One-stage目标检测里程碑算法之SSD、YOLO系列、RetinaNet等
相较于two-stage detectors ,one-stage detectors不需要提取region proposal的阶段,直接预测物体的类别概率和位置坐标值,经过单次检测即可直接得到最终的检测结果,因此有着更快的检测速度。本篇博客将逐步按照YOLO →SSD →RetinaNet →YOLOv2 →YOLOv3 →YOLOv4的顺序,依次整理one-stage目标检测算法的改进点。除此之外,one-stage的anchor-free目标检测器在不断发展,包括CornerNet、ExtremeNet、FCOS、CenterNet等,在后续博客继续进行整理。下面将对算法进行一一讨论。
One-stage里程碑算法
- YOLO
- SSD
- RetinaNet
- YOLO改进系列
- YOLOv2
- YOLOv3
- YOLOv4
YOLO
YOLO是one-stage detectors的鼻祖,也达到了真正意义上的real-time。从2016年YOLO的提出到2018年的YOLOv3,YOLO系列独树一帜、自成一派,今年YOLOv4作为一个集大成者,在原有YOLO目标检测架构的基础上增加了近年CNN改进的众多技术,虽然没有理论创新,仍然做到了速度和效果的双提升。《You Only Look Once:Unified, Real-Time Object Detection》是由Joseph Redmon等人提出并发表在CVPR 2016上的论文。创新点:(1)将目标检测重构为一个单一的回归问题,快速实时,基础网络运行速率为45帧/秒,快速版本运行速率超过150帧/秒;(2)与滑窗的方法和区域建议的方法不同,利用了图像的全局信息进行训练和测试;(3)能学习到目标的通用表达,应用到新的领域时效果不会太差。

网络结构如下所示:

- 网络结构:网络中初始的卷积层从图像中提取特征,而全连接层用来预测输出概率和坐标。受到了图像识别模型GoogLeNet的启发,设置了24个卷积层接2个全连接层,然而,不同于GoogLeNet中使用的inception modules,而是简单地在1×1卷积层后面接上3×3卷积层。在ImageNet分类任务上使用一半的分辨率(224×224的输入图像)预训练了卷积层,然后使用一倍分辨率(448×448)用来训练检测,由于检测任务通常需要细粒度的视觉信息,因此将网络的输入像素从224×224增加到448×448。
- 全连接层的预测:使用整张图片的特征去预测每一个边界框的思路是,将输入图像分成S×S的网格,如果目标的中心落在某一个网格单元,这个网格单元将负责识别出这个物体。体现在上图全连接层的输出维度,每一个网格单元预测B(=2)个边界框( x , y , w , h x,y,w,h x,y,w,h)以及对应于每一个边界框的置信分数。置信分数,反映了这个模型预测该边界框包含某一物体的可能性以及对于这个边界框回归预测的准确率, c o n f i d e n c e = P r ( O b j e c t ) ∗ I O U p r e d t r u t h confidence = Pr(Object)*IOU_{pred}^{truth} confidence=Pr(Object)∗IOUpredtruth。对于这个公式简单来说就是,如果在网格单元中没有目标,置信分数GT将为0;否则,置信分数为预测边界框和真实边界框的IOU(intersection over union),GT即为1。每一个网格单元同时也预测目标属于C(=20)个类别的条件概率, P r ( C l a s s i ∣ O b j e c t ) Pr(Class_i|Object) Pr(Classi∣Object)。因此,网络模型将图片分为一个一个的网格并且同时地预测边界框、置信分数以及类别概率,这些预测将被编码为S×S×(B*5+C)的张量。在测试的时候将类别概率和独立的边界框预测置信分数相乘,该分数编码了这个类出现在框中的概率以及预测框和目标框的匹配程度: P r ( C l a s s i ∣ O b j e c t ) ∗ P r ( O b j e c t ) ∗ I O U p r e d t r u t h = P r ( C l a s s i ) ∗ I O U p r e d t r u t h Pr(Class_i|Object)*Pr(Object)*IOU_{pred}^{truth}=Pr(Class_i)*IOU_{pred}^{truth} Pr(Classi∣Object)∗Pr(Object)∗IOUpredtruth=Pr(Classi)∗IOUpredtruth
- 损失函数:训练前对数据做归一化处理,为了更好的进行回归。利用图像的宽高归一化GT框的宽高,从而使得宽和高数值落在0~1,坐标x和y为GT框中心在特定网络单元格位置的偏移量,即相对于单元格左上角的位移量,数值也在0~1之间。详细转换过程可以参考YOLO文章详细解读,下面附上其中的图。由于平方误差和容易优化,所以作者在该损失上进行了调整。首先,为了防止不包含目标的网格在损失上压过有目标的网格,导致模型不稳定,对定位误差和分类误差构造了不同的权重,增加了bounding box的损失,减少了不含目标的confidence损失,分别引入了 λ c o o r d = 5 , λ n o o b j = 0.5 \lambda_{coord}=5,\lambda_{noobj}=0.5 λcoord=5,λnoobj=0.5。其次,平方误差和对于大回归框和小回归框有着同等权重,但是小边界框的小偏差比大边界框的小偏差影响更为重要,因此预测边界框宽和高的平方根,而不是直接预测宽和高能缓解这个问题。Multi-part loss function,是由预测数据与GT数据之间的坐标误差、置信度误差和分类误差组成的:


- 局限性:(1)每个网格单元只能预测两个边界框,并且只能有一个类,对邻近出现多个小目标时效果不佳;(2)图片进入网络之前进行了resize,卷积网络经过多次下采样,得到的特征图较为粗糙,定位不够准确;(3)通过数据集来学习预测边界框,所以很难推广到新的或者不常见的宽高比例或者不同属性的目标。
SSD
2016年由Wei Liu等人提出《SSD: Single Shot MultiBox Detector》,发表在ECCV 2016。动机:基于“proposal+classification”的two-stage目标检测方法会预先回归一次边框,精度较高但速度偏慢;YOLO只作一次边框回归预测,这种one-stage方法能达到实时效果,但是对小目标训练不够充分,对于目标的尺度比较敏感。创新点:沿用了one-stage的思想来提高检测速度,采用了不同尺度和长宽比的先验框(default bounding boxes,类似于Faster R-CNN中的Anchors)来适应不同尺度的目标,根据不同尺度的特征图生成不同尺度的预测来提高精度。算法性能对比如下:
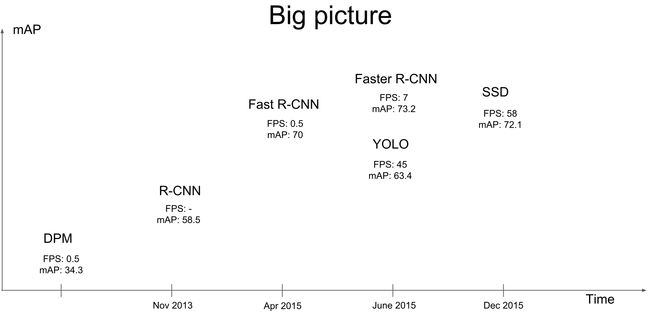
- 将多尺度特征图用于检测:将不同尺度的卷积特征层(如图所示,这些卷积层随着网络深入尺寸逐渐减小)添加到截取的backbone网络的末端,利用这些层在多个尺度上对检测结果进行预测。具体而言,大尺度特征图(较靠前的特征图)可以用来检测小物体,而小尺度特征图(较靠后的特征图)用来检测大物体。这是由于不同层次的特征图能代表不同层次的语义信息,低层次的特征图能代表低级语义信息(含有更多的细节),适合小尺度目标的学习,能提高语义分割质量;高层次的特征图能代表高级语义信息,能平滑分割结果,适合对大尺度的目标进行深入学习。网络结构如下,虚线框为VGG-16的前5层,将VGG-16的后两层全连接网络(fc6、fc7)转化为conv6和conv7,继续增加了conv8到conv11这4层网络。

- 采用卷积进行检测:与YOLO最后采用全连接层不同,SSD直接采用卷积对不同的特征图来进行提取检测结果,它认为目标检测中的物体只与周围信息相关,感受野不是全局的,从而没必要也不应该做全连接。对于形状为 m × n × p m×n×p m×n×p 的特征图,只需要采用 3 × 3 × p 3×3×p 3×3×p 这样比较小的卷积核得到每个位置的检测值(类别分数和相对于先验框的偏移)。
- 设置先验框和长宽比:YOLO需要在训练过程中自适应目标的形状,而SSD借鉴了Faster R-CNN中anchor的思想,为特征图的每个单元设置尺度(scale)或者长宽比(ratio)不同的先验框,预测的边界框(bounding boxes)是以这些先验框为基准的,在一定程度上减少了训练难度。对于每个单元的每个先验框,其都输出一组独立的检测值,包括C个类别置信度和边界框的坐标,这C个类别中除了目标类别数还加了一个背景类,4个坐标值 ( c x , c y , w , h ) (cx,cy,w,h) (cx,cy,w,h) 分别表示边界框的中心坐标以及宽高相对于先验框的变化量。对于不同尺度的feature maps上使用不同的default boxes,如上图所示,共提取了6个卷积层包括38×38×512、19×19×1024、10×10×512、5×5×256、3×3×256、1×1×256,根据特征图的单元数量及每个单元对应的default boxes的个数 k k k(分别为4,6,6,6,4,4),最后总共得到8732个检测框,映射回原图也很密集了。
生成方式:以feature map上每个单元的中点为中心(offset=0.5),生成一系列default boxes,中心点的坐标会乘以step,相当于从feature map位置映射回原图位置,step就是原图与特征图大小的比值。m个不同尺度特征图的default boxes的比例按照 S l = S m i n + S m a x − S m i n m − 1 ( l − 1 ) , l ∈ [ 1 , m ] S_l = S_{min}+\frac{S_{max}-S_{min}}{m-1}(l-1),l\in[1,m] Sl=Smin+m−1Smax−Smin(l−1),l∈[1,m] 计算,论文中设置 S m i n = 0.2 , S m a x = 0.9 S_{min}=0.2,S_{max}=0.9 Smin=0.2,Smax=0.9,其间所有层是等间隔的。各个特征图的先验框尺度为30,60,111,162,213,264,具体计算参考目标检测|SSD原理与实现。根据比例可得, l l l 层特征图上default boxes宽高分别为 w l a = S l a r , h l a = S l / a r w_l^a=S_l\sqrt{a_r},h_l^a=S_l/\sqrt{a_r} wla=Slar,hla=Sl/ar。 k = 4 k=4 k=4时,长宽比 a r a_r ar为 { 1 , 2 , 1 2 } \{1,2,\frac12\} {1,2,21}; k = 6 k=6 k=6时,长宽比为 { 1 , 2 , 3 , 1 2 , 1 3 } \{1,2,3,\frac12,\frac13\} {1,2,3,21,31},对于长宽比为1的还添加了一个缩放比例为 S l S l + 1 \sqrt{S_lS_{l+1}} SlSl+1 的default box。 k = 4 k=4 k=4在特征图的先验框,如下图所示:

- 损失函数:SSD匹配ground truth boxes和default boxes的策略与Faster RCNN类似,即先找到IOU最大,再将某阈值(如0.5)之上设为正。一个ground truth box可以与多个default boxes匹配,反之不成立,尽管如此,负样本相对正样本仍然会很多。为了保证正负样本尽量平衡,SSD采用了hard negative mining,就是对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差的较大的top-k作为训练的负样本,以保证正负样本比例接近1:3。损失函数定义为位置误差(locatization loss,loc)与置信度误差(confidence loss,conf)的加权和:
L ( x , c , l , g ) = 1 N ( L c o n f ( x , c ) + α L l o c ( x , l , g ) ) L(x,c,l,g)=\frac1N(L_{conf}(x,c)+\alpha L_{loc}(x,l,g)) L(x,c,l,g)=N1(Lconf(x,c)+αLloc(x,l,g))
其中, N N N是先验框的正样本数量。这里 x i j p ∈ { 1 , 0 } x_{ij}^p\in\{1,0\} xijp∈{1,0} 为一个指示参数,当 x i j p = 1 x_{ij}^p=1 xijp=1 时表示第 i i i 个先验框与第 j j j 个ground truth匹配,并且ground truth的类别为 p p p 。 c c c 为类别置信度预测值。 l l l 为先验框的所对应边界框的位置预测值,而 g g g 是ground truth的位置参数。对于位置误差,采用Smooth L1 loss,对于置信度误差,采用softmax 交叉熵 loss。
RetinaNet
2017年由Ross Girshick和Kaiming He所在的Facebook AI Research (FAIR)又又提出了《Focal Loss for Dense Object Detection》,发表在ICCV 2017。动机:two-stage方法的分类器应用于稀疏的候选对象位置集,而密集采样上应用的one-stage探测器更快和更简单,但是精度却落后于two-stage检测器。创新点:论文指出密集探测器训练过程中遇到的极端前景背景类别不平衡是造成精度逊色的根本原因,因此设计了新的focal loss来代替无法抗衡该问题的交叉熵损失。
- focal loss:在二元分类交叉熵的基础上,引入了加权因子 α ∈ [ 0 , 1 ] \alpha\in[0,1] α∈[0,1](对于正样本,负样本为 ( 1 − α ) (1-\alpha) (1−α)),虽然 α \alpha α 具有平衡正负样本的重要性,但是它没有区分简单/困难样本,这会导致容易分类的负样本作为损失的主要部分。在此基础上,添加一个具有可调聚焦参数 γ ≥ 0 \gamma\geq0 γ≥0的调制因子 ( 1 − p t ) γ (1-p_t)^\gamma (1−pt)γ,无论是前景类还是背景类, p t p_t pt 越大,权重 ( 1 − p t ) (1-p_t) (1−pt) 就越小,也就是说easy example可以通过权重进行抑制。所以,当某样本类别比较明确时,它对整体loss的贡献就比较少;而若某样本类别不易区分,则对整体loss的贡献就相对偏大。这样得到的loss最终将集中精力去诱导模型去努力分辨那些难分的目标类别,于是就有效提升了整体的目标检测精度。论文指出 γ = 2 \gamma=2 γ=2 , α = 0.25 \alpha=0.25 α=0.25 时,ResNet-101+FPN作为backbone的结构有最优的性能。
F L ( p t ) = − α t ( 1 − p t ) γ l o g ( p t ) FL(p_t)=-\alpha_t(1-p_t)^\gamma log(p_t) FL(pt)=−αt(1−pt)γlog(pt) - RetinaNet Detector:RetinaNet是一个统一的网络,由骨干网和两个特定于任务的子网组成。骨干负责计算整个输入图像上的卷积特征图,使用ResNet+FPN作为backbone;第一个子网在主干的输出上执行目标分类,第二个子网执行目标边界框回归,整个结构不同层的head部分(图中的c和d部分)共享参数,但分类和回归分支间的参数不共享。训练时FPN每一层的所有样本都被用于计算Focal Loss,loss值加到一起用来训练;测试时FPN每一层只选取score最大的1000个样本来做NMS。

YOLO改进系列
YOLOv2
2017 CVPR上发表了《YOLO9000: Better, Faster, Stronger》,从论文题目可以看出,在YOLO的基础上新提出的改进可以使得性能更好、速度更快、功能更强。动机:与分类等其他任务的数据集相比,目标检测数据集是有限的,因此检测的范围较小。YOLO与Fast R-CNN相比的误差分析表明,YOLO造成了大量的定位误差。此外,与基于区域建议的方法相比,YOLO召回率相对较低。创新点:(1)对原有的检测框架进行了改进,在保持原有速度的优势下提升了精度;(2)提出了一种目标分类和检测联合的训练方法,可同时在COCO和ImageNet数据集训练,训练后的模型可实现多达9000种物体的实时检测。
- Better:改善召回率和定位,同时保持分类准确性。
(1)在每一层卷积后添加batch normalization,改善了收敛速度的同时也减少了对其他方法的依赖,获得了超过2%的改进。
(2)预训练分类模型采用了更高分辨率的图片。YOLO先在ImageNet(224×224)分类数据集预训练主体网络,再将训练检测模型的输入直接变为448×448可能难以适应,所以增加了448×448输入的fine-tuning分类网络10个epoch,提升mAP约4%。
(3)借鉴Faster RCNN引入了anchor的机制,448的输入尺寸改为416,经过32的strides得到13×13的特征图,奇数维的作用是可以用中心点去预测占据图像中心的大目标。YOLO每张图像只预测98个边界框,但是使用anchor可以预测超过一千的框。与不同锚框的方法相比,尽管mAP得到一个较小的下降,但召回率上升。
(4)维度聚类。由于anchor尺寸是手工挑选的,网络通过学习适当调整边界框,但如果能为网络选择更好的先验,可以使网络更容易学习好的检测。在训练集边界框上运行k-means聚类,自动找到好的先验,结果显示对手工设计的anchor boxes找5个聚类中心时,性能与直接设置9个anchor boxes相似,提升mAP约5%。如下图1所示,左图显示了我们通过对聚类中心 k k k 的各种选择得到的平均 IOU,发现 k = 5 k = 5 k=5 给出了一个很好的召回率与模型复杂度的权衡。右图显示了VOC和COCO的相对中心,这两种先验都倾向于更瘦更高的边界框,而COCO比VOC在尺寸上有更大的变化。

(5)直接位置预测。在region proposal中,中心点坐标是根据预测的偏移量计算得到,由于偏移量不受约束,预测的边界框可以落在图片任何位置,导致模型不稳定(特别是早期迭代)。所以沿用了YOLO的方法,预测边界框中心相对于对应cell左上角位置的相对偏移,每个cell有5个值 t x t_x tx, t y t_y ty, t w t_w tw, t h t_h th 和 t o t_o to。为了将bounding box中心点约束在cell中,使用sigmoid将其归一化0-1之间。具体公式所代表的含义,如上图2所示:
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t h P r ( object ) ∗ I O U ( b , object ) = σ ( t o ) b_x = \sigma(t_x) + c_x \\ b_y = \sigma(t_y) + c_y\\ b_w = p_w e^{t_w}\\ b_h = p_h e^{t_h}\\ Pr(\text{object}) * IOU(b, \text{object}) = \sigma(t_o) bx=σ(tx)+cxby=σ(ty)+cybw=pwetwbh=phethPr(object)∗IOU(b,object)=σ(to)
(6)细粒度功能。为了定位小目标,作者仅添加了一个直通(passthrough)层,即从26×26的更早层中提取特征,将26×26×512 映射到13×13×256的特征图。具体来说就是特征重排(不涉及到参数学习),前面26×26×512的特征图先卷积到64维,然后使用按行和按列隔行采样的方法,就可以得到4个新的特征图,维度都是13×13×64,然后做concat操作,得到13×13×256的特征图。再将其拼接到后面13×13×1024的层,相当于做了一次特征融合,有利于检测小目标,模型的性能获得了1%的提升。
(7)多尺度训练。在检测数据集上fine-tuning使用,每隔10个批次(batches)网络会随机选择一个新的图像尺寸大小。由于网络经过5次max pooling,下采样了32倍,因此从32的倍数中选择 { 320 , 352 , . . . , 608 } \{320,352,...,608\} {320,352,...,608}。输出的特征图最小10×10,最大19×19,这样使模型能够鲁棒的运行在不同大小的图像上。 - Faster:设计了Darknet-19的网络结构,如下图所示。

- Stronger:通过ImageNet训练分类,COCO和VOC数据集来训练检测,通过将两个数据集混合训练,如果遇到来自分类集的图片则只计算分类的Loss,遇到来自检测集的图片则计算完整的Loss。ImageNet对应分类可以有9000种,而COCO则只提供80种目标检测,通过multi-label模型进行匹配。
YOLOv3
2018年Joseph Redmon和Ali Farhadi在继YOLOv2之后,又在arXiv上发表了《YOLOv3: An Incremental Improvement》。动机:设计一个快速而高效的目标检测器。YOLOv3主要是基于v1、v2进行了改进,延续了v2的anchor策略,没有太大的创新,但是在保持速度优势的前提下,提升了预测精度,尤其是加强了对小物体的识别能力。有以下三个主要的改进:
- 调整了网络结构,提出了Darknet-53,如下图所示。矩形框内为一个残差块,分别重复堆叠,每个残差块内有两层卷积和一个快捷连接(shortcut connection)。

- 利用多尺度特征进行检测。类似于FPN的设计,为了实现细粒度的检测,使用3个scale(13×13,26×26,52×52)的feature map进行预测。在coco数据集上聚类的9个anchors大小分别为:(10×13),(16×30),(33×23),(30× 61),(62×45),(59×119),(116×90),(156×198),(373×326)。由于有3个分支输出做预测,每个特征图使用3个anchors。
| 特征图 | 先验框 | 感受野 |
|---|---|---|
| 13×13 | (116×90),(156×198),(373×326) | 大 |
| 26×26 | (30× 61),(62×45),(59×119) | 中 |
| 52×52 | (10×13),(16×30),(33×23) | 小 |
- 分类用logistic(sigmoid)取代了softmax,为了能够支持多标签对象。如果用的是softmax,它会强加一个假设,使得每个框只包含一个类别,所以对每一类用单独的逻辑分类器。
YOLOv4
两个月前,由俄罗斯开发者Alexey Bochkovskiy和两位中国台湾开发者Chien-Yao Wang和Hong-Yuan Mark Liao联合推出《YOLOv4: Optimal Speed and Accuracy of Object Detection》。文中实验结果可以看出,在准确率相较于YOLOv3上升10个百分点的同时,速度没有明显下降,如下图所示。动机:提升生产系统中目标检测器的速度以及优化并行运算,而不是BFLOP。为了设计一个够更容易训练和使用的检测器,使得任何人使用传统的GPU便能够进行实时的训练和测试,并能够获得高质量的实时检测结果。创新点:将卷积神经网络中大量的可以提高性能的特性进行组合并且测试,利用WRC、CSP、CmBN、SAT、 Mish activation、Mosaic data augmentation、CmBN、DropBlock regularization、 CIoU loss实现了一个速度更快、精度更好的检测模型,可谓是集大成者。

- 一般的目标检测器由以下几部分组成,如图所示,展现了two-stage和one-stage的区别:
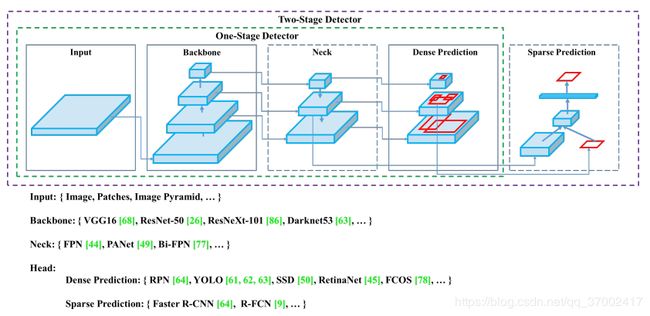
| 检测各模块 | 目前的方法 |
|---|---|
| Input | Image, Patches, Image Pyramid |
| Backbones | VGG16, ResNet-50, SpineNet, EfficientNet-B0/B7, CSPResNeXt50, CSPDarknet53 |
| Neck | • Additional blocks: SPP, ASPP, RFB, SAM • Path-aggregation blocks: FPN, PAN, NAS-FPN, Fully-connected FPN, BiFPN, ASFF, SFAM |
| Heads | • Dense Prediction (one-stage): ◦ RPN, SSD, YOLO, RetinaNet (anchor based) ◦ CornerNet, CenterNet, MatrixNet, FCOS (anchor free) • Sparse Prediction (two-stage): ◦ Faster R-CNN, R-FCN, Mask RCNN (anchor based) ◦ RepPoints (anchor free) |
作者将那些增加模型性能,只在训练阶段耗时增多,但不影响推理时间的技巧称为——赠品(bag of freebies),也就是白给的提升精度方法。而那些略微提高推理耗时,却有显著性能提升的方法称为——特价(bag of specials),也就是不免费但是很实惠的技巧。
- bag of freebies:
(1)数据增强:增加输入图像的可变性,从而使设计的目标检测模型对不同环境的图片具有较高的鲁棒性。比如photometric distortions和geometric distortions是两种常用的数据增强方法。
photometric distortions:亮度、对比度、色调、饱和度和加噪声。
geometric distortions:随机缩放、裁剪、翻转和旋转。
模拟object occlusion:random erase和CutOut(随机的选取图像中的矩形区域,并随机填入或补零),hide-and-seek和grid mask(随机或均匀地选择图像中的多个矩形区域,并将其替换为全0)。类似的概念应用到特征图中,就是DropOut、DropConnect和DropBlock方法。
多张图像做数据扩增:MixUp使用了两个图像乘以不同系数的乘法叠加,并调整标签。CutMix覆盖裁剪后的图像到其他图像的矩形区域,并根据混合区的大小调整标签。
style transfer GAN:可以有效地实现数据扩容,减少CNN学习的纹理偏差。
(2)解决数据集中的语义分布偏差:
label imbalance:hard negative example mining或online hard example mining,focal loss。
one-hot编码很难表达出类与类之间关联程度:labe smoothing将硬标签转化为软标签进行训练,可以使模型更鲁棒。
(3)objective function of Bounding Box (BBox) 回归:IoU损失→GIoU损失→DIoU损失→CIoU损失。- bag of specials:
(1)扩大感受野:SPP、ASPP和RFB。
(2)引入注意力机制:通常分为channel-wise注意力和point-wise注意力,代表模型分别是Squeeze-and-Excitation (SE) 和 Spatial Attention Module (SAM)。
(3)增强特征整合能力:早期的做法是用skip connection或hyper-column来融合低级和高级特征,目前轻量级模块集成了不同的特征金字塔,如SFAM、ASFF和BiFPN。
(4)激活函数:ReLU, LReLU, PReLU, ReLU6, Scaled Exponential Linear Unit(SELU), Swish, hard-Swish 和 Mish 等。
(5)后处理:贪婪NMS,soft NMS,DIoU NMS等。
提出了两种具有实时性的神经网络方案:
• 对于GPU,在卷积层中使用少量的组(1~8):CSPResNeXt50 / CSPDarknet53 。
• 对于VPU,使用分组卷积,但不使用Squeeze-and-excitement (SE) blocks,具体包括以下模型:EffificientNet-lite / MixNet / GhostNet / MobileNetV3。
- 架构选择:CSPResNext50仅包含16个3×3卷积层、425×425感受野大小和20.6M个参数,CSPDarknet53包含29个3×3卷积、725×725感受野大小和27.6M个参数。CSPDarkNet53有更大的感受野(提高模型的感受野,能应对网络输入尺寸增加)和参数量(更大的模型容量,在单个图像中检测多个大小不同的目标),更适合作为检测模型的Backbone。在CSPDarkNet53基础上,作者添加了SPP模块,因其可以提升模型的感受野、分离更重要的上下文信息、不会导致模型推理速度的下降;与此同时,作者还采用PANet中的不同backbone级的参数汇聚方法替代YOLOv3中使用的FPN。最终模型框架为: YOLOv4=CSPDarkNet53+SPP+PANet(path-aggregation neck)+YOLOv3-head。如下图左侧为SPP,右侧是PANet的neck结构。
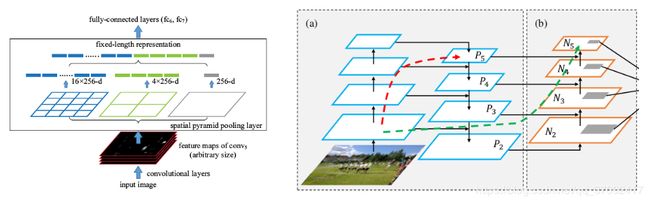
- BoF 和BoS选择:激活函数选择Mish;正则化方面选择DropBlock;由于聚焦在单GPU,故而归一化方法的选择未考虑SyncBN。
常用tricks:
• 激活函数: ReLU, leaky-ReLU, parametric-ReLU,ReLU6, SELU, Swish, or Mish
• 边框回归损失: MSE, IoU, GIoU, CIoU, DIoU
• 数据增强: CutOut, MixUp, CutMix
• 正则化方法: DropOut, DropPath, Spatial DropOut, or DropBlock
• 根据均值和方差归一化: Batch Normalization (BN) , Cross-GPU Batch Normalization (CGBN or SyncBN), Filter Response Normalization (FRN) , or Cross-Iteration Batch Normalization (CBN)
• 跳跃连接: Residual connections, Weighted residual connections, Multi-input weighted residual connections, or Cross stage partial connections (CSP)
- 额外提升:
(1)新的数据增强方法Mosaic和Self-Adversarial Training (SAT);
(2)应用遗传算法选择最优的超参数;
(3)修改一些现有的方法,使其适用于有效的训练和检测:modified SAM、modified PAN、Cross mini-Batch Normalization (CmBN)。

- 整体结构:
总而言之,YOLOv4包含以下信息:
Backbone:CSPDarkNet53
Neck:SPP,PAN
Head:YOLOv3
Bag of Freebies (BoF) for backbone:CutMix、Mosaic、DropBlock、Label Smoothing
Bag of Specials (BoS) for backbone: Mish、CSP、MiWRC
Bag of Freebies (BoF) for detector :CIoU、CMBN、DropBlock、Mosaic、SAT、Eliminate grid sensitivity、Multiple Anchor、Cosine Annealing scheduler、Random training shape
Bag of Specials (BoS) for detector :Mish、SPP、SAM、PAN、DIoU-NMS
下面是整体YOLOv4框架的思维导图,图片来源一张图梳理YOLOv4论文:

其实不久前才发现竟然新出了YOLOv4,正准备了解的时候竟然又出炉了"YOLOv5"。"YOLOv5"的项目团队是Ultralytics LLC 公司,基于pytorch,运行的推理速度极快,项目地址为https://github.com/ultralytics/yolov5。
参考链接:
[1] 目标检测之YOLOv4
[2] YOLOv4重磅发布,五大改进,二十多项技巧实验,堪称最强目标检测万花筒