学习Spark程序开发,目前大多数是采用的Python语言学习,这里介绍了pyspark的交互式使用,配置pyspark环境变量以及介绍pyspark基本使用方法。
1.安装Python3环境(Centos 7)
首先是安装Python3.6 环境教程,采用以下方式安装比较简单,需要在Master节点和Slaves节点上都安装Python3.6的开发环境。
we will install yum-utils, a collection of utilities and plugins that extend and supplement yum:
sudo yum -y install yum-utils
Finally, we’ll install the CentOS Development Tools, which are used to allow you to build and compile software from source code:
sudo yum -y groupinstall development
To install IUS, let’s install it through yum:
sudo yum -y install https://centos7.iuscommunity.org/ius-release.rpm
Once IUS is finished installing, we can install the most recent version of Python:
sudo yum -y install python36u
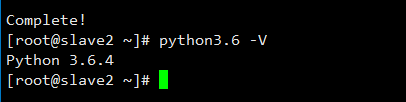
When the installation process of Python is complete, we can check to make sure that the installation was successful by checking for its version number with the python3.6 command:
python3.6 -V
We will next install pip, which will manage software packages for Python:
sudo yum -y install python36u-pip
Finally, we will need to install the IUS package python36u-devel, which provides us with libraries and header files we will need for Python 3 development:
sudo yum -y install python36u-devel
Now that we have Python installed and our system set up, we can go on to create our programming environment with venv.
Note: Within the virtual environment, you can use the command python instead of python3.6, and pip instead of pip3.6 if you would prefer. If you use Python 3 on your machine outside of an environment, you will need to use the python3.6 and pip3.6 commands exclusively.
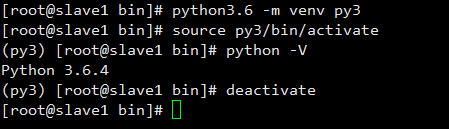
当我们安装完Python3.6后,可以直接执行下面的命令进行虚拟机环境的创建:
[root@slave1 local]# python3.6 -m venv py3
[root@slave1 local]# source py3/bin/activate #进入Python3环境
(py3) [root@slave1 local]# python -V
Python 3.6.4
(py3) [root@slave1 local]# deactivate #deactivate离开Python3环境
[root@slave1 bin]#
重点在此(不推荐此种做法):
一般的做法按照下面的方法,但是我不推荐中方法,因为会污染系统自带的Python环境,导致yum无法使用、防火墙无法开启等种种问题。推荐做法就是使用virtualenv 创建独立的虚拟环境,以上就是采用此方法`
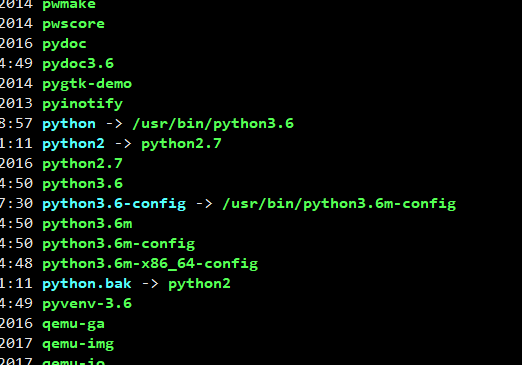
Centos 7 会自带Python 2.7(默认) ,yum安装之后,新安装的Python在/usr/bin/ 目录下,如果我们输入Python -V ,会出现在 Python 2.7 ,现在我们需要建立一个软连接将Python3.6指向Python,先执行mv python python.bak命令备份python文件,在/usr/bin 目录下执行:
mv python python.bak
查看已经安装的Python版本
ls python*
然后建立软连接
ln -s /usr/bin/python3.6 /usr/bin/python

如果不使用上面的做法就需要删除软连接,现在删除python -> /usr/bin/python3.6 软连接,将Python的环境恢复到Python2.7。
执行下面命令:
rm -rf /usr/bin/python
重新建立软连接(恢复原来的Python环境)
ln -s /usr/bin/python2.7 /usr/bin/python
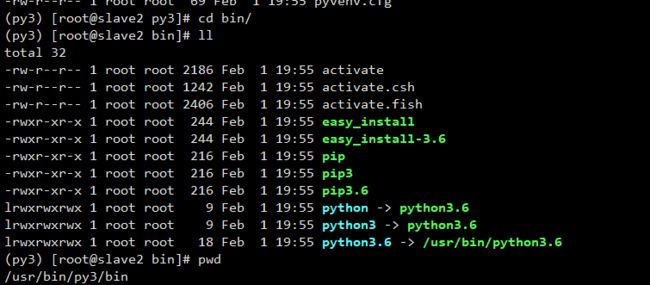
配置环境变量,将创建的虚拟环境的Python路径添加到环境变量中即可。
vim /etc/profile
//向该文件中添加下面的环境变量
export PYSPARK_PYTHON=/usr/bin/py3/bin/python
source /etc/profile
2.配置spark-env.sh文件
添加Python的环境变量
export PYSPARK_PYTHON=/usr/bin/py3/bin/python
3.启动以及测试实例
./pyspark
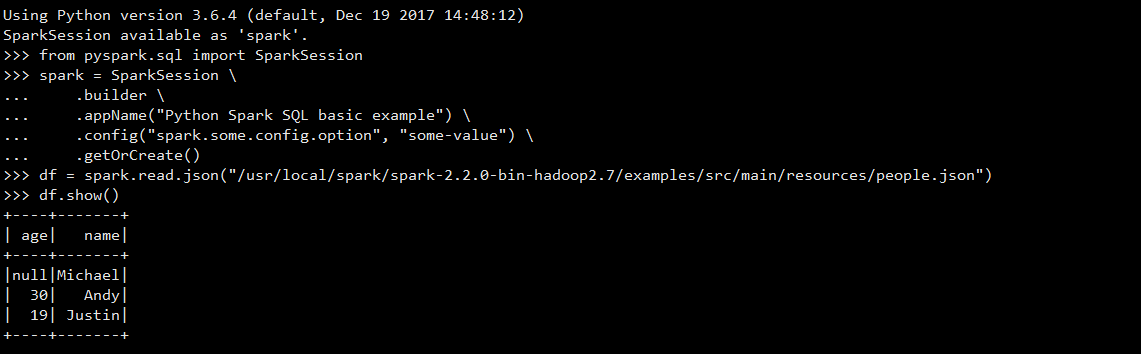
导入SparkSession包
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
读取官方给出的例子
df = spark.read.json("/usr/local/spark/spark-2.2.0-bin-hadoop2.7/examples/src/main/resources/people.json")
df.show()
使用
exit()退出pyspark,这样退出不会出错。
4.pyspark操作hive
4.1使用HiveContext操作hive中的数据库和表
from pyspark.sql import HiveContext
sqlContext = HiveContext(sc)
sqlContext.sql('show databases').show()

4.2使用SparkSession操作hive中的数据库和表
>>> from pyspark.sql import SparkSession
>>> spark = SparkSession \
.builder \
.appName("Python Spark SQL basic example") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
spark.sql("show databases").show()

spark.sql("show tables").show()
spark.sql("select * from student").show()

查看spark的job页面,4040页面只有在有spark 任务运行时才能访问,提交job后Spark-UI才会启动。当任务运行完了,立马端口就释放了(访问地址为master:4040)

5.参考资料
http://dblab.xmu.edu.cn/blog/1692-2/