【windows10】使用pytorch版本deeplabv3+训练自己数据集
目录
- 序言
- 开发环境
- 一、准备数据集
- 二、修改配置
- 三、开始训练
- 四、模型测试
序言
最近工作需要用到语义分割,跑了一个deeplabv3+的模型,deeplabv3+是一个非常不错的语义分割模型,使用也比较广泛,目前在网上的教程中大多都是基于tersorflow的deeplabv3+,而博主用的是pytorch,在网上搜索的时候几乎没有教程,所以在跑完后打算写个博文来记录一下。
开发环境
- windows10
- pytorch1.2
- pychram
- python3.7
- GTX 2070
我使用的代码是这个deeplab-pytorch,首先将代码下载到本地并解压,安装所需要的依赖,缺什么装什么就好了。
一、准备数据集
语义分割数据集的制作使用的是labelme,这个不用过多介绍,最后将所有的json文件转换为mask和图片格式,这里使用的是VOC格式,文件夹目录如下:

- ImageSets文件夹内还有一个文件夹Segmentation,里面存放的是训练集、验证集、测试集的信息
- JPEGImages存放原图image
- SegmentationClass存放原图对应的mask
至此数据集准备完成,怎么添加数据集我们接下来会详细说,记住自己数据集的路径就OK,比如我这里的路径是:
H:\VOCdevkit\invoice
二、修改配置
要训练自己数据集,要修改以下几个配置,包括将自己数据集添加进去:
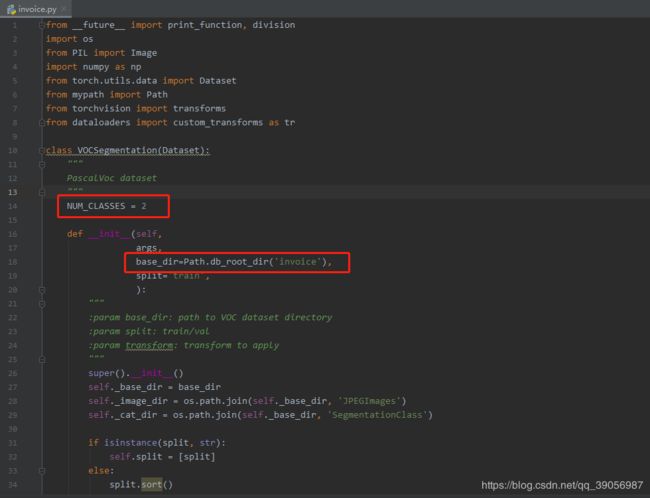
- 在mypath.py文件中,定义自己的数据集,把刚才的路径添加进去,我的数据集名字叫做invoice,如下:

- 然后在dataloaders/datasets路径下创建自己的数据集文件,这里创建为invoice.py,因为我们是按照VOC数据集格式,所以直接将pascal.py内容复制过来修改,这里将类别数和数据集改成自己的数据集,类别记得加上背景类,我这里一共是2类:
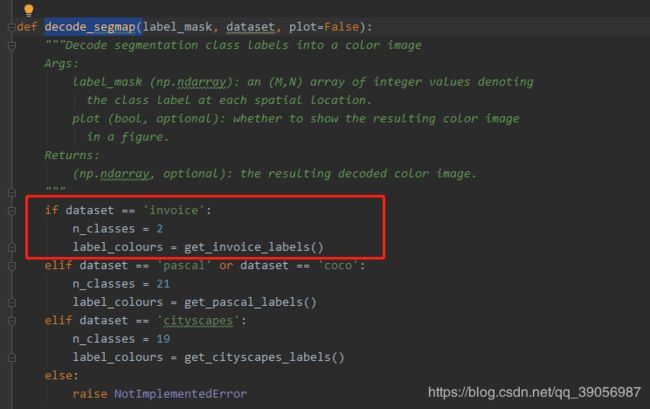
- 修改dataloaders/utils.py,在文件中创建一个get_invoice_labels()函数,根据自己的类别数,我这里只有两类,一类是背景,一类是我要分割的类,所以只定义了两种mask颜色:

[0 ,0 ,0]是黑色背景,[128, 0, 0]是我mask颜色。

在这里插入图片描述然后在decode_segmap()中添加:
三、开始训练
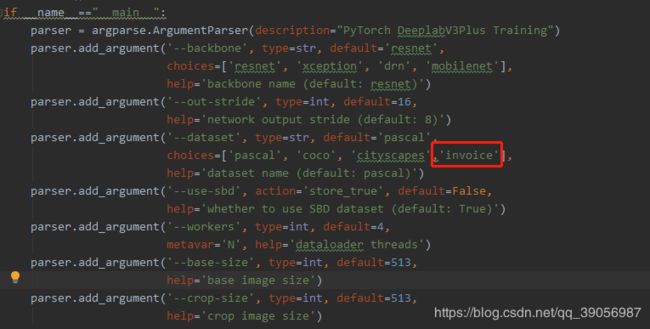
在这个程序中,作者提供了四种的backbone,分别是:resnet、xception、drn、mobilenet,并且提供了预训练权重,在训练开始时会自动下载,可以根据自己电脑的配置进行选择,如果配置稍微差一点的话建议使用mobilenet作为backbone,在训练开始之前,打开train文件,在这里把自己的类别添加上去:
一切准备就绪 ,打开Pychram自带的Terminal,输入以下命令,train起来:
python train.py --backbone mobilenet --lr 0.007 --workers 1 --epochs 50 --batch-size 8 --gpu-ids 0 --checkname deeplab-mobilenet
这里介绍几个参数:
- –backbone mobilenet 指的是使用mobilenet作为backbone
- –gpu-ids 0 指定gpu
- –checkname deeplab-mobilenet 使用mobilenet预训练模型
如果是多GPU的话可以指定GPU信息,具体可以参考程序里面的train_sh文件,我这里只用了一块GPU,看到如下界面后模型就开始训练了,因为我的预训练权重已经下载过了,所以忽略了那个下载界面,问题不大,下载的时候慢慢等待就好了。
每个轮次训练完后都会对验证集进行评估,会按照mIOU最优结果进行模型的保存,最后的模型的训练结果会保存在run文件夹中:

四、模型测试
原程序中是不提供demo文件的,这里新建一个demo.py文件:
#
# demo.py
#
import argparse
import os
import numpy as np
import time
from modeling.deeplab import *
from dataloaders import custom_transforms as tr
from PIL import Image
from torchvision import transforms
from dataloaders.utils import *
from torchvision.utils import make_grid, save_image
def main():
parser = argparse.ArgumentParser(description="PyTorch DeeplabV3Plus Training")
parser.add_argument('--in-path', type=str, required=True, help='image to test')
# parser.add_argument('--out-path', type=str, required=True, help='mask image to save')
parser.add_argument('--backbone', type=str, default='resnet',
choices=['resnet', 'xception', 'drn', 'mobilenet'],
help='backbone name (default: resnet)')
parser.add_argument('--ckpt', type=str, default='deeplab-resnet.pth',
help='saved model')
parser.add_argument('--out-stride', type=int, default=16,
help='network output stride (default: 8)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--gpu-ids', type=str, default='0',
help='use which gpu to train, must be a \
comma-separated list of integers only (default=0)')
parser.add_argument('--dataset', type=str, default='pascal',
choices=['pascal', 'coco', 'cityscapes','invoice'],
help='dataset name (default: pascal)')
parser.add_argument('--crop-size', type=int, default=513,
help='crop image size')
parser.add_argument('--num_classes', type=int, default=2,
help='crop image size')
parser.add_argument('--sync-bn', type=bool, default=None,
help='whether to use sync bn (default: auto)')
parser.add_argument('--freeze-bn', type=bool, default=False,
help='whether to freeze bn parameters (default: False)')
args = parser.parse_args()
args.cuda = not args.no_cuda and torch.cuda.is_available()
if args.cuda:
try:
args.gpu_ids = [int(s) for s in args.gpu_ids.split(',')]
except ValueError:
raise ValueError('Argument --gpu_ids must be a comma-separated list of integers only')
if args.sync_bn is None:
if args.cuda and len(args.gpu_ids) > 1:
args.sync_bn = True
else:
args.sync_bn = False
model_s_time = time.time()
model = DeepLab(num_classes=args.num_classes,
backbone=args.backbone,
output_stride=args.out_stride,
sync_bn=args.sync_bn,
freeze_bn=args.freeze_bn)
ckpt = torch.load(args.ckpt, map_location='cpu')
model.load_state_dict(ckpt['state_dict'])
model = model.cuda()
model_u_time = time.time()
model_load_time = model_u_time-model_s_time
print("model load time is {}".format(model_load_time))
composed_transforms = transforms.Compose([
tr.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
tr.ToTensor()])
for name in os.listdir(args.in_path):
s_time = time.time()
image = Image.open(args.in_path+"/"+name).convert('RGB')
# image = Image.open(args.in_path).convert('RGB')
target = Image.open(args.in_path+"/"+name).convert('L')
sample = {'image': image, 'label': target}
tensor_in = composed_transforms(sample)['image'].unsqueeze(0)
model.eval()
if args.cuda:
tensor_in = tensor_in.cuda()
with torch.no_grad():
output = model(tensor_in)
grid_image = make_grid(decode_seg_map_sequence(torch.max(output[:3], 1)[1].detach().cpu().numpy()),
3, normalize=False, range=(0, 255))
save_image(grid_image,args.in_path+"/"+"{}_mask.png".format(name[0:-4]))
u_time = time.time()
img_time = u_time-s_time
print("image:{} time: {} ".format(name,img_time))
# save_image(grid_image, args.out_path)
# print("type(grid) is: ", type(grid_image))
# print("grid_image.shape is: ", grid_image.shape)
print("image save in in_path.")
if __name__ == "__main__":
main()
# python demo.py --in-path your_file --out-path your_dst_file
运行以下命令:
python demo.py --in-path E:\PycharmProjects\Deeplab\pytorch-deeplab\test --ckpt run/invoice/deeplab-mobilenet/model_best.pth.tar --backbone mobilenet
- –in-path E:\PycharmProjects\Deeplab\pytorch-deeplab\test 是你测试的图片路径
- –ckpt run/invoice/deeplab-mobilnet/model_best.pth.tar 模型路径
最后的结果保存在输入图像的文件夹路径中:

只用了mobilenet,效果还不错,如果有条件的可以上更大的backbone,效果会更好。