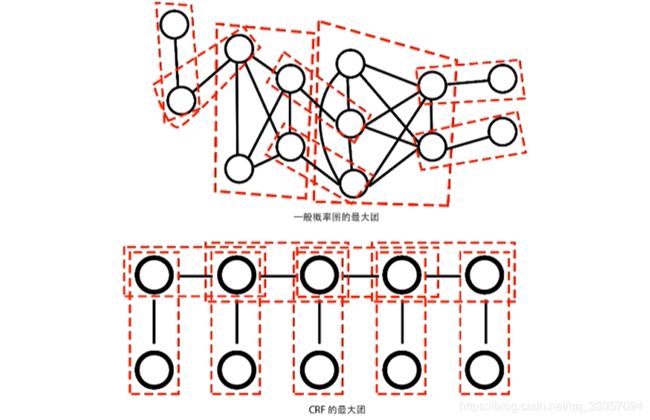
无向图G中热河两个结点均有边连接的节点子集称为团。若C是无向图G的一个团,并且不能再加进任何一个G的结点使其成为一个更大的团,则称此C为最大团
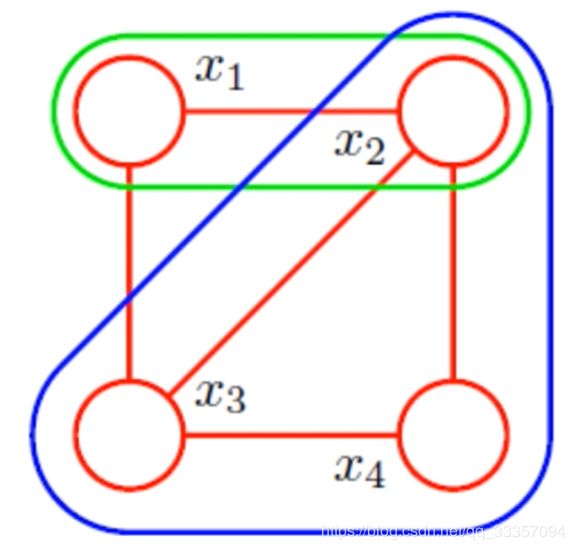
Hammersly-Clifford定理
无向图的联合概率可以分解为一系列定义在最大团上的非负函数的乘积形式。

马尔可夫随机场
如果随机变量Y构成一个由无向图G = (V,E)表示的马尔可夫随机场,对任意节点 v ∈ V v \in V v∈V都成立,即
P ( Y v ∣ X , Y w , w ≠ v ) = P ( Y v ∣ X , Y w , w ∼ v ) P\left(Y v | X, Y_{w}, w \neq v\right)=P(Y v | X, Y w, w \sim v) P(Yv∣X,Yw,w=v)=P(Yv∣X,Yw,w∼v)
则称P(Y|X)是条件随机场。式中 w ≠ v w \neq v w=v表示w是除了v以外的所有节点, w ∼ v w \sim v w∼v表示w是与v相连接的所有节点。
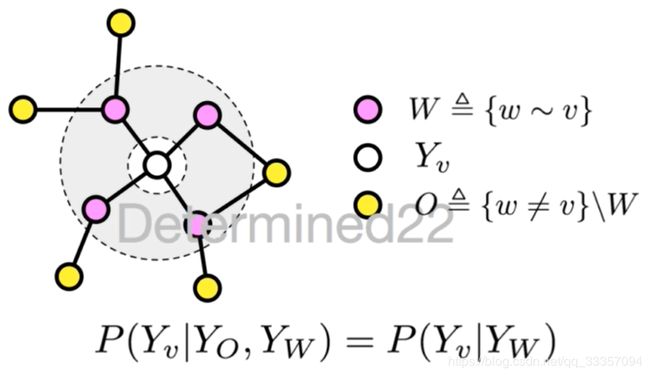
条件随机场(CRF)
CRF是条件概率分布模型P(Y|X),表示的是给定一组输入随机变量X的条件下另一组输出随机变量Y的马尔克夫随机场,也就是说CRF的特点是假设输出随机变量构成马尔克夫随机场
这里说的CRF指的是用于序列标注问题的线性链条件随机场,是由输入序列来预测输出序列的判别模型
生成VS判别
生成:对联合概率P[X,Y]建模
判别:对条件概率P[Y|X]建模
P ( Y ∣ X ) = P ( X , Y ) P ( X ) P(Y|X)=\frac{P(X, Y)}{P(X)} P(Y∣X)=P(X)P(X,Y)
线性链条件随机场
图G的每条边都存在于状态序列Y的相邻两个结点,最大团C是相邻两个结点的集合,X和Y有相同的图结构意味着每个 X i X_i Xi都与 Y i Y_i Yi一一对应。
V = 1 , 2 , . . . , N , E = ( i , i + 1 ) , i = 1 , 2 , . . . , n − 1 V = {1,2,...,N},E = {(i,i+1)},i = 1,2,...,n-1 V=1,2,...,N,E=(i,i+1),i=1,2,...,n−1
设两组随机变量 X = ( X 1 , X 2 , . . . , X n ) , Y = ( Y 1 , . . . , Y n ) X = (X_1,X_2,...,X_n),Y = (Y_1,...,Y_n) X=(X1,X2,...,Xn),Y=(Y1,...,Yn),那么线性链条件随机场的定义为
P ( Y i ∣ X , Y 1 , . . . , Y i 1 , Y i + 1 , . . . , Y n ) = P ( Y i ∣ X , Y i 1 , Y i + 1 ) , i = 1 , . . . , n P(Y_i|X,Y_1,...,Y_{i_1},Y{i+1},...,Y_n) = P(Y_i|X,Y_{i_1},Y{i+1}),i = 1,...,n P(Yi∣X,Y1,...,Yi1,Yi+1,...,Yn)=P(Yi∣X,Yi1,Yi+1),i=1,...,n
其中当i取1或n时只考虑单边。
参数化形式
给定一个线性链条件随机场P(Y|X),当观测序列为 x = x 1 , x 2 , . . . , x = x_1,x_2,..., x=x1,x2,...,时,状态序列为 y = y 1 , y 2 , . . . y = y_1,y_2,... y=y1,y2,...的概率为(实际上应该写为 P ( Y = y ∣ x ; θ ) P(Y = y|x;\theta) P(Y=y∣x;θ))
P ( Y = y ∣ x ) = 1 Z ( x ) exp ( ∑ k λ k ∑ i t k ( y i − 1 , y i , x , i ) + ∑ i μ l ∑ i s l ( y i , x , i ) ) Z ( x ) = ∑ y exp ( ∑ k λ k ∑ i t k ( y i − 1 , y i , x , i ) + ∑ l μ l ∑ i s l ( y i , x , i ) ) \begin{array}{c} P(Y=y | x)=\frac{1}{Z(x)} \exp \left(\sum_{k} \lambda_{k} \sum_{i} t_{k}\left(y_{i-1}, y_{i}, x, i\right)+\sum_{i} \mu_{l} \sum_{i} s_{l}\left(y_{i}, x, i\right)\right) \\ Z(x)=\sum_{y} \exp \left(\sum_{k} \lambda_{k} \sum_{i} t_{k}\left(y_{i-1}, y_{i}, x, i\right)+\sum_{l} \mu_{l} \sum_{i} s_{l}\left(y_{i}, x, i\right)\right) \end{array} P(Y=y∣x)=Z(x)1exp(∑kλk∑itk(yi−1,yi,x,i)+∑iμl∑isl(yi,x,i))Z(x)=∑yexp(∑kλk∑itk(yi−1,yi,x,i)+∑lμl∑isl(yi,x,i))
Z(x)作为规范化因子,是对y的所有可能取值求和。
转移特征 t k ( y i − 1 , y i , x , i ) t_k(y_{i-1},y_i,x,i) tk(yi−1,yi,x,i)是定义在边上的特征函数(transition),依赖于当前位置i和前一位置i-1,对应的权值为 λ k \lambda _k λk
状态特征 s l ( y i , x , i ) sl(y_i,x,i) sl(yi,x,i)是定义在节点上的特征函数(state)依赖于当前位置i,对应的权值为 μ l \mu l μl
特征函数的取值为1或0,当满足规定好的特征条件时取值为1,否则为0。
从特征到概率
实际上CRF就是序列版本的逻辑回归(logistic regression)。正如逻辑回归是分类问题的对数线性模型,CRF是序列标注问题的对数线性模型。
CRF VS HMM
CRF更加强大 -CRF可以为任何HMM能够建模的事物建模,甚至更多。
CRF可以定义更加广泛的特征集。
而HMM在本质上必然是局部的,而CRF就可以使用更加全局的特征。
CRF可以有任意权重值,HMM的概率值必须满足特定的约束。