第四章:OpenCV中的图像处理
第四章:OpenCV中的图像处理
本章节你将学习图像的改变色彩空间、提取对象、图像的几何变换、图像的阈值、平滑图像等OpenCV图像处理的基本内容。
更多内容请关注我的GitHub库:TonyStark1997,如果喜欢,star并follow我!
一、改变色彩空间
目标:
本章节你需要学习以下内容:
*你将学习如何将图像从一个颜色空间转换为另一个颜色空间,例如BGR↔Gray,BGR↔HSV等。
*除此之外,我们还将创建一个提取视频中某个特定彩色对象的应用程序
*你将学习以下函数:cv.cvtColor(),cv.inRange()等。
1.改变色彩空间
OpenCV中有150多种颜色空间转换方法。但我们将只研究两种最广泛使用的转换方法,BGR↔Gray和BGR↔HSV。
对于颜色转换,我们使用函数cv.cvtColor(input_image,flag),其中flag确定转换类型。
对于BGR→Gray转换,我们使用标志cv.COLOR_BGR2GRAY。类似地,对于BGR→HSV,我们使用标志cv.COLOR_BGR2HSV。要获取其他标志,只需在Python终端中运行以下命令:
>>> import cv2 as cv
>>> flags = [i for i in dir(cv) if i.startswith('COLOR_')]
>>> print( flags )
注意:对于HSV色彩空间,色调的取值范围是[0,179],饱和度的取值范围是[0,255],亮度的取值范围是[0,255]。不同的软件可能使用不同的取值方式,因此,如果要将OpenCV的HSV值与其他软件的HSV值进行比较时,则需要对这些范围进行标准化。
2.对象提取
现在我们知道如何将BGR图像转换为HSV,我们可以使用HSV色彩空间来提取彩色对象。在HSV中表示颜色比在BGR颜色空间中更容易。在我们的程序中,我们将尝试提取视频画面中的蓝色对象。下面是方法程序执行步骤:
- 获取视频中的每一帧
- 从BGR转换为HSV颜色空间
- 将HSV图像阈值设为一系列蓝色
- 单独提取并显示蓝色对象,之后我们便可以对我们想要的图像做任何事情。
以下是详细评论的代码:
import cv2 as cv
import numpy as np
cap = cv.VideoCapture(0)
while(1):
# Take each frame
_, frame = cap.read()
# Convert BGR to HSV
hsv = cv.cvtColor(frame, cv.COLOR_BGR2HSV)
# define range of blue color in HSV
lower_blue = np.array([110,50,50])
upper_blue = np.array([130,255,255])
# Threshold the HSV image to get only blue colors
mask = cv.inRange(hsv, lower_blue, upper_blue)
# Bitwise-AND mask and original image
res = cv.bitwise_and(frame,frame, mask= mask)
cv.imshow('frame',frame)
cv.imshow('mask',mask)
cv.imshow('res',res)
k = cv.waitKey(5) & 0xFF
if k == 27:
break
cv.destroyAllWindows()
下面的图片展示了我们提取蓝色对象后的效果:

注意:图像中有一些噪音,我们将在后面的章节中看到如何删除它们。这是对象提取中最简单的方法。一旦你学习了轮廓的功能,你就可以做很多事情,比如找到这个物体的重心并用它来追踪物体,只需在镜头前移动你的手以及许多其他有趣的东西来绘制图表。
3.如何找到要跟踪的HSV值
这是我们在stackoverflow.com中常见的问题。其实解决这个问题非常简单,你可以使用相同的函数cv.cvtColor()。你只需传递所需的BGR值,而不是传递图像。例如,要查找绿色的HSV值,在Python终端中输入以下命令:
>>> green = np.uint8([[[0,255,0 ]]])
>>> hsv_green = cv.cvtColor(green,cv.COLOR_BGR2HSV)
>>> print( hsv_green )
[[[ 60 255 255]]]
现在分别将[H-10,100,100]和[H+10,255,255]作为下限和上限。除了这种方法,你可以使用任何图像编辑工具如GIMP,或任何在线转换器来查找这些值,但不要忘记调整HSV范围。
二、图像的几何变换
目标
本章节你需要学习以下内容:
*将不同的几何变换应用于图像,如平移,旋转,仿射变换等。
*你将看到以下函数:cv.getPerspectiveTransform
1.转换
OpenCV提供了两个转换函数cv.warpAffine和cv.warpPerspective,你可以使用它们进行各种转换。cv.warpAffine采用2x3变换矩阵作为参数输入,而cv.warpPerspective采用3x3变换矩阵作为参数输入。
2.缩放
缩放只是调整图像大小。为此,OpenCV附带了一个函数cv.resize()。可以手动指定图像的大小,也可以指定缩放系数。可以使用不同的插值方法,常用的插值方法是用于缩小的cv.INTER_AREA和用于缩放的cv.INTER_CUBIC(慢)和cv.INTER_LINEAR。默认情况下,使用的插值方法是cv.INTER_LINEAR,它用于所有调整大小的目的。你可以使用以下方法之一调整输入图像的大小:
import numpy as np
import cv2 as cv
img = cv.imread('messi5.jpg')
res = cv.resize(img,None,fx=2, fy=2, interpolation = cv.INTER_CUBIC)
#OR
height, width = img.shape[:2]
res = cv.resize(img,(2*width, 2*height), interpolation = cv.INTER_CUBIC)
3.平移
平移是对象位置的移动。如果你知道像素点(x,y)要位移的距离,让它为变为( t x t_x tx, t y t_y ty),你可以创建变换矩阵M,如下所示:
M = [ 1 0 t x 0 1 t y ] M=\begin{bmatrix} 1&0&t_x\\ 0&1&t_y\\ \end{bmatrix} M=[1001txty]
你可以将其设置为np.float32类型的Numpy数组,并将其传递给cv.warpAffine()函数。下面的示例演示图像像素点整体进行(100,50)位移:
import numpy as np
import cv2 as cv
img = cv.imread('messi5.jpg',0)
rows,cols = img.shape
M = np.float32([[1,0,100],[0,1,50]])
dst = cv.warpAffine(img,M,(cols,rows))
cv.imshow('img',dst)
cv.waitKey(0)
cv.destroyAllWindows()
注意:cv.warpAffine()函数的第三个参数是输出图像的大小,它应该是(宽度,高度)的形式。请记住,width=列数,height=行数。
窗口将如下图显示:

4.旋转
通过改变图像矩阵实现图像旋转角度θ
M = [ c o s Θ − s i n Θ s i n Θ c o s Θ ] M=\begin{bmatrix} cos\Theta &-sin\Theta\\ sin\Theta & cos\Theta \end{bmatrix} M=[cosΘsinΘ−sinΘcosΘ]
但OpenCV提供可调旋转,即旋转中心可调,因此你可以在任何位置进行旋转。修正的变换矩阵由下式给出:
[ α β ( 1 − α ) ⋅ c e n t e r . x − β ⋅ c e n t e r . y − β α β ⋅ c e n t e r . x ( 1 − α ) ⋅ c e n t e r . y ] \begin{bmatrix} \alpha & \beta & \left ( 1-\alpha \right )\cdot center.x-\beta \cdot center.y \\ -\beta & \alpha & \beta \cdot center.x\left ( 1-\alpha \right )\cdot center.y \end{bmatrix} [α−ββα(1−α)⋅center.x−β⋅center.yβ⋅center.x(1−α)⋅center.y]
其中:
α = s c a l e ⋅ c o s Θ \alpha = scale\cdot cos\Theta α=scale⋅cosΘ
β = s c a l e ⋅ s i n Θ \beta = scale\cdot sin\Theta β=scale⋅sinΘ
为了找到这个转换矩阵,OpenCV提供了一个函数cv.getRotationMatrix2D。以下示例将图像相对于中心旋转90度而不进行任何缩放。
img = cv.imread('messi5.jpg',0)
rows,cols = img.shape
M = cv.getRotationMatrix2D((cols/2,rows/2),90,1)
dst = cv.warpAffine(img,M,(cols,rows))
窗口将如下图显示:

5.仿射变换
在仿射变换中,原始图像中的所有平行线仍将在输出图像中平行。为了找到变换矩阵,我们需要输入图像中的三个点及其在输出图像中的相应位置。然后cv.getAffineTransform将创建一个2x3矩阵,最后该矩阵将传递给cv.warpAffine。
参考以下示例,并查看我选择的点(以绿色标记):
img = cv.imread('drawing.png')
rows,cols,ch = img.shape
pts1 = np.float32([[50,50],[200,50],[50,200]])
pts2 = np.float32([[10,100],[200,50],[100,250]])
M = cv.getAffineTransform(pts1,pts2)
dst = cv.warpAffine(img,M,(cols,rows))
plt.subplot(121),plt.imshow(img),plt.title('Input')
plt.subplot(122),plt.imshow(dst),plt.title('Output')
plt.show()
窗口将如下图显示:

6.透视变换
对于透视变换,你需要一个3x3变换矩阵。即使在转换之后,直线仍将保持笔直。要找到此变换矩阵,输入图像上需要4个点,输出图像上需要相应的4个点。在这4个点中,其中任意3个不共线。然后可以通过函数cv.getPerspectiveTransform找到变换矩阵,将cv.warpPerspective应用于此3x3变换矩阵。
请参阅以下代码:
img = cv.imread('sudoku.png')
rows,cols,ch = img.shape
pts1 = np.float32([[56,65],[368,52],[28,387],[389,390]])
pts2 = np.float32([[0,0],[300,0],[0,300],[300,300]])
M = cv.getPerspectiveTransform(pts1,pts2)
dst = cv.warpPerspective(img,M,(300,300))
plt.subplot(121),plt.imshow(img),plt.title('Input')
plt.subplot(122),plt.imshow(dst),plt.title('Output')
窗口将如下图显示:
三、图象阈值
目标:
本章节你需要学习以下内容:
*你将学习简单的阈值处理,自适应阈值处理,Otsu的阈值处理等。
*你将学习以下函数:cv.threshold,cv.adaptiveThreshold等。
1.简单阈值处理
这种阈值处理的方法是简单易懂的。如果像素值大于阈值,则为其分配一个值(可以是白色),否则为其分配另一个值(可以是黑色)。使用的函数是cv.threshold。函数第一个参数是源图像,它应该是灰度图像。第二个参数是用于对像素值进行分类的阈值。第三个参数是maxVal,它表示如果像素值大于(有时小于)阈值则要给出的值。OpenCV提供不同类型的阈值,它由函数的第四个参数决定。不同的类型是:
- cv.THRESH_BINARY
- cv.THRESH_BINARY_INV
- cv.THRESH_TRUNC
- cv.THRESH_TOZERO
- cv.THRESH_TOZERO_INV
文档清楚地解释了每种类型的含义。请查看文档链接。
函数将获得两个输出。第一个是retavl,将在后面解释它的作用。第二个输出是我们的阈值图像。
参考以下代码:
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('gradient.png',0)
ret,thresh1 = cv.threshold(img,127,255,cv.THRESH_BINARY)
ret,thresh2 = cv.threshold(img,127,255,cv.THRESH_BINARY_INV)
ret,thresh3 = cv.threshold(img,127,255,cv.THRESH_TRUNC)
ret,thresh4 = cv.threshold(img,127,255,cv.THRESH_TOZERO)
ret,thresh5 = cv.threshold(img,127,255,cv.THRESH_TOZERO_INV)
titles = ['Original Image','BINARY','BINARY_INV','TRUNC','TOZERO','TOZERO_INV']
images = [img, thresh1, thresh2, thresh3, thresh4, thresh5]
for i in xrange(6):
plt.subplot(2,3,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
注意:为了绘制多个图像,我们使用了plt.subplot()函数。请查看Matplotlib文档以获取更多详细信息。
窗口将如下图显示:

2.自适应阈值处理
在上一节中,我们使用全局值作为阈值。但在图像在不同区域具有不同照明条件的所有条件下可能并不好。在那种情况下,我们进行自适应阈值处理。我们希望算法计算图像的小区域的阈值,因此,我们为同一图像的不同区域获得不同的阈值,并且它为具有不同照明的图像提供了更好的处理结果。
这种阈值处理方法有三个指定输入参数和一个输出参数。
Adaptive Method - 自适应方法,决定如何计算阈值。
- cv.ADAPTIVE_THRESH_MEAN_C:阈值是邻域的平均值。
- cv.ADAPTIVE_THRESH_GAUSSIAN_C:阈值是邻域值的加权和,其中权重是高斯窗口。
Block Size - 邻域大小,它决定了阈值区域的大小。
C - 它只是从计算的平均值或加权平均值中减去的常数。
下面的代码比较了具有不同照明的图像的全局阈值处理和自适应阈值处理:
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('sudoku.png',0)
img = cv.medianBlur(img,5)
ret,th1 = cv.threshold(img,127,255,cv.THRESH_BINARY)
th2 = cv.adaptiveThreshold(img,255,cv.ADAPTIVE_THRESH_MEAN_C,\
cv.THRESH_BINARY,11,2)
th3 = cv.adaptiveThreshold(img,255,cv.ADAPTIVE_THRESH_GAUSSIAN_C,\
cv.THRESH_BINARY,11,2)
titles = ['Original Image', 'Global Thresholding (v = 127)',
'Adaptive Mean Thresholding', 'Adaptive Gaussian Thresholding']
images = [img, th1, th2, th3]
for i in xrange(4):
plt.subplot(2,2,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
窗口将如下图显示:
3.Otsu’s 二值化
在第一节中,我只告诉你另一个参数是retVal,但没告诉你它的作用。其实,它是用来进行Otsu’s二值化。
在全局阈值处理中,我们使用任意值作为阈值,那么,我们如何知道我们选择的值是好还是不好?答案是,试错法。但如果是双峰图像(简单来说,双峰图像是直方图有两个峰值的图像)我们可以将这些峰值中间的值近似作为阈值,这就是Otsu二值化的作用。简单来说,它会根据双峰图像的图像直方图自动计算阈值。(对于非双峰图像,二值化不准确。)
为此,使用了我们的cv.threshold()函数,但是需要多传递一个参数cv.THRESH_OTSU。这时要吧阈值设为零。然后算法找到最佳阈值并返回第二个输出retVal。如果未使用Otsu二值化,则retVal与你设定的阈值相同。
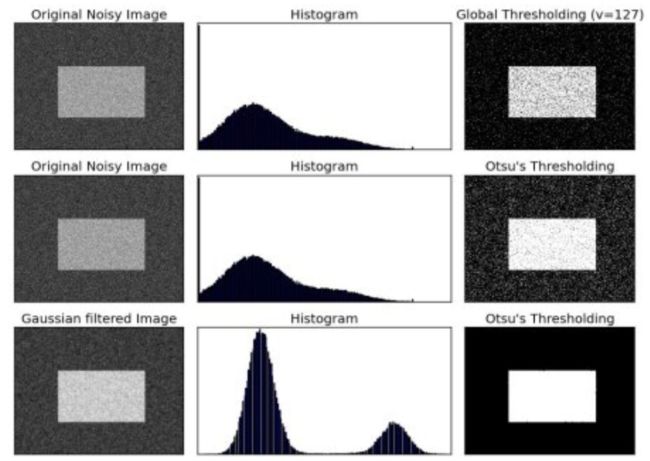
请查看以下示例。输入图像是嘈杂的图像。在第一种情况下,我将全局阈值应用为值127。在第二种情况下,我直接应用了Otsu的二值化。在第三种情况下,我使用5x5高斯卷积核过滤图像以消除噪声,然后应用Otsu阈值处理。来看看噪声过滤如何改善结果。
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('noisy2.png',0)
# global thresholding
ret1,th1 = cv.threshold(img,127,255,cv.THRESH_BINARY)
# Otsu's thresholding
ret2,th2 = cv.threshold(img,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)
# Otsu's thresholding after Gaussian filtering
blur = cv.GaussianBlur(img,(5,5),0)
ret3,th3 = cv.threshold(blur,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)
# plot all the images and their histograms
images = [img, 0, th1,
img, 0, th2,
blur, 0, th3]
titles = ['Original Noisy Image','Histogram','Global Thresholding (v=127)',
'Original Noisy Image','Histogram',"Otsu's Thresholding",
'Gaussian filtered Image','Histogram',"Otsu's Thresholding"]
for i in xrange(3):
plt.subplot(3,3,i*3+1),plt.imshow(images[i*3],'gray')
plt.title(titles[i*3]), plt.xticks([]), plt.yticks([])
plt.subplot(3,3,i*3+2),plt.hist(images[i*3].ravel(),256)
plt.title(titles[i*3+1]), plt.xticks([]), plt.yticks([])
plt.subplot(3,3,i*3+3),plt.imshow(images[i*3+2],'gray')
plt.title(titles[i*3+2]), plt.xticks([]), plt.yticks([])
plt.show()
窗口将如下图显示:
下面讲解了Otsu二值化的Python实现,以展示它的实际工作原理。如果你不感兴趣,可以跳过这个内容。
由于我们正在使用双峰图像,因此Otsu的算法试图找到一个阈值(t),它最小化了由关系给出的加权类内方差:
σ w 2 ( t ) = q 1 ( t ) σ 1 2 ( t ) + q 2 ( t ) σ 2 2 ( t ) \sigma _{w}^{2}\left ( t \right )= q_{1}\left ( t \right )\sigma _{1}^{2}\left ( t \right )+q_{2}\left ( t \right )\sigma _{2}^{2}\left ( t \right ) σw2(t)=q1(t)σ12(t)+q2(t)σ22(t)
其中:
q 1 ( t ) = ∑ i = 1 t P ( i ) & q 1 ( t ) = ∑ i = 1 I P ( i ) q_{1\left ( t \right )}=\sum_{i=1}^{t}P\left ( i \right ) \ \ \ \ \&\ \ \ \ q_{1\left ( t \right )}=\sum_{i=1}^{I}P\left ( i \right ) q1(t)=i=1∑tP(i) & q1(t)=i=1∑IP(i)
μ 1 ( t ) = ∑ t i = 1 i P ( i ) q 1 ( t ) & μ 2 ( t ) = ∑ I i = t + 1 i P ( i ) q 2 ( t ) \mu _{1}\left ( t \right )=\sum_{t}^{i=1}\frac{iP\left ( i \right )}{q_{1}\left ( t \right )}\ \ \ \ \ \ \&\ \ \ \ \ \ \mu _{2}\left ( t \right )=\sum_{I}^{i=t+1}\frac{iP\left ( i \right )}{q_{2}\left ( t \right )} μ1(t)=t∑i=1q1(t)iP(i) & μ2(t)=I∑i=t+1q2(t)iP(i)
σ 1 2 ( t ) = ∑ i = 1 t [ i − μ 1 ( t ) ] 2 P ( i ) q 1 ( t ) & σ 2 2 ( t ) = ∑ i = t + 1 I [ i − μ 1 ( t ) ] 2 P ( i ) q 2 ( t ) \sigma _{1}^{2}\left ( t \right )=\sum_{i=1}^{t}\left [ i - \mu _{1} \left ( t \right )\right ]^{2}\frac{P\left ( i \right )}{q_{1}\left ( t \right )}\ \ \ \ \&\ \ \ \ \sigma _{2}^{2}\left ( t \right )=\sum_{i=t+1}^{I}\left [ i - \mu _{1} \left ( t \right )\right ]^{2}\frac{P\left ( i \right )}{q_{2}\left ( t \right )} σ12(t)=i=1∑t[i−μ1(t)]2q1(t)P(i) & σ22(t)=i=t+1∑I[i−μ1(t)]2q2(t)P(i)
它实际上找到了一个位于两个峰之间的t值,这样两个类的方差都是最小的。它可以简单地在Python中实现,如下所示:
img = cv.imread('noisy2.png',0)
blur = cv.GaussianBlur(img,(5,5),0)
# find normalized_histogram, and its cumulative distribution function
hist = cv.calcHist([blur],[0],None,[256],[0,256])
hist_norm = hist.ravel()/hist.max()
Q = hist_norm.cumsum()
bins = np.arange(256)
fn_min = np.inf
thresh = -1
for i in xrange(1,256):
p1,p2 = np.hsplit(hist_norm,[i]) # probabilities
q1,q2 = Q[i],Q[255]-Q[i] # cum sum of classes
b1,b2 = np.hsplit(bins,[i]) # weights
# finding means and variances
m1,m2 = np.sum(p1*b1)/q1, np.sum(p2*b2)/q2
v1,v2 = np.sum(((b1-m1)**2)*p1)/q1,np.sum(((b2-m2)**2)*p2)/q2
# calculates the minimization function
fn = v1*q1 + v2*q2
if fn < fn_min:
fn_min = fn
thresh = i
# find otsu's threshold value with OpenCV function
ret, otsu = cv.threshold(blur,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)
print( "{} {}".format(thresh,ret) )
注意:这里的一些功能可能是之前没有讲过的,但我们将在后面的章节中介绍它们
四、平滑图像
目标:
本章节你需要学习以下内容:
*使用各种低通滤波器模糊图像
*将自定义滤波器应用于图像(2D卷积)
1、2D卷积(图像过滤)
与一维信号一样,图像也可以使用各种低通滤波器(LPF),高通滤波器(HPF)等进行滤波。LPF有助于消除噪声,模糊图像等。HPF滤波器有助于找到图片的边缘。
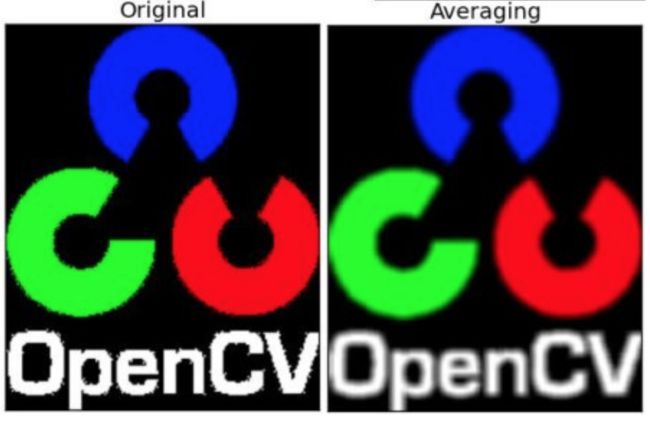
OpenCV提供了一个函数cv.filter2D()来将卷积核与图像进行卷积。例如,我们将尝试对图像进行平均滤波。下面是一个5x5平均滤波器的核:
K = 1 25 [ 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 ] K=\frac{1}{25}\begin{bmatrix} \ 1\ \ 1 \ \ 1 \ \ 1\ \ 1\\ \ 1\ \ 1 \ \ 1 \ \ 1\ \ 1\\ \ 1\ \ 1 \ \ 1 \ \ 1\ \ 1\\ \ 1\ \ 1 \ \ 1 \ \ 1\ \ 1\\ \ 1\ \ 1 \ \ 1 \ \ 1\ \ 1 \end{bmatrix} K=251⎣⎢⎢⎢⎢⎡ 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1⎦⎥⎥⎥⎥⎤
操作步骤如下:将此核放在一个像素A上,求与核对应的图像上 25(5x5)个像素的和,取其平均值并用新的平均值替换像素A的值。重复以上操作直到将图像的每一个像素值都更新一遍。试试这段代码并检查结果:
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('opencv_logo.png')
kernel = np.ones((5,5),np.float32)/25
dst = cv.filter2D(img,-1,kernel)
plt.subplot(121),plt.imshow(img),plt.title('Original')
plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(dst),plt.title('Averaging')
plt.xticks([]), plt.yticks([])
plt.show()
窗口将如下图显示:
2、图像模糊(图像平滑)
通过将图像与低通滤波器卷积核卷积来实现平滑图像。它有助于消除噪音,从图像中去除了高频内容(例如:噪声,边缘)。因此在此操作中边缘会模糊一点。(有的平滑技术也不会平滑边缘)。OpenCV主要提供四种平滑技术。
(1)平均
这是由一个归一化卷积框完成的。它取卷积核区域下所有像素的平均值并替换中心元素。这是由函数cv.blur()或cv.boxFilter()完成的。查看文档以获取有关卷积核的更多详细信息。我们应该指定卷积核的宽度和高度,3x3标准化的盒式过滤器如下所示:
K = 1 9 [ 1 1 1 1 1 1 1 1 1 ] K=\frac{1}{9}\begin{bmatrix} \ 1 \ \ 1\ \ 1\\ \ 1 \ \ 1\ \ 1\\ \ 1 \ \ 1\ \ 1 \end{bmatrix} K=91⎣⎡ 1 1 1 1 1 1 1 1 1⎦⎤
注意:如果不想使用规范化的框过滤器,请使用cv.boxFilter()。将参数normalize = False传递给函数。
使用5x5大小的卷积核检查下面的示例演示:
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('opencv-logo-white.png')
blur = cv.blur(img,(5,5))
plt.subplot(121),plt.imshow(img),plt.title('Original')
plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(blur),plt.title('Blurred')
plt.xticks([]), plt.yticks([])
plt.show()
窗口将如下图显示:

(2)高斯模糊
下面把卷积核换成高斯核。它是通过函数cv.GaussianBlur()完成的。我们应该指定卷积核的宽度和高度,它应该是正数并且是奇数。我们还应该分别指定X和Y方向的标准偏差sigmaX和sigmaY。如果仅指定了sigmaX,则sigmaY与sigmaX相同。如果两者都为零,则根据卷积核大小计算它们。高斯模糊在从图像中去除高斯噪声方面非常有效。
如果需要,可以使用函数cv.getGaussianKernel()创建高斯卷积核。
上面的代码可以修改为高斯模糊:
blur = cv.GaussianBlur(img,(5,5),0)
窗口将如下图显示:

(3)中位数模糊
顾名思义,函数cv.medianBlur()取卷积核区域下所有像素的中值,并用该中值替换中心元素。这对去除图像中的椒盐噪声非常有效。有趣的是,在上述滤波器中,中心元素是新计算的值,其可以是图像中的像素值或新值。但在中值模糊中,中心元素总是被图像中的某个像素值替换,它有效地降低了噪音。其卷积核大小应为正整数。
在这个演示中,我为原始图像添加了50%的噪点并应用了中值模糊。检查结果:
median = cv.medianBlur(img,5)
窗口将如下图显示:
(4)双边过滤
cv.bilateralFilter()在降低噪音方面非常有效,同时保持边缘清晰。但与其他过滤器相比,操作速度较慢。我们已经看到高斯滤波器采用像素周围的邻域并找到其高斯加权平均值。该高斯滤波器仅是空间的函数,即在滤波时考虑附近的像素。它没有考虑像素是否具有几乎相同的强度。它不考虑像素是否是边缘像素。所以它也模糊了边缘,我们不想这样做。
双边滤波器在空间中也采用高斯滤波器,但是还有一个高斯滤波器是像素差的函数。空间的高斯函数确保仅考虑附近的像素用于模糊,而强度差的高斯函数确保仅考虑具有与中心像素相似的强度的像素用于模糊。因此它保留了边缘,因为边缘处的像素将具有较大的强度变化。
下面的示例显示使用双边过滤器(有关参数的详细信息,请访问docs)。
blur = cv.bilateralFilter(img,9,75,75)
窗口将如下图显示:

五、形态学转换
目标:
本章节你需要学习以下内容:
*你将学习不同的形态学操作,如侵蚀,膨胀,开放,关闭等。
*你将看到不同的函数,如:cv.erode(),cv.dilate(),cv.morphologyEx()等。
理论
形态学转换是基于图像形状的一些简单操作。它通常在二进制图像上执行。它需要两个输入参数,一个是我们的原始图像,第二个是称为结构元素或卷积核,它决定了操作的性质。腐蚀和膨胀是两个基本的形态学运算符。然后它的变体形式如开运算,闭运算,梯度等也发挥作用。我们将在以下图片的帮助下逐一看到它们:

1、腐蚀
腐蚀的基本思想就像土壤侵蚀一样,它会腐蚀前景物体的边界(总是试图保持前景为白色)。它是如何做到的呢?卷积核在图像中滑动(如在2D卷积中),只有当卷积核下的所有像素都是1时,原始图像中的像素(1或0)才会被认为是1,否则它会被腐蚀(变为零)。
所以腐蚀作用后,边界附近的所有像素都将被丢弃,具体取决于卷积核的大小。因此,前景对象的厚度或大小减小,或者图像中的白色区域减小。它有助于消除小的白噪声(正如我们在色彩空间章节中看到的那样),或者分离两个连接的对象等。
在这里,作为一个例子,我将使用一个5x5卷积核,其中包含完整的卷积核。让我们看看它是如何工作的:
import cv2 as cv
import numpy as np
img = cv.imread('j.png',0)
kernel = np.ones((5,5),np.uint8)
erosion = cv.erode(img,kernel,iterations = 1)
窗口将如下图显示:

2、膨胀
它恰好与腐蚀相反。这里,如果卷积核下的像素至少一个像素为“1”,则像素元素为“1”。因此它增加了图像中的白色区域或前景对象的大小增加。通常,在去除噪音的情况下,侵蚀之后是扩张。因为,侵蚀会消除白噪声,但它也会缩小我们的物体,所以我们扩大它。由于噪音消失了,它们不会再回来,但我们的物体区域会增加。它也可用于连接对象的破碎部分。
dilation = cv.dilate(img,kernel,iterations = 1)
窗口将如下图显示:

3、开运算
开运算只是腐蚀之后紧接着做扩张处理的合成步骤。如上所述,它有助于消除噪音。这里我们使用函数cv.morphologyEx()
opening = cv.morphologyEx(img, cv.MORPH_OPEN, kernel)
窗口将如下图显示:

4、闭运算
闭运算与开运算,膨胀和腐蚀相反。它可用于过滤前景对象内的小孔或对象上的小黑点。
closing = cv.morphologyEx(img, cv.MORPH_CLOSE, kernel)
窗口将如下图显示:

5、形态学梯度
它的处理结果是显示膨胀和腐蚀之间的差异。
结果看起来像对象的轮廓。
gradient = cv.morphologyEx(img, cv.MORPH_GRADIENT, kernel)
窗口将如下图显示:

6、礼帽
它的处理结果是输入图像和开运算之间的区别。下面的示例是针对9x9卷积核完成的。
tophat = cv.morphologyEx(img, cv.MORPH_TOPHAT, kernel)
窗口将如下图显示:

7、黑帽
它是输入图像闭运算和输入图像之间的差异。
blackhat = cv.morphologyEx(img, cv.MORPH_BLACKHAT, kernel)
窗口将如下图显示:

8、结构元素
我们在Numpy的帮助下手动创建了前面示例中的结构元素。它是正方形的,但在某些情况下可能需要椭圆或圆形卷积核。所以为此,OpenCV有一个函数cv.getStructuringElement()。只需传递卷积核的形状和大小,即可获得所需的卷积核。
# Rectangular Kernel
>>> cv.getStructuringElement(cv.MORPH_RECT,(5,5))
array([[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1]], dtype=uint8)
# Elliptical Kernel
>>> cv.getStructuringElement(cv.MORPH_ELLIPSE,(5,5))
array([[0, 0, 1, 0, 0],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[0, 0, 1, 0, 0]], dtype=uint8)
# Cross-shaped Kernel
>>> cv.getStructuringElement(cv.MORPH_CROSS,(5,5))
array([[0, 0, 1, 0, 0],
[0, 0, 1, 0, 0],
[1, 1, 1, 1, 1],
[0, 0, 1, 0, 0],
[0, 0, 1, 0, 0]], dtype=uint8)
六、图像梯度
目标:
本章节你需要学习以下内容:
*查找图像渐变,边缘等
*我们将看到以下函数:cv.Sobel(),cv.Scharr(),cv.Laplacian()等
1、理论
OpenCV提供三种类型的梯度滤波器或高通滤波器,Sobel,Scharr和Laplacian。我们会一一介绍他们。
Sobel,Scharr 其实就是求一阶或二阶导数。Scharr是对Sobel(使用小的卷积核求解求解梯度角度时)的优化。Laplacian 是求二阶导数。
(1)Sobel算子和Scharr算子
Sobel算子是高斯联合平滑加微分运算,因此它更能抵抗噪声。你可以指定要采用的导数的方向,垂直或水平(分别通过参数,yorder和xorder),你还可以通过参数ksize指定卷积核的大小。如果ksize = -1,则使用3x3的Scharr滤波器,其结果优于3x3的Sobel滤波器。请参阅所用卷积核的文档。
(2)Laplacian算子
它计算由关系给出的图像的拉普拉斯算子, Δ s r c = ∂ 2 s r c ∂ x 2 + ∂ 2 s r c ∂ y 2 \Delta src= \frac{\partial ^{2}src}{\partial x^{2}}+ \frac{\partial ^{2}src}{\partial y^{2}} Δsrc=∂x2∂2src+∂y2∂2src,其中使用Sobel导数找到每个导数。 如果ksize = 1,则使用以下卷积核进行过滤:
k e r n e l = [ 0 1 0 1 − 4 1 0 1 0 ] kernel=\begin{bmatrix} \ 0\ \ \ \ 1\ \ \ \ 0\\ \ 1\ -4\ \ 1\\ \ 0\ \ \ \ 1\ \ \ \ 0 \end{bmatrix} kernel=⎣⎡ 0 1 0 1 −4 1 0 1 0⎦⎤
2、代码实现
下面的代码显示了单个图表中的所有运算符,所有卷积核都是5x5大小。输出图像的深度为-1,以获得np.uint8类型的结果。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('dave.jpg',0)
laplacian = cv.Laplacian(img,cv.CV_64F)
sobelx = cv.Sobel(img,cv.CV_64F,1,0,ksize=5)
sobely = cv.Sobel(img,cv.CV_64F,0,1,ksize=5)
plt.subplot(2,2,1),plt.imshow(img,cmap = 'gray')
plt.title('Original'), plt.xticks([]), plt.yticks([])
plt.subplot(2,2,2),plt.imshow(laplacian,cmap = 'gray')
plt.title('Laplacian'), plt.xticks([]), plt.yticks([])
plt.subplot(2,2,3),plt.imshow(sobelx,cmap = 'gray')
plt.title('Sobel X'), plt.xticks([]), plt.yticks([])
plt.subplot(2,2,4),plt.imshow(sobely,cmap = 'gray')
plt.title('Sobel Y'), plt.xticks([]), plt.yticks([])
plt.show()
窗口将如下图显示:

3、一个重要的事情
在我们的上一个示例中,输出数据类型为cv.CV_8U或np.uint8,但是这有一个小问题,将黑到白转换视为正斜率(它具有正值),而将白到黑转换视为负斜率(它具有负值)。因此,当你将数据转换为np.uint8时,所有负斜率都为零。简单来说,你丢掉了所有的边界。
如果要检测两个边,更好的选择是将输出数据类型保持为某些更高的形式,如cv.CV_16S,cv.CV_64F等,取其绝对值,然后转换回cv.CV_8U。下面的代码演示了水平Sobel滤波器的这个过程以及结果的差异。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('box.png',0)
# Output dtype = cv.CV_8U
sobelx8u = cv.Sobel(img,cv.CV_8U,1,0,ksize=5)
# Output dtype = cv.CV_64F. Then take its absolute and convert to cv.CV_8U
sobelx64f = cv.Sobel(img,cv.CV_64F,1,0,ksize=5)
abs_sobel64f = np.absolute(sobelx64f)
sobel_8u = np.uint8(abs_sobel64f)
plt.subplot(1,3,1),plt.imshow(img,cmap = 'gray')
plt.title('Original'), plt.xticks([]), plt.yticks([])
plt.subplot(1,3,2),plt.imshow(sobelx8u,cmap = 'gray')
plt.title('Sobel CV_8U'), plt.xticks([]), plt.yticks([])
plt.subplot(1,3,3),plt.imshow(sobel_8u,cmap = 'gray')
plt.title('Sobel abs(CV_64F)'), plt.xticks([]), plt.yticks([])
plt.show()
窗口将如下图显示:

七、Canny边缘检测
目标:
本章节你需要学习以下内容:
*Canny边缘检测的概念
*OpenCV的功能:cv.Canny()
1、理论
Canny边缘检测是一种流行的边缘检测算法,它是由John F. Canny开发的
这是一个多阶段算法,我们将了解其中的每个阶段。
(1)降噪
由于边缘检测易受图像中的噪声影响,因此第一步是使用5x5高斯滤波器去除图像中的噪声。我们在之前的章节中已经看到了这一点。
(2)计算图像的强度梯度
然后在水平和垂直方向上用Sobel核对平滑后的图像进行滤波,以获得水平方向( G x G_{x} Gx)和垂直方向( G y G_{y} Gy)的一阶导数。从这两个图像中,我们可以找到每个像素的边缘梯度和方向,如下所示:
E d g e _ G r a d i e n t ( G ) = G x 2 + G y 2 Edge\_Gradient\left ( G \right )= \sqrt{G_{x}^{2}+G_{y}^{2}} Edge_Gradient(G)=Gx2+Gy2
A n g l e ( θ ) = t a n − 1 ( G y G x ) Angle\left ( \theta \right )= tan^{-1}\left ( \frac{G_{y}}{G_{x}} \right ) Angle(θ)=tan−1(GxGy)
渐变方向始终垂直于边缘。梯度方向被归为四类:垂直,水平,和两个对角线。
(3)非极大值抑制
在获得梯度的大小和方向之后,完成图像的全扫描以去除可能不构成边缘的任何不需要的像素。为此,在每个像素处,检查像素是否是其在梯度方向上的邻域中的局部最大值。检查下图:
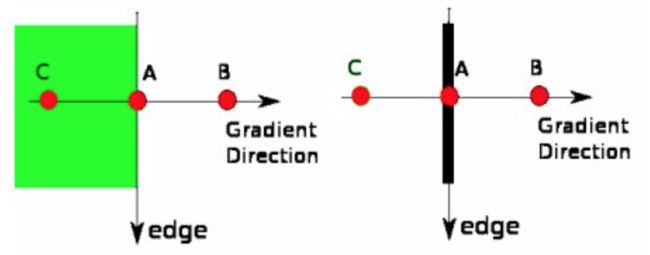
A点位于边缘(垂直方向)。渐变方向与边缘垂直。B点和C点处于梯度方向。因此,用点B和C检查点A,看它是否形成局部最大值。如果是这样,则考虑下一阶段,否则,它被抑制(置零)。
简而言之,你得到的结果是具有“细边”的二进制图像。
(4)滞后阈值
这个阶段决定哪些边缘都是边缘,哪些边缘不是边缘。为此,我们需要两个阈值,minVal和maxVal。强度梯度大于maxVal的任何边缘肯定是边缘,而minVal以下的边缘肯定是非边缘的,因此被丢弃。位于这两个阈值之间的人是基于其连通性的分类边缘或非边缘。如果它们连接到“可靠边缘”像素,则它们被视为边缘的一部分。否则,他们也被丢弃。见下图:

边缘A高于maxVal,因此被视为“确定边缘”。虽然边C低于maxVal,但它连接到边A,因此也被视为有效边,我们得到完整的曲线。但边缘B虽然高于minVal并且与边缘C的区域相同,但它没有连接到任何“可靠边缘”,因此被丢弃。所以我们必须相应地选择minVal和maxVal才能获得正确的结果。
假设边是长线,这个阶段也会消除小像素噪声。
所以我们最终得到的是图像中的强边缘。
2、OpenCV中的Canny边缘检测
OpenCV将以上所有步骤放在单个函数cv.Canny()中。我们将看到如何使用它。第一个参数是我们的输入图像。第二个和第三个参数分别是我们的minVal和maxVal。第三个参数是aperture_size,它是用于查找图像渐变的Sobel卷积核的大小。默认情况下它是3。最后一个参数是L2gradient,它指定用于查找梯度幅度的等式。如果它是True,它使用上面提到的更准确的等式,否则它使用这个函数: E d g e _ G r a d i e n t ( G ) = ∣ G x ∣ + ∣ G y ∣ Edge\_Gradient\left ( G \right )= \left | G_{x} \right |+\left | G_{y} \right | Edge_Gradient(G)=∣Gx∣+∣Gy∣。默认情况下,它为False。
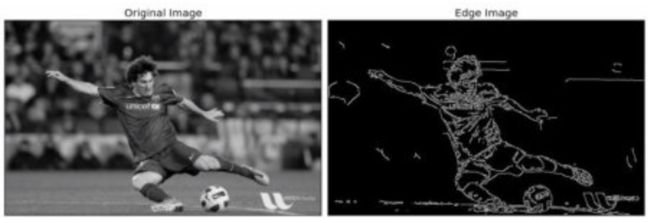
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('messi5.jpg',0)
edges = cv.Canny(img,100,200)
plt.subplot(121),plt.imshow(img,cmap = 'gray')
plt.title('Original Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(edges,cmap = 'gray')
plt.title('Edge Image'), plt.xticks([]), plt.yticks([])
plt.show()
窗口将如下图显示:
八、图像金字塔
目标:
本章节你需要学习以下内容:
*我们将了解Image Pyramids
*我们将使用Image金字塔创建一个新的水果,“Orapple”
*我们将看到这些函数:cv.pyrUp(),cv.pyrDown()
1、理论
通常,我们曾经使用恒定大小的图像。但在某些情况下,我们需要使用不同分辨率的(相同)图像。例如,在搜索图像中的某些内容时,如脸部,我们不确定该对象在所述图像中的大小。在这种情况下,我们需要创建一组具有不同分辨率的相同图像,并在所有图像中搜索对象。这些具有不同分辨率的图像被称为图像金字塔(因为当它们保持在堆叠中,底部具有最高分辨率图像而顶部具有最低分辨率图像时,它看起来像金字塔)。
图像金字塔有两种:高斯金字塔和拉普拉斯金字塔
通过去除较低级别(较高分辨率)图像中的连续行和列来形成高斯金字塔中的较高级别(低分辨率)。然后,较高级别中的每个像素由来自基础级别中的5个像素的贡献形成,具有高斯权重。通过这样做,M×N图像变为M/2 × N/2图像。因此面积减少到原始面积的四分之一。它被称为Octave。当我们在金字塔中上升时(即分辨率降低)将以相同的模式继续。同样,在扩展时,每个级别的区域变为4次。我们可以使用cv.pyrDown()和cv.pyrUp()函数找到高斯金字塔。
img = cv.imread('messi5.jpg')
lower_reso = cv.pyrDown(higher_reso)
窗口将如下图显示:
现在,你可以使用cv.pyrUp()函数沿着图像金字塔向下移动。
higher_reso2 = cv.pyrUp(lower_reso)
请记住,higher_reso2不等于higher_reso,因为一旦降低了分辨率,就会丢失信息。下图是从前一种情况下的最小图像创建的金字塔下3级。将其与原始图像进行比较:

拉普拉斯金字塔由高斯金字塔形成,没有特别的功能。拉普拉斯金字塔图像仅与边缘图像相似。它的大部分元素都是零。它们用于图像压缩。拉普拉斯金字塔中的一个层次由高斯金字塔中的该层次与高斯金字塔中的上层的扩展版本之间的差异形成。拉普拉斯级别的三个级别如下所示(调整对比度以增强内容):

2、使用金字塔的图像混合
金字塔的一个应用是图像混合。例如,在图像拼接中,你需要将两个图像堆叠在一起,但由于图像之间的不连续性,它可能看起来不太好。在这种情况下,与金字塔混合的图像可以让你无缝混合,而不会在图像中留下太多数据。其中一个典型的例子是混合了两种水果,橙子和苹果。 现在查看结果以了解我在说什么:
请在附加资源中查看第一个参考资料,它有关于图像混合,拉普拉斯金字塔等的完整图表细节。简单地完成如下:
- 加载苹果和橙色的两个图像
- 找到苹果和橙色的高斯金字塔(在这个特殊的例子中,级别数是6)
- 从高斯金字塔,找到他们的拉普拉斯金字塔
- 现在加入左半部分的苹果和右半部分的拉普拉斯金字塔
- 最后,从这个联合图像金字塔,重建原始图像。
以下是完整的代码。(为简单起见,每个步骤都是单独完成的,可能会占用更多内存。如果需要,可以对其进行优化)。
import cv2 as cv
import numpy as np,sys
A = cv.imread('apple.jpg')
B = cv.imread('orange.jpg')
# generate Gaussian pyramid for A
G = A.copy()
gpA = [G]
for i in xrange(6):
G = cv.pyrDown(G)
gpA.append(G)
# generate Gaussian pyramid for B
G = B.copy()
gpB = [G]
for i in xrange(6):
G = cv.pyrDown(G)
gpB.append(G)
# generate Laplacian Pyramid for A
lpA = [gpA[5]]
for i in xrange(5,0,-1):
GE = cv.pyrUp(gpA[i])
L = cv.subtract(gpA[i-1],GE)
lpA.append(L)
# generate Laplacian Pyramid for B
lpB = [gpB[5]]
for i in xrange(5,0,-1):
GE = cv.pyrUp(gpB[i])
L = cv.subtract(gpB[i-1],GE)
lpB.append(L)
# Now add left and right halves of images in each level
LS = []
for la,lb in zip(lpA,lpB):
rows,cols,dpt = la.shape
ls = np.hstack((la[:,0:cols/2], lb[:,cols/2:]))
LS.append(ls)
# now reconstruct
ls_ = LS[0]
for i in xrange(1,6):
ls_ = cv.pyrUp(ls_)
ls_ = cv.add(ls_, LS[i])
# image with direct connecting each half
real = np.hstack((A[:,:cols/2],B[:,cols/2:]))
cv.imwrite('Pyramid_blending2.jpg',ls_)
cv.imwrite('Direct_blending.jpg',real)
九、图像的轮廓
目标:
本章节你需要学习以下内容:
*了解什么是轮廓
*学习找轮廓,绘制轮廓等
*找到轮廓的不同特征,如面积,周长,质心,边界框等
*学习提取一些常用的对象属性,如Solidity,Equivalent Diameter,Mask image,Mean Intensity等。
*凸性缺陷以及如何找到它们。
*寻找从点到多边形的最短距离
*匹配不同的形状
*了解了轮廓的层次结构,即Contours中的父子关系。
*你会看到这些函数:cv.findContours(),cv.drawContours()
1、轮廓:入门
(1)什么是轮廓?
轮廓可以简单地解释为连接所有具有相同的颜色或强度的连续点(沿着边界)的曲线。轮廓是形状分析和物体检测和识别的很有用的工具。
- 为了更好的准确性,使用二进制图像,因此,在找到轮廓之前,应用阈值或canny边缘检测。
- 从OpenCV 3.2开始,findContours()不再修改源图像,而是将修改后的图像作为三个返回参数中的第一个返回。
- 在OpenCV中,找到轮廓就像从黑色背景中找到白色物体。所以请记住,要找到的对象应该是白色,背景应该是黑色。
让我们看看如何找到二进制图像的轮廓:
import numpy as np
import cv2 as cv
im = cv.imread('test.jpg')
imgray = cv.cvtColor(im, cv.COLOR_BGR2GRAY)
ret, thresh = cv.threshold(imgray, 127, 255, 0)
im2, contours, hierarchy = cv.findContours(thresh, cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE)
参见cv.findContours()函数中有三个参数,第一个是源图像,第二个是轮廓检索模式,第三个是轮廓的近似方法。它输出修改后的图像,显示出轮廓和层次结构。轮廓是图像中所有轮廓的Python列表。每个单独的轮廓是对象的边界点的(x,y)坐标的Numpy阵列。
注意:我们稍后将详细讨论第二和第三个参数以及层次结构。在此之前,代码示例中给出的值对所有图像都可以正常工作。
(2)如何绘制轮廓?
要绘制轮廓,可以使用cv.drawContours函数。如果图像有边界点,它也可以用于绘制任何形状。它的第一个参数是源图像,第二个参数是应该作为Python列表传递的轮廓,第三个参数是轮廓索引(在绘制单个轮廓时很有用。绘制所有轮廓,传递-1),其余参数是颜色,厚度等等
要绘制图像中的所有轮廓:
cv.drawContours(img, contours, -1, (0,255,0), 3)
要绘制单个轮廓,请输入四个轮廓点:
cv.drawContours(img, contours, 3, (0,255,0), 3)
但大多数时候,下面的方法会很有用:
cnt = contours[4]
cv.drawContours(img, [cnt], 0, (0,255,0), 3)
注意:最后两种方法是相同的,但是当你继续前进时,你会发现最后一种方法更有用。
(3)轮廓近似方法
这是cv.findContours函数中的第三个参数。它实际上表示什么?
在上面,我们告诉轮廓是具有相同强度的形状的边界。它存储形状边界的(x,y)坐标。但是它存储了所有坐标吗?这由该轮廓近似方法指定。
如果传递cv.CHAIN_APPROX_NONE,则存储所有边界点。但实际上我们需要所有的积分吗?例如,你找到了直线的轮廓,你是否需要线上的所有点来表示该线?不,我们只需要该线的两个端点。这就是cv.CHAIN_APPROX_SIMPLE的作用。它删除所有冗余点并压缩轮廓,从而节省内存。
下面的矩形图像展示了这种技术。只需在轮廓阵列中的所有坐标上绘制一个圆圈(以蓝色绘制)。第一张图片显示了我用cv.CHAIN_APPROX_NONE(734点)获得的点数,第二张图片显示了一张带有cv.CHAIN_APPROX_SIMPLE(仅4点)的点数,它节省了多少内存!

2、轮廓特征
(1)矩
图像矩可帮助你计算某些特征,如对象的质心,对象的区域等。具体定义可以查看图像矩的维基百科页面
函数cv.moments()给出了计算的所有矩值的字典。见下文:
import numpy as np
import cv2 as cv
img = cv.imread('star.jpg',0)
ret,thresh = cv.threshold(img,127,255,0)
im2,contours,hierarchy = cv.findContours(thresh, 1, 2)
cnt = contours[0]
M = cv.moments(cnt)
print( M )
从这一刻起,你可以提取有用的数据,如面积,质心等。质心由关系给出, C x = M 10 M 00 C_{x}=\frac{M_{10}}{M_{00}} Cx=M00M10和 C y = M 01 M 00 C_{y}=\frac{M_{01}}{M_{00}} Cy=M00M01。这可以按如下方式完成:
cx = int(M['m10']/M['m00'])
cy = int(M['m01']/M['m00'])
(2)轮廓区域
轮廓区域由函数cv.contourArea()或时刻M[‘m00’]给出。
area = cv.contourArea(cnt)
(3)轮廓周长
轮廓周长也被称为弧长。可以使用cv.arcLength()函数找到它。第二个参数指定形状是闭合轮廓(如果传递为True),还是仅仅是曲线。
perimeter = cv.arcLength(cnt,True)
(4)轮廓近似
它根据我们指定的精度将轮廓形状近似为具有较少顶点数的另一个形状。它是Douglas-Peucker算法的一种实现方式。查看维基百科页面以获取算法和演示。
要理解这一点,可以假设你试图在图像中找到一个正方形,但是由于图像中的一些问题,你没有得到一个完美的正方形,而是一个“坏形状”(如下图第一张图所示)。现在你可以使用此功能来近似形状。在这里,第二个参数称为epsilon,它是从轮廓到近似轮廓的最大距离。这是一个准确度参数。需要选择适当的epsilon才能获得正确的输出。
epsilon = 0.1*cv.arcLength(cnt,True)
approx = cv.approxPolyDP(cnt,epsilon,True)
下面,在第二幅图像中,绿线表示epsilon=弧长的10%的近似曲线。第三幅图像显示相同的epsilon=弧长的1%。第三个参数指定曲线是否关闭。

(5)凸包
凸包看起来类似于轮廓近似,但它不是(两者在某些情况下可能提供相同的结果)。这里,cv.convexHull()函数检查曲线的凸性缺陷并进行修正。一般而言,凸曲线是总是凸出或至少平坦的曲线。如果它在内部膨胀,则称为凸性缺陷。例如,检查下面的手形图像。红线表示手的凸包。双面箭头标记显示凸起缺陷,即船体与轮廓的局部最大偏差。

下面我们要讨论它的一些语法:
hull = cv.convexHull(points[, hull[, clockwise[, returnPoints]]
参数详情:
- points:是我们传入的轮廓。
- hull:是输出,通常我们忽略它。
- clocwise:方向标志。如果为True,则输出凸包顺时针方向。否则,它逆时针方向。
- returnPoints:默认为True。然后它返回凸包点的坐标。如果为False,则返回与凸包点对应的轮廓点的索引。
因此,为了获得如上图所示的凸包,以下就足够了:
hull = cv.convexHull(cnt)
但是如果你想找到凸性缺陷,你需要传递returnPoints = False。为了理解它,我们将采用上面的矩形图像。首先,我发现它的轮廓为cnt。现在我发现它的凸包有returnPoints = True,我得到以下值:[[234 202],[51 202],[51 79],[234 79]]这四个角落 矩形点。 现在如果对returnPoints = False做同样的事情,我得到以下结果:[[129],[67],[0],[142]]。 这些是轮廓中相应点的索引。例如,检查第一个值:cnt [129] = [[234,202]],它与第一个结果相同(对于其他结果,依此类推)。
当我们讨论凸性缺陷时,你会再次看到它。
(6)检查凸性
函数cv.isContourConvex()可以检查曲线是否凸的,它只返回True或False,没有什么理解上的问题。
k = cv.isContourConvex(cnt)
(7)边界矩形
有两种类型的边界矩形。
A.直边矩形
它是一个直的矩形,它不考虑对象的旋转。因此,边界矩形的面积不是最小的。它由函数cv.boundingRect()找到。
设(x,y)为矩形的左上角坐标,(w,h)为宽度和高度。
x,y,w,h = cv.boundingRect(cnt)
cv.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)
b.旋转矩形
这里,以最小面积绘制边界矩形,因此它也考虑旋转。使用的函数是cv.minAreaRect()。它返回一个Box2D结构,其中包含以下detals - (center(x,y),(width,height),rotation of rotation)。但要画这个矩形,我们需要矩形的4个角。它是由函数cv.boxPoints()获得的
rect = cv.minAreaRect(cnt)
box = cv.boxPoints(rect)
box = np.int0(box)
cv.drawContours(img,[box],0,(0,0,255),2)
两个矩形都显示在单个图像中。绿色矩形显示正常的边界矩形。红色矩形是旋转的矩形。

(8)最小外接圈
接下来,我们使用函数cv.minEnclosingCircle()找到对象的外接圆。它是一个完全覆盖物体的圆圈,面积最小。
(x,y),radius = cv.minEnclosingCircle(cnt)
center = (int(x),int(y))
radius = int(radius)
cv.circle(img,center,radius,(0,255,0),2

(9)椭圆拟合
接下来是将椭圆拟合到一个对象上。它返回刻有椭圆的旋转矩形。
ellipse = cv.fitEllipse(cnt)
cv.ellipse(img,ellipse,(0,255,0),2)

(10)拟合一条线
类似地,我们可以在一组点上拟合一条线。下图包含一组白点。 我们可以近似直线。
rows,cols = img.shape[:2]
[vx,vy,x,y] = cv.fitLine(cnt, cv.DIST_L2,0,0.01,0.01)
lefty = int((-x*vy/vx) + y)
righty = int(((cols-x)*vy/vx)+y)
cv.line(img,(cols-1,righty),(0,lefty),(0,255,0),2)

3、轮廓属性
(1)Aspect Ratio(长宽比)
它是对象的边界矩形的宽度与高度的比。
A s p e c t R a t i o = W i d t h H e i g h t Aspect\ Ratio= \frac{Width}{Height} Aspect Ratio=HeightWidth
x,y,w,h = cv.boundingRect(cnt)
aspect_ratio = float(w)/h
(2)Extent(大小比)
它是轮廓区域与边界矩形区域的比。
E x t e n t = O b j e c t A r e a B o u n d i n g R e c t a n g l e A r e a Extent= \frac{Object\ Area}{Bounding\ Rectangle\ Area} Extent=Bounding Rectangle AreaObject Area
area = cv.contourArea(cnt)
x,y,w,h = cv.boundingRect(cnt)
rect_area = w*h
extent = float(area)/rect_area
(3)Solidity(密实比)
Solidity是轮廓区域与其凸包区域的比率。
S o l i d i t y = C o n t o u r A r e a C o n v e x H u l l A r e a Solidity= \frac{Contour\ Area}{Convex\ Hull\ Area} Solidity=Convex Hull AreaContour Area
area = cv.contourArea(cnt)
hull = cv.convexHull(cnt)
hull_area = cv.contourArea(hull)
solidity = float(area)/hull_area
(4)Equivalent Diameter(等效直径)
等效直径是圆的直径,其面积与轮廓面积相同。
E q u i v a l e n t D i a m e t e r = 4 × C o n t o u r A r e a π Equivalent\ Diameter=\sqrt{\frac{4\times Contour\ Area}{\pi }} Equivalent Diameter=π4×Contour Area
area = cv.contourArea(cnt)
equi_diameter = np.sqrt(4*area/np.pi)
(5)Orientation(方向)
方向是对象定向的角度。以下方法还给出了主轴和短轴长度。
(x,y),(MA,ma),angle = cv.fitEllipse(cnt)
(6)Mask & Pixel Points(掩模和像素点)
在某些情况下,我们可能需要包含该对象的所有点。它可以如下完成:
mask = np.zeros(imgray.shape,np.uint8)
cv.drawContours(mask,[cnt],0,255,-1)
pixelpoints = np.transpose(np.nonzero(mask))
#pixelpoints = cv.findNonZero(mask)
这里,两个方法,一个使用Numpy函数,另一个使用OpenCV函数(最后一个注释行)给出相同的方法。 结果也相同,但略有不同。 Numpy以**(行,列)格式给出坐标,而OpenCV以(x,y)**格式给出坐标。所以答案基本上会互换。请注意,row=x和column=y。
(7)最大值,最小值及其位置
我们可以使用掩模图像找到这些参数。
min_val, max_val, min_loc, max_loc = cv.minMaxLoc(imgray,mask = mask)
(8)平均颜色或平均灰度
在这里,我们可以找到对象的平均颜色。或者它可以是灰度模式下物体的平均强度。我们再次使用相同的面具来做到这一点。
mean_val = cv.mean(im,mask = mask)
(9)极点
极值点表示对象的最顶部,最底部,最右侧和最左侧的点。
leftmost = tuple(cnt[cnt[:,:,0].argmin()][0])
rightmost = tuple(cnt[cnt[:,:,0].argmax()][0])
topmost = tuple(cnt[cnt[:,:,1].argmin()][0])
bottommost = tuple(cnt[cnt[:,:,1].argmax()][0])
例如,如果我将它应用于印度地图,我会得到以下结果:

4、轮廓:更多功能
(1)1.凸缺陷
我们在前面学到了关于轮廓的凸包。物体与该凸包的任何偏差都可以被认为是凸缺陷。
OpenCV附带了一个现成的函数来查找它,cv.convexityDefects()。基本函数调用如下所示:
hull = cv.convexHull(cnt,returnPoints = False)
defects = cv.convexityDefects(cnt,hull)
注意:我们必须在找到凸包时传递returnPoints = False,以便找到凸缺陷。
它返回一个数组,其中每一行包含这些值 - [起点,终点,最远点,到最远点的近似距离]。我们可以使用图像将其可视化。我们绘制一条连接起点和终点的线,然后在最远点绘制一个圆。请记住,返回的前三个值是cnt的索引。所以我们必须从cnt中提取这些值。
import cv2 as cv
import numpy as np
img = cv.imread('star.jpg')
img_gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
ret,thresh = cv.threshold(img_gray, 127, 255,0)
im2,contours,hierarchy = cv.findContours(thresh,2,1)
cnt = contours[0]
hull = cv.convexHull(cnt,returnPoints = False)
defects = cv.convexityDefects(cnt,hull)
for i in range(defects.shape[0]):
s,e,f,d = defects[i,0]
start = tuple(cnt[s][0])
end = tuple(cnt[e][0])
far = tuple(cnt[f][0])
cv.line(img,start,end,[0,255,0],2)
cv.circle(img,far,5,[0,0,255],-1)
cv.imshow('img',img)
cv.waitKey(0)
cv.destroyAllWindows()
窗口将如下图显示:

(2)点多边形测试
此功能可查找图像中的点与轮廓之间的最短距离。当点在轮廓外时返回负值,当点在内部时返回正值,如果点在轮廓上则返回零。
例如,我们可以检查点(50,50)如下:
dist = cv.pointPolygonTest(cnt,(50,50),True)
在函数中,第三个参数是measureDist。如果为True,则查找签名距离。如果为False,则查找该点是在内部还是外部或在轮廓上(它分别返回+1,-1,0)。
注意:如果你不想找到距离,请确保第三个参数为False,因为这是一个耗时的过程。因此,将其设为False可提供2-3倍的加速。
(3)匹配形状
OpenCV附带了一个函数cv.matchShapes(),它使我们能够比较两个形状或两个轮廓,并返回一个显示相似性的度量。结果越小,匹配就越好。它是根据hu-moment值计算的。文档中解释了不同的测量方法。
import cv2 as cv
import numpy as np
img1 = cv.imread('star.jpg',0)
img2 = cv.imread('star2.jpg',0)
ret, thresh = cv.threshold(img1, 127, 255,0)
ret, thresh2 = cv.threshold(img2, 127, 255,0)
im2,contours,hierarchy = cv.findContours(thresh,2,1)
cnt1 = contours[0]
im2,contours,hierarchy = cv.findContours(thresh2,2,1)
cnt2 = contours[0]
ret = cv.matchShapes(cnt1,cnt2,1,0.0)
print( ret )
我尝试匹配下面给出的不同形状的形状:

我得到了以下结果:
匹配图像A与其自身= 0.0
匹配图像A与图像B = 0.001946
匹配图像A与图像C = 0.326911
请注意,即使图像旋转对此比较也没有太大影响。
也可以看看
Hu-Moments是对翻译,旋转和缩放不变的七个时刻。第七个是偏斜不变的。可以使用cv.HuMoments()函数找到这些值。
5、轮廓层次结构
(1)理论
在最近几篇关于轮廓的文章中,我们使用了与OpenCV提供的轮廓相关的几个函数。但是当我们使用cv.findContours()函数在图像中找到轮廓时,我们已经传递了一个参数Contour Retrieval Mode。我们通常传递cv.RETR_LIST或cv.RETR_TREE,它运行的效果很好。但它究竟意味着什么?
此外,在输出中,我们得到三个数组,第一个是图像,第二个是我们的轮廓,还有一个我们命名为层次结构的输出(请查看以前文章中的代码)。但我们从未在任何地方使用过这种层那么这个层次结构又是什么呢?它与前面提到的函数参数有什么关系?
这就是我们将在本文中处理的内容。
什么是层次结构?
通常我们使用cv.findContours()函数来检测图像中的对象,对吧?有时对象位于不同的位置。但在某些情况下,某些形状在其他形状内。就像嵌套的数字一样。在这种情况下,我们将外部一个称为父项,将内部项称为子项。这样,图像中的轮廓彼此之间存在某种关系。我们可以指定一个轮廓如何相互连接,例如,它是某个其他轮廓的子项,还是父项等。这种关系的表示称为层次结构。
考虑下面的示例图片:

在这张图片中,有一些形状,我从0-5编号。图2和2a表示最外侧盒子的外部和内部轮廓。
这里,轮廓0,1,2是外部或最外部的。我们可以说,它们在层次结构0中,或者只是它们处于相同的层次结构级别。
接下来是轮廓-2a。它可以被认为是轮廓-2的子节点(或者相反,轮廓-2是轮廓-2的父节点)。所以让它在层次结构-1中。类似地,轮廓-3是轮廓-2的子,它进入下一层次。最后,轮廓4,5是轮廓-3a的子节点,它们位于最后的层次结构级别。从我编号框的方式,我会说轮廓-4是轮廓-3a的第一个孩子(它也可以是轮廓-5)。
我提到这些东西来理解相同的层次结构,外部轮廓,子轮廓,父轮廓,第一个孩子等术语。现在让我们进入OpenCV。
OpenCV中的层次结构表示
因此每个轮廓都有自己的信息,关于它是什么层次结构,谁是它的子,谁是它的父等.OpenCV将它表示为四个值的数组:[Next,Previous,First_Child,Parent]
“下一个表示同一层级的下一个轮廓。”
例如,在我们的图片中取出contour-0。谁是同一水平的下一个轮廓?它是轮廓-1。所以简单地说Next = 1.类似地,对于Contour-1,next是contour-2。所以Next = 2。
轮廓-2怎么样?同一级别没有下一个轮廓。所以简单地说,将Next = -1。轮廓-4怎么样?它与contour-5处于同一水平。所以它的下一个轮廓是轮廓-5,所以Next = 5。
“上一个表示同一层级的先前轮廓。”
与上述相同。轮廓-1的先前轮廓在同一水平面上为轮廓-0。类似地,对于轮廓-2,它是轮廓-1。而对于contour-0,没有先前的,所以把它作为-1。
“First_Child表示其第一个子轮廓。”
无需任何解释。对于轮廓-2,孩子是轮廓-2a。因此它获得了contour-2a的相应索引值。轮廓-3a怎么样?它有两个孩子。但我们只带第一个孩子。它是轮廓-4。因此,对于轮廓-3a,First_Child = 4。
“父表示其父轮廓的索引。”
它与First_Child相反。对于轮廓-4和轮廓-5,父轮廓都是轮廓-3a。对于轮廓-3a,它是轮廓-3,依此类推。
注意:如果没有子项或父项,则该字段将被视为-1
所以现在我们知道OpenCV中使用的层次结构样式,我们可以在上面给出的相同图像的帮助下检查OpenCV中的Contour Retrieval Modes。即cv.RETR_LIST,cv.RETR_TREE,cv.RETR_CCOMP,cv.RETR_EXTERNAL等标志是什么意思?
(2)轮廓检索模式
- RETR_LIST
这是四个标志中最简单的(从解释的角度来看)。它只是检索所有轮廓,但不创建任何父子关系。根据这条规则,父和子是平等的,他们只是轮廓。即它们都属于同一层次结构。
所以这里,层次结构数组中的第3和第4项始终为-1。但显然,Next和Previous术语将具有相应的值。请自行检查并验证。
下面是我得到的结果,每行是相应轮廓的层次结构细节。例如,第一行对应于轮廓0.下一个轮廓是轮廓1.所以Next = 1.没有先前的轮廓,所以Previous = -1。如前所述,剩下的两个是-1。
>>> hierarchy
array([[[ 1, -1, -1, -1],
[ 2, 0, -1, -1],
[ 3, 1, -1, -1],
[ 4, 2, -1, -1],
[ 5, 3, -1, -1],
[ 6, 4, -1, -1],
[ 7, 5, -1, -1],
[-1, 6, -1, -1]]])
如果你没有使用任何层次结构功能,这是在代码中使用的不错选择。
- RETR_EXTERNAL
如果使用此标志,则仅返回极端外部标志。所有儿童轮廓都被遗忘。我们可以说,根据这项法律,只有每个家庭中最年长的人才能得到照顾。它并不关心其他家庭成员:)。
那么,在我们的图像中,有多少极端外轮廓?即在等级0级?只有3个,即轮廓0,1,2,对吧?现在尝试使用此标志查找轮廓。这里,给予每个元素的值与上面相同。将其与上述结果进行比较。以下是我得到的:
>>> hierarchy
array([[[ 1, -1, -1, -1],
[ 2, 0, -1, -1],
[-1, 1, -1, -1]]])
如果只想提取外轮廓,可以使用此标志。在某些情况下它可能有用。
- RETR_CCOMP
此标志检索所有轮廓并将它们排列为2级层次结构。即对象的外部轮廓(即其边界)放置在层次结构-1中。对象内部的孔的轮廓(如果有的话)放在层次结构-2中。如果其中有任何对象,则其轮廓仅再次放置在层次结构-1中。它在层次结构-2中的漏洞等等。
只需考虑黑色背景上的“大白零”图像。零的外圆属于第一层次,零的内圈属于第二层次。
我们可以用简单的图像来解释它。在这里,我用红色(1或2)标记了红色轮廓的顺序和它们所属的层次结构。订单与OpenCV检测轮廓的顺序相同。

因此,考虑第一个轮廓,即轮廓-0。它是层次结构-1。它有两个孔,轮廓1和2,它们属于层次结构-2。因此对于轮廓-0,相同层级中的下一轮廓是轮廓-3。并且之前没有。它的第一个是子级是层次结构-2中的轮廓-1。它没有父级,因为它位于层次结构-1中。所以它的层次结构数组是[3,-1,1,-1]
现在采取轮廓-1。它在层次结构-2中。同一层次中的下一个(在轮廓-1的父下面)是轮廓-2。没有前一个。没有子,但父是轮廓-0。所以数组是[2,-1,-1,0]。
类似于contour-2:它在层次结构-2中。在contour-0下,同一层次中没有下一个轮廓。所以没有下一个。以前是轮廓-1。没有子,父是轮廓-0。所以数组是[-1,1,-1,0]。
轮廓-3:层次结构-1中的下一个是轮廓-5。上一个是轮廓-0。子是轮廓4而没有父。所以数组是[5,0,4,-1]。
轮廓 - 4:它在等高线3中的等级2中,并且没有兄弟。所以没有下一个,没有先前,没有子,父是轮廓-3。所以数组是[-1,-1,-1,3]。
剩下的你可以填写。这是我得到的最终答案:
>>> hierarchy
array([[[ 3, -1, 1, -1],
[ 2, -1, -1, 0],
[-1, 1, -1, 0],
[ 5, 0, 4, -1],
[-1, -1, -1, 3],
[ 7, 3, 6, -1],
[-1, -1, -1, 5],
[ 8, 5, -1, -1],
[-1, 7, -1, -1]]])
- RETR_TREE
这是最后一个人,Mr.Perfect。它检索所有轮廓并创建完整的族层次结构列表。它甚至告诉,谁是爷爷,父,子,孙子,甚至超越… ?。
例如,我拍摄了上面的图像,重写了cv.RETR_TREE的代码,根据OpenCV给出的结果重新排序轮廓并进行分析。同样,红色字母给出轮廓编号,绿色字母给出层次结构顺序。

取contour-0:它在层次结构-0中。 同一层次中的下一个轮廓是轮廓-7。没有以前的轮廓。子是轮廓-1。 没有父。 所以数组是[7,-1,1,-1]。
取等高线2:它在层次结构-1中。同一级别没有轮廓。没有前一个。子是轮廓-3。父是轮廓-1。所以数组是[-1,-1,3,1]。
剩下的,试试吧。 以下是完整的答案:
>>> hierarchy
array([[[ 7, -1, 1, -1],
[-1, -1, 2, 0],
[-1, -1, 3, 1],
[-1, -1, 4, 2],
[-1, -1, 5, 3],
[ 6, -1, -1, 4],
[-1, 5, -1, 4],
[ 8, 0, -1, -1],
[-1, 7, -1, -1]]])
十、OpenCV中的直方图
目标:
本章节你需要学习以下内容:
*使用OpenCV和Numpy函数查找直方图
*绘制直方图,使用OpenCV和Matplotlib函数
*我们将学习直方图均衡的概念,并用它来改善图像的对比度。
*我们将学习如何查找和绘制2D直方图。
*我们将学习直方图反投影。
*你将看到这些函数:cv.calcHist(),np.histogram()等
1、查找,绘图,分析
(1)理论
直方图是什么?你可以将直方图视为图形或绘图,它可以让你全面了解图像的强度分布。它是在X轴上具有像素值(范围从0到255,并非总是)的图和在Y轴上的图像中的对应像素数。
这只是理解图像的另一种方式。通过查看图像的直方图,你可以直观了解该图像的对比度,亮度,强度分布等。今天几乎所有的图像处理工具都提供了直方图的功能。以下是来自Cambridge in Color网站的图片,我建议你访问该网站了解更多详情。
你可以看到图像及其直方图。(请记住,此直方图是为灰度图像绘制的,而不是彩色图像)。直方图的左区域显示图像中较暗像素的数量,右区域显示较亮像素的数量。从直方图中,你可以看到暗区域不仅仅是更亮的区域,中间色调的数量(中间区域的像素值,比如大约127)非常少。
(2)查找直方图
现在我们知道什么是直方图,我们可以研究如何找到它。 OpenCV和Numpy都具有内置功能。在使用这些功能之前,我们需要了解与直方图相关的一些术语。
BINS:上面的直方图显示了每个像素值的像素数,即从0到255.即你需要256个值来显示上面的直方图。但是考虑一下,如果你不需要分别找到所有像素值的像素数,但像素值区间的像素数是多少呢?例如,你需要找到介于0到15之间,然后是16到31,…,240到255之间的像素数。你只需要16个值来表示直方图。这就是OpenCV教程中直方图中给出的示例。
所以你要做的只是将整个直方图分成16个子部分,每个子部分的值是其中所有像素数的总和。每个子部分称为“BIN”。在第一种情况下,bin的数量是256(每个像素一个),而在第二种情况下,它只有16. BINS由OpenCV docs中的术语histSize表示。
DIMS:这是我们收集数据的参数数量。在这种情况下,我们只收集有关一件事,强度值的数据。所以这里是1。
范围:这是你要测量的强度值范围。通常,它是[0,256],即所有强度值。
1.OpenCV中的直方图计算
所以现在我们使用cv.calcHist()函数来查找直方图。让我们熟悉一下这个函数及其参数:
cv.calcHist(images,channels,mask,histSize,ranges [,hist [,accumulate]])
- images:它是uint8或float32类型的源图像。它应该用方括号表示,即“[img]”。
- 渠道:它也在方括号中给出。它是我们计算直方图的通道索引。例如,如果输入是灰度图像,则其值为[0]。对于彩色图像,你可以通过[0],[1]或[2]分别计算蓝色,绿色或红色通道的直方图。
- 掩码:掩模图像。要查找完整图像的直方图,它将显示为“无”。但是,如果要查找图像特定区域的直方图,则必须为其创建蒙版图像并将其作为蒙版。 (稍后我会举一个例子。)
- histSize:这代表我们的BIN计数。需要在方括号中给出。对于满量程,我们通过[256]。
- 范围:这是我们的范围。通常,它是[0,256]。
那么让我们从一个示例图像开始吧。只需以灰度模式加载图像并找到其完整的直方图。
img = cv.imread('home.jpg',0)
hist = cv.calcHist([img],[0],None,[256],[0,256])
hist是256x1数组,每个值对应于该图像中具有相应像素值的像素数。
2.Numpy中的直方图计算
Numpy还为你提供了一个函数,np.histogram()。 因此,你可以尝试以下行代替calcHist()函数:
hist,bins = np.histogram(img.ravel(),256,[0,256])
hist与我们之前计算的相同。但是垃圾箱将有257个元素,因为Numpy计算垃圾箱为0-0.99,1-1.99,2-2.99等。所以最终范围是255-255.99。为了表示这一点,他们还在箱柜末尾添加256。但我们不需要256.高达255就足够了。
也可以看看
Numpy有另一个函数,np.bincount(),它比(大约10倍)np.histogram()快得多。因此,对于一维直方图,你可以更好地尝试。不要忘记在np.bincount中设置minlength = 256。例如,hist = np.bincount(img.ravel(),minlength = 256)
注意
OpenCV函数比np.histogram()快(约40倍)。所以坚持使用OpenCV功能。
现在我们应该绘制直方图,但是如何?
(3)绘制直方图
有两种方法,
- 简短方法:使用Matplotlib绘图功能
- 长路:使用OpenCV绘图功能
1.使用Matplotlib
Matplotlib附带直方图绘图功能:matplotlib.pyplot.hist()
它直接找到直方图并绘制它。你无需使用calcHist()或np.histogram()函数来查找直方图。请参阅以下代码:
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('home.jpg',0)
plt.hist(img.ravel(),256,[0,256]); plt.show()
窗口将如下图显示:

或者你可以使用matplotlib的正常图,这对BGR图有好处。 为此,你需要首先找到直方图数据。 试试以下代码:
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('home.jpg')
color = ('b','g','r')
for i,col in enumerate(color):
histr = cv.calcHist([img],[i],None,[256],[0,256])
plt.plot(histr,color = col)
plt.xlim([0,256])
plt.show()
窗口将如下图显示:
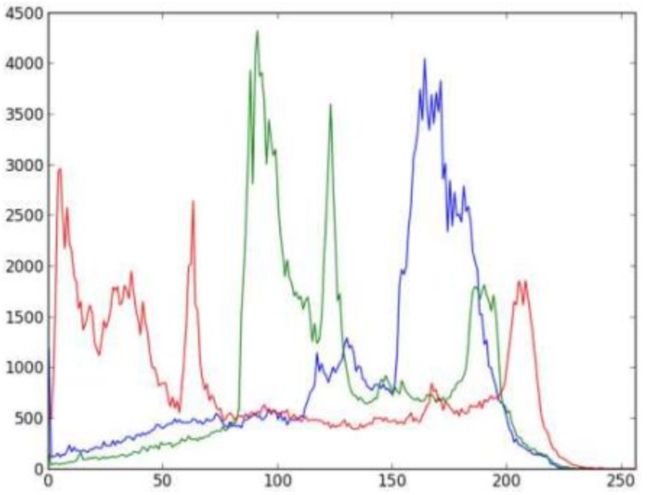
你可以从上图中扣除,蓝色在图像中有一些高值区域(显然应该是由于天空)
2.使用OpenCV
好吧,在这里你可以调整直方图的值及其bin值,使其看起来像x,y坐标,这样你就可以使用cv.line()或cv.polyline()函数绘制它,以生成与上面相同的图像。 这已经可以在OpenCV-Python2官方样本中找到。 检查samples / python / hist.py上的代码。
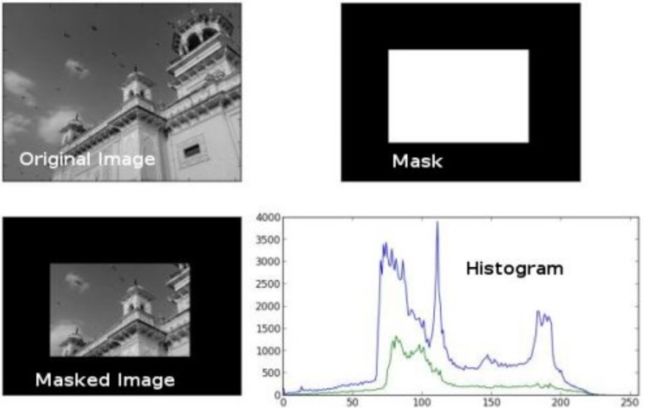
(4)面膜的应用
我们使用cv.calcHist()来查找完整图像的直方图。 如果要查找图像某些区域的直方图,该怎么办? 只需在要查找直方图的区域上创建一个白色的蒙版图像,否则创建黑色。 然后将其作为掩码传递。
img = cv.imread('home.jpg',0)
# create a mask
mask = np.zeros(img.shape[:2], np.uint8)
mask[100:300, 100:400] = 255
masked_img = cv.bitwise_and(img,img,mask = mask)
# Calculate histogram with mask and without mask
# Check third argument for mask
hist_full = cv.calcHist([img],[0],None,[256],[0,256])
hist_mask = cv.calcHist([img],[0],mask,[256],[0,256])
plt.subplot(221), plt.imshow(img, 'gray')
plt.subplot(222), plt.imshow(mask,'gray')
plt.subplot(223), plt.imshow(masked_img, 'gray')
plt.subplot(224), plt.plot(hist_full), plt.plot(hist_mask)
plt.xlim([0,256])
plt.show()
看到结果。 在直方图中,蓝线显示完整图像的直方图,而绿线显示屏蔽区域的直方图。
2、直方图均衡
(1)理论
考虑一个像素值仅限于某些特定值范围的图像。 例如,较亮的图像将所有像素限制为高值。 但是,良好的图像将具有来自图像的所有区域的像素。 所以你需要将这个直方图拉伸到两端(如下图所示,来自维基百科),这就是直方图均衡所做的(简单来说)。 这通常可以改善图像的对比度。

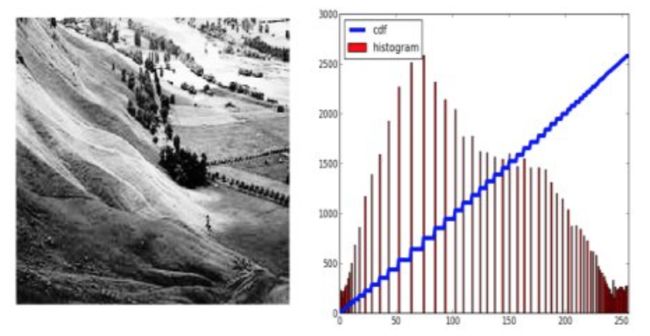
我建议你阅读直方图均衡的维基百科页面,了解更多相关细节。 它有一个非常好的解释和解决的例子,所以你在阅读之后几乎可以理解所有内容。 相反,在这里我们将看到它的Numpy实现。 之后,我们将看到OpenCV功能。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('wiki.jpg',0)
hist,bins = np.histogram(img.flatten(),256,[0,256])
cdf = hist.cumsum()
cdf_normalized = cdf * float(hist.max()) / cdf.max()
plt.plot(cdf_normalized, color = 'b')
plt.hist(img.flatten(),256,[0,256], color = 'r')
plt.xlim([0,256])
plt.legend(('cdf','histogram'), loc = 'upper left')
plt.show()

你可以看到直方图位于更亮的区域。 我们需要全谱。 为此,我们需要一个转换函数,它将较亮区域中的输入像素映射到整个区域中的输出像素。 这就是直方图均衡所做的。
现在我们找到最小直方图值(不包括0)并应用维基页面中给出的直方图均衡化方程。 但我在这里使用了Numpy的蒙面数组概念数组。 对于掩码数组,所有操作都在非掩码元素上执行。 你可以从屏蔽数组上的Numpy docs中了解更多相关信息。
cdf_m = np.ma.masked_equal(cdf,0)
cdf_m = (cdf_m - cdf_m.min())*255/(cdf_m.max()-cdf_m.min())
cdf = np.ma.filled(cdf_m,0).astype('uint8')
现在我们有一个查找表,它为我们提供了每个输入像素值的输出像素值的信息。 所以我们只应用变换。
img2 = cdf[img]
现在我们像以前一样计算它的直方图和cdf(你这样做),结果如下所示:
另一个重要特征是,即使图像是较暗的图像(而不是我们使用的更亮的图像),在均衡后我们将得到几乎与我们相同的图像。 结果,这被用作“参考工具”以使所有图像具有相同的照明条件。 这在许多情况下很有用。 例如,在面部识别中,在训练面部数据之前,将面部图像均衡化以使它们全部具有相同的照明条件。
(2)OpenCV中的直方图均衡
OpenCV有一个函数来执行此操作,cv.equalizeHist()。 它的输入只是灰度图像,输出是我们的直方图均衡图像。
下面是一个简单的代码段,显示了我们使用的相同图像的用法:
img = cv.imread('wiki.jpg',0)
equ = cv.equalizeHist(img)
res = np.hstack((img,equ)) #stacking images side-by-side
cv.imwrite('res.png',res)
所以现在你可以拍摄不同光线条件的不同图像,均衡它并检查结果。
当图像的直方图被限制在特定区域时,直方图均衡是好的。 在直方图覆盖大区域的强度变化较大的地方,即存在亮像素和暗像素时,它将无法正常工作。 请查看其他资源中的SOF链接。

(3)CLAHE(对比度有限自适应直方图均衡)
我们刚看到的第一个直方图均衡,考虑了图像的全局对比度。 在许多情况下,这不是一个好主意。 例如,下图显示了全局直方图均衡后的输入图像及其结果。

确实,直方图均衡后背景对比度有所改善。但比较两个图像中的雕像的脸。由于亮度过高,我们丢失了大部分信息。这是因为它的直方图并不局限于特定区域,正如我们在之前的案例中看到的那样(尝试绘制输入图像的直方图,你将获得更多的直觉)。
因此,为了解决这个问题,使用自适应直方图均衡。在此,图像被分成称为“图块”的小块(在OpenCV中,tileSize默认为8x8)。然后像往常一样对这些块中的每一个进行直方图均衡。所以在一个小区域内,直方图会限制在一个小区域(除非有噪音)。如果有噪音,它会被放大。为避免这种情况,应用对比度限制。如果任何直方图区间高于指定的对比度限制(在OpenCV中默认为40),则在应用直方图均衡之前,将这些像素剪切并均匀分布到其他区间。均衡后,为了去除图块边框中的瑕疵,应用双线性插值。
下面的代码片段显示了如何在OpenCV中应用CLAHE:
import numpy as np
import cv2 as cv
img = cv.imread('tsukuba_l.png',0)
# create a CLAHE object (Arguments are optional).
clahe = cv.createCLAHE(clipLimit=2.0, tileGridSize=(8,8))
cl1 = clahe.apply(img)
cv.imwrite('clahe_2.jpg',cl1)
查看下面的结果并将其与上面的结果进行比较,尤其是雕像区域:

3、2D直方图
(1)介绍
在第一篇文章中,我们计算并绘制了一维直方图。 它被称为一维,因为我们只考虑一个特征,即像素的灰度强度值。 但在二维直方图中,你考虑两个特征。 通常,它用于查找颜色直方图,其中两个要素是每个像素的色调和饱和度值。
有一个python样本(samples / python / color_histogram.py)已经用于查找颜色直方图。 我们将尝试了解如何创建这样的颜色直方图,它将有助于理解直方图反投影等其他主题。
(2)OpenCV中的2D直方图
它很简单,使用相同的函数cv.calcHist()计算。 对于颜色直方图,我们需要将图像从BGR转换为HSV。 (请记住,对于1D直方图,我们从BGR转换为灰度)。 对于2D直方图,其参数将修改如下:
- channels = [0,1]因为我们需要处理H和S平面。
- b = H平面为[180,256] 180,S平面为256。
- range = [0,180,0,256] Hue值介于0和180之间,饱和度介于0和256之间。
现在检查以下代码:
import numpy as np
import cv2 as cv
img = cv.imread('home.jpg')
hsv = cv.cvtColor(img,cv.COLOR_BGR2HSV)
hist = cv.calcHist([hsv], [0, 1], None, [180, 256], [0, 180, 0, 256])
(3)Numpy中的2D直方图
Numpy还为此提供了一个特定的功能:np.histogram2d()。 (请记住,对于1D直方图,我们使用np.histogram())。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('home.jpg')
hsv = cv.cvtColor(img,cv.COLOR_BGR2HSV)
hist, xbins, ybins = np.histogram2d(h.ravel(),s.ravel(),[180,256],[[0,180],[0,256]])
第一个参数是H平面,第二个是S平面,第三个是每个箱子的数量,第四个是它们的范围。
现在我们可以检查如何绘制这种颜色直方图。
(4)绘制2D直方图
方法 - 1:使用cv.imshow()
我们得到的结果是一个大小为180x256的二维数组。 因此我们可以像使用cv.imshow()函数一样正常显示它们。 它将是一个灰度图像,除非你知道不同颜色的色调值,否则它不会过多地了解那里的颜色。
方法-2:使用Matplotlib
我们可以使用matplotlib.pyplot.imshow()函数绘制具有不同颜色图的2D直方图。 它让我们更好地了解不同的像素密度。 但是,除非你知道不同颜色的色调值,否则这也不会让我们知道第一眼看到的是什么颜色。 我还是喜欢这种方法。 它简单而且更好。
注意:在使用此功能时,请记住,插值标志应该最接近以获得更好的结果。
考虑代码:
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('home.jpg')
hsv = cv.cvtColor(img,cv.COLOR_BGR2HSV)
hist = cv.calcHist( [hsv], [0, 1], None, [180, 256], [0, 180, 0, 256] )
plt.imshow(hist,interpolation = 'nearest')
plt.show()
下面是输入图像及其颜色直方图。 X轴显示S值,Y轴显示Hue。

在直方图中,你可以看到H = 100和S = 200附近的一些高值。它对应于天空的蓝色。 类似地,在H = 25和S = 100附近可以看到另一个峰值。它对应于宫殿的黄色。 你可以使用任何图像编辑工具(如GIMP)对其进行验证。
方法3:OpenCV样本风格!!
在OpenCV-Python2样本中有一个颜色直方图的示例代码(samples / python / color_histogram.py)。 如果运行代码,则可以看到直方图也显示相应的颜色。 或者只是输出颜色编码的直方图。 它的结果非常好(虽然你需要添加额外的一堆线)。
在该代码中,作者在HSV中创建了一个颜色映射。 然后将其转换为BGR。 得到的直方图图像与该颜色图相乘。 他还使用一些预处理步骤来移除小的孤立像素,从而产生良好的直方图。
我把它留给读者来运行代码,分析它并拥有自己的hack arounds。 以下是与上述相同图像的代码输出:
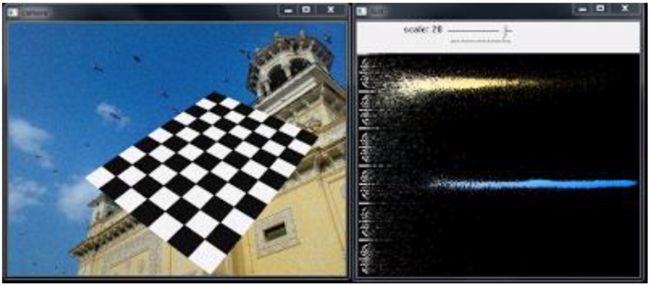
你可以在直方图中清楚地看到存在哪些颜色,蓝色存在,黄色存在,并且由于棋盘存在一些白色。 很好!!!
4、直方图反投影
(1)理论
它由Michael J. Swain,Dana H. Ballard在他们的论文“通过颜色直方图索引”中提出。
用简单的词语实际上是什么?它用于图像分割或查找图像中感兴趣的对象。简单来说,它会创建一个与输入图像大小相同(但是单个通道)的图像,其中每个像素对应于该像素属于我们对象的概率。在更简单的世界中,与剩余部分相比,输出图像将使我们感兴趣的对象更白。嗯,这是一个直观的解释。 (我不能让它变得更简单)。直方图反投影与camshift算法等一起使用。
我们该怎么做呢 ?我们创建一个包含我们感兴趣对象的图像的直方图(在我们的例子中,是地面,离开玩家和其他东西)。对象应尽可能填充图像以获得更好的结果。并且颜色直方图优于灰度直方图,因为对象的颜色是比其灰度强度更好的定义对象的方式。然后我们将这个直方图“反投影”到我们需要找到对象的测试图像上,换句话说,我们计算每个像素属于地面并显示它的概率。通过适当的阈值处理得到的输出为我们提供了基础。
(2)Numpy中的算法
- 首先,我们需要计算我们需要找到的对象(让它为’M’)和我们要搜索的图像(让它为’我’)的颜色直方图。
import numpy as np
import cv2 as cvfrom matplotlib import pyplot as plt
#roi is the object or region of object we need to find
roi = cv.imread('rose_red.png')
hsv = cv.cvtColor(roi,cv.COLOR_BGR2HSV)
#target is the image we search in
target = cv.imread('rose.png')
hsvt = cv.cvtColor(target,cv.COLOR_BGR2HSV)
# Find the histograms using calcHist. Can be done with np.histogram2d also
M = cv.calcHist([hsv],[0, 1], None, [180, 256], [0, 180, 0, 256] )
I = cv.calcHist([hsvt],[0, 1], None, [180, 256], [0, 180, 0, 256] )
- 求出比率 R = M I R=\frac{M}{I} R=IM。然后反投影R,即使用R作为调色板并创建一个新图像,每个像素作为其对应的目标概率。 即B(x,y)= R[h(x,y),s(x,y)]其中h是色调,s是(x,y)处像素的饱和度。 之后应用条件B(x,y)= min [B(x,y),1]。
h,s,v = cv.split(hsvt)
B = R[h.ravel(),s.ravel()]
B = np.minimum(B,1)
B = B.reshape(hsvt.shape[:2])
- 现在应用圆盘的卷积,B = D * B,其中D是盘卷积核。
disc = cv.getStructuringElement(cv.MORPH_ELLIPSE,(5,5))
cv.filter2D(B,-1,disc,B)
B = np.uint8(B)
cv.normalize(B,B,0,255,cv.NORM_MINMAX)
- 现在最大强度的位置为我们提供了物体的位置。 如果我们期望图像中有一个区域,那么对适当值进行阈值处理会得到很好的结果。
ret,thresh = cv.threshold(B,50,255,0)
(3)OpenCV中的反投影
OpenCV提供了一个内置函数cv.calcBackProject()。 它的参数与cv.calcHist()函数几乎相同。 它的一个参数是直方图,它是对象的直方图,我们必须找到它。 此外,在传递给backproject函数之前,应该对象直方图进行规范化。 它返回概率图像。 然后我们将图像与光盘卷积核卷积并应用阈值。 以下是我的代码和输出:
import numpy as np
import cv2 as cv
roi = cv.imread('rose_red.png')
hsv = cv.cvtColor(roi,cv.COLOR_BGR2HSV)
target = cv.imread('rose.png')
hsvt = cv.cvtColor(target,cv.COLOR_BGR2HSV)
# calculating object histogram
roihist = cv.calcHist([hsv],[0, 1], None, [180, 256], [0, 180, 0, 256] )
# normalize histogram and apply backprojection
cv.normalize(roihist,roihist,0,255,cv.NORM_MINMAX)
dst = cv.calcBackProject([hsvt],[0,1],roihist,[0,180,0,256],1)
# Now convolute with circular disc
disc = cv.getStructuringElement(cv.MORPH_ELLIPSE,(5,5))
cv.filter2D(dst,-1,disc,dst)
# threshold and binary AND
ret,thresh = cv.threshold(dst,50,255,0)
thresh = cv.merge((thresh,thresh,thresh))
res = cv.bitwise_and(target,thresh)
res = np.vstack((target,thresh,res))
cv.imwrite('res.jpg',res)
以下是我合作过的一个例子。 我使用蓝色矩形内的区域作为样本对象,我想提取完整的地面。
十一、傅立叶变换
目标:
本章节你需要学习以下内容:
*使用OpenCV查找图像的傅立叶变换
*使用Numpy中提供的FFT函数
*傅立叶变换的一些应用
*我们将看到以下函数:cv.dft(),cv.idft()等
1、理论
傅立叶变换用于分析各种滤波器的频率特性。对于图像,2D离散傅里叶变换(DFT)用于找到频域。称为快速傅里叶变换(FFT)的快速算法用于计算DFT。有关这些的详细信息可以在任何图像处理或信号处理教科书中找到。请参阅其他资源部分。
对于正弦信号,x(t)= Asin(2πft),我们可以说f是信号的频率,如果采用其频域,我们可以看到f处的尖峰。如果对信号进行采样以形成离散信号,则我们得到相同的频域,但在[-π,π]或[0,2π](或对于N点DFT的[0,N])范围内是周期性的。你可以将图像视为在两个方向上采样的信号。因此,在X和Y方向上进行傅里叶变换可以得到图像的频率表示。
更直观地说,对于正弦信号,如果幅度在短时间内变化如此之快,则可以说它是高频信号。如果变化缓慢,则为低频信号。你可以将相同的想法扩展到图像。幅度在图像中的幅度变化很大?在边缘点,或噪音。我们可以说,边缘和噪声是图像中的高频内容。如果幅度没有太大变化,则它是低频分量。 (一些链接被添加到Additional Resources_,它通过示例直观地解释了频率变换)。
现在我们将看到如何找到傅立叶变换。
2、Numpy中的傅里叶变换
首先,我们将看到如何使用Numpy找到傅立叶变换。Numpy有一个FFT包来做到这一点。np.fft.fft2()为我们提供了一个复杂数组的频率变换。它的第一个参数是输入图像,它是灰度。第二个参数是可选的,它决定了输出数组的大小。如果它大于输入图像的大小,则在计算FFT之前用零填充输入图像。如果小于输入图像,则将裁剪输入图像。如果没有传递参数,则输出数组大小将与输入相同。
现在,一旦得到结果,零频率分量(DC分量)将位于左上角。如果要将其置于中心位置,则需要在两个方向上将结果移动 N 2 \frac{N}{2} 2N。这只是通过函数np.fft.fftshift()完成的。 (分析更容易)。找到频率变换后,你可以找到幅度谱。
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('messi5.jpg',0)
f = np.fft.fft2(img)
fshift = np.fft.fftshift(f)
magnitude_spectrum = 20*np.log(np.abs(fshift))
plt.subplot(121),plt.imshow(img, cmap = 'gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(magnitude_spectrum, cmap = 'gray')
plt.title('Magnitude Spectrum'), plt.xticks([]), plt.yticks([])
plt.show()
窗口将如下图显示:

请注意,你可以在中心看到更多更白的区域,显示低频内容更多。
所以你找到了频率变换现在你可以在频域做一些操作,比如高通滤波和重建图像,即找到逆DFT。 为此,你只需通过使用尺寸为60x60的矩形窗口进行遮罩来移除低频。 然后使用np.fft.ifftshift()应用反向移位,以便DC组件再次出现在左上角。 然后使用np.ifft2()函数找到逆FFT。 结果再次是一个复杂的数字。 你可以采取它的绝对价值。
rows, cols = img.shape
crow,ccol = rows/2 , cols/2
fshift[crow-30:crow+30, ccol-30:ccol+30] = 0
f_ishift = np.fft.ifftshift(fshift)
img_back = np.fft.ifft2(f_ishift)
img_back = np.abs(img_back)
plt.subplot(131),plt.imshow(img, cmap = 'gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(132),plt.imshow(img_back, cmap = 'gray')
plt.title('Image after HPF'), plt.xticks([]), plt.yticks([])
plt.subplot(133),plt.imshow(img_back)
plt.title('Result in JET'), plt.xticks([]), plt.yticks([])
plt.show()
窗口将如下图显示:

结果显示高通滤波是边缘检测操作。这是我们在Image Gradients章节中看到的。这也表明大多数图像数据存在于光谱的低频区域。无论如何,我们已经看到如何在Numpy中找到DFT,IDFT等。现在让我们看看如何在OpenCV中完成它。
如果你仔细观察结果,特别是JET颜色的最后一个图像,你可以看到一些文物(我用红色箭头标记的一个实例)。它在那里显示出一些类似波纹的结构,它被称为振铃效应。它是由我们用于遮蔽的矩形窗口引起的。此蒙版转换为sinc形状,这会导致此问题。因此矩形窗口不用于过滤。更好的选择是高斯Windows。
3、OpenCV中的傅里叶变换
OpenCV为此提供了cv.dft()和cv.idft()函数。它返回与之前相同的结果,但有两个通道。第一个通道将具有结果的实部,第二个通道将具有结果的虚部。输入图像应首先转换为np.float32。我们将看到如何做到这一点。
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('messi5.jpg',0)
dft = cv.dft(np.float32(img),flags = cv.DFT_COMPLEX_OUTPUT)
dft_shift = np.fft.fftshift(dft)
magnitude_spectrum = 20*np.log(cv.magnitude(dft_shift[:,:,0],dft_shift[:,:,1]))
plt.subplot(121),plt.imshow(img, cmap = 'gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(magnitude_spectrum, cmap = 'gray')
plt.title('Magnitude Spectrum'), plt.xticks([]), plt.yticks([])
plt.show()
注意:你还可以使用cv.cartToPolar(),它可以一次性返回幅度和相位
所以,现在我们必须进行逆DFT。 在之前的会话中,我们创建了一个HPF,这次我们将看到如何去除图像中的高频内容,即我们将LPF应用于图像。 它实际上模糊了图像。 为此,我们首先在低频处创建具有高值(1)的掩模,即我们传递LF内容,并且在HF区域传递0。
rows, cols = img.shape
crow,ccol = rows/2 , cols/2
# create a mask first, center square is 1, remaining all zeros
mask = np.zeros((rows,cols,2),np.uint8)
mask[crow-30:crow+30, ccol-30:ccol+30] = 1
# apply mask and inverse DFT
fshift = dft_shift*mask
f_ishift = np.fft.ifftshift(fshift)
img_back = cv.idft(f_ishift)
img_back = cv.magnitude(img_back[:,:,0],img_back[:,:,1])
plt.subplot(121),plt.imshow(img, cmap = 'gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(img_back, cmap = 'gray')
plt.title('Magnitude Spectrum'), plt.xticks([]), plt.yticks([])
plt.show()
窗口将如下图显示:

注意:像往常一样,OpenCV函数cv.dft()和cv.idft()比Numpy函数更快。 但是Numpy功能更加用户友好。 有关性能问题的更多详细信息,请参阅以下部分。
4、DFT的性能优化
对于某些阵列大小,DFT计算的性能更好。 当阵列大小为2的幂时,它是最快的。 尺寸为2,3和5的乘积的阵列也可以非常有效地处理。 因此,如果你担心代码的性能,可以在找到DFT之前将数组的大小修改为任何最佳大小(通过填充零)。 对于OpenCV,你必须手动填充零。 但对于Numpy,你可以指定FFT计算的新大小,它会自动为你填充零。
那么我们如何找到这个最佳尺寸? OpenCV为此提供了一个函数cv.getOptimalDFTSize()。 它适用于cv.dft()和np.fft.fft2()。 让我们使用IPython magic命令timeit检查它们的性能。
In [16]: img = cv.imread('messi5.jpg',0)
In [17]: rows,cols = img.shape
In [18]: print("{} {}".format(rows,cols))
342 548
In [19]: nrows = cv.getOptimalDFTSize(rows)
In [20]: ncols = cv.getOptimalDFTSize(cols)
In [21]: print("{} {}".format(nrows,ncols))
360 576
看,大小(342,548)被修改为(360,576)。 现在让我们用零填充它(对于OpenCV)并找到它们的DFT计算性能。 你可以通过创建一个新的大零数组并将数据复制到它,或使用cv.copyMakeBorder()来实现。
nimg = np.zeros((nrows,ncols))
nimg[:rows,:cols] = img
或者
right = ncols - cols
bottom = nrows - rows
bordertype = cv.BORDER_CONSTANT #just to avoid line breakup in PDF file
nimg = cv.copyMakeBorder(img,0,bottom,0,right,bordertype, value = 0)
现在我们计算Numpy函数的DFT性能比较:
In [22]: %timeit fft1 = np.fft.fft2(img)
10 loops, best of 3: 40.9 ms per loop
In [23]: %timeit fft2 = np.fft.fft2(img,[nrows,ncols])
100 loops, best of 3: 10.4 ms per loop
它显示了4倍的加速。现在我们将尝试使用OpenCV函数。
In [24]: %timeit dft1= cv.dft(np.float32(img),flags=cv.DFT_COMPLEX_OUTPUT)
100 loops, best of 3: 13.5 ms per loop
In [27]: %timeit dft2= cv.dft(np.float32(nimg),flags=cv.DFT_COMPLEX_OUTPUT)
100 loops, best of 3: 3.11 ms per loop
它还显示了4倍的加速。 你还可以看到OpenCV函数比Numpy函数快3倍。这也可以进行逆FFT测试,这可以作为练习。
4、为什么拉普拉斯算子是高通滤波器?
在论坛中提出了类似的问题。 问题是,为什么拉普拉斯算子是高通滤波器? 为什么Sobel是HPF? 第一个答案就是傅立叶变换。 只需将拉普拉斯算子的傅里叶变换用于更高尺寸的FFT。 分析一下:
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
# simple averaging filter without scaling parameter
mean_filter = np.ones((3,3))
# creating a gaussian filter
x = cv.getGaussianKernel(5,10)
gaussian = x*x.T
# different edge detecting filters
# scharr in x-direction
scharr = np.array([[-3, 0, 3],
[-10,0,10],
[-3, 0, 3]])
# sobel in x direction
sobel_x= np.array([[-1, 0, 1],
[-2, 0, 2],
[-1, 0, 1]])
# sobel in y direction
sobel_y= np.array([[-1,-2,-1],
[0, 0, 0],
[1, 2, 1]])
# laplacian
laplacian=np.array([[0, 1, 0],
[1,-4, 1],
[0, 1, 0]])
filters = [mean_filter, gaussian, laplacian, sobel_x, sobel_y, scharr]
filter_name = ['mean_filter', 'gaussian','laplacian', 'sobel_x', \
'sobel_y', 'scharr_x']
fft_filters = [np.fft.fft2(x) for x in filters]
fft_shift = [np.fft.fftshift(y) for y in fft_filters]
mag_spectrum = [np.log(np.abs(z)+1) for z in fft_shift]
for i in xrange(6):
plt.subplot(2,3,i+1),plt.imshow(mag_spectrum[i],cmap = 'gray')
plt.title(filter_name[i]), plt.xticks([]), plt.yticks([])
plt.show()
窗口将如下图显示:

十二、模板匹配
目标:
本章节你需要学习以下内容:
*使用模板匹配查找图像中的对象
*你将看到以下函数:cv.matchTemplate(),cv.minMaxLoc()
1、理论
模板匹配是一种在较大图像中搜索和查找模板图像位置的方法。为此,OpenCV附带了一个函数cv.matchTemplate()。它只是在输入图像上滑动模板图像(如在2D卷积中),并比较模板图像下的输入图像的模板和补丁。在OpenCV中实现了几种比较方法。 (你可以查看文档以获取更多详细信息)。它返回一个灰度图像,其中每个像素表示该像素的邻域与模板匹配的程度。
如果输入图像的大小(WxH)且模板图像的大小(wxh),则输出图像的大小为(W-w + 1,H-h + 1)。获得结果后,可以使用cv.minMaxLoc()函数查找最大/最小值的位置。将其作为矩形的左上角,并将(w,h)作为矩形的宽度和高度。那个矩形是你的模板区域。
注意:如果你使用cv.TM_SQDIFF作为比较方法,则最小值会给出最佳匹配。
2、OpenCV中的模板匹配
在这里,作为一个例子,我们将在他的照片中搜索梅西的脸。所以我创建了一个模板如下:

我们将尝试所有比较方法,以便我们可以看到它们的结果如何:
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('messi5.jpg',0)
img2 = img.copy()
template = cv.imread('template.jpg',0)
w, h = template.shape[::-1]
# All the 6 methods for comparison in a list
methods = ['cv.TM_CCOEFF', 'cv.TM_CCOEFF_NORMED', 'cv.TM_CCORR',
'cv.TM_CCORR_NORMED', 'cv.TM_SQDIFF', 'cv.TM_SQDIFF_NORMED']
for meth in methods:
img = img2.copy()
method = eval(meth)
# Apply template Matching
res = cv.matchTemplate(img,template,method)
min_val, max_val, min_loc, max_loc = cv.minMaxLoc(res)
# If the method is TM_SQDIFF or TM_SQDIFF_NORMED, take minimum
if method in [cv.TM_SQDIFF, cv.TM_SQDIFF_NORMED]:
top_left = min_loc
else:
top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
cv.rectangle(img,top_left, bottom_right, 255, 2)
plt.subplot(121),plt.imshow(res,cmap = 'gray')
plt.title('Matching Result'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(img,cmap = 'gray')
plt.title('Detected Point'), plt.xticks([]), plt.yticks([])
plt.suptitle(meth)
plt.show()
请参阅以下结果:
- cv.TM_CCOEFF

- cv.TM_CCOEFF_NORMED

- cv.TM_CCORR

- cv.TM_CCOEFF_NORMED

- cv.TM_SQDIFF

- cv.TM_SQDIFF_NORMED

你可以看到使用cv.TM_CCORR的结果不如我们预期的那样好。
3、与多个对象匹配的模板
在上一节中,我们搜索了Messi脸部的图像,该图像仅在图像中出现一次。 假设你正在搜索多次出现的对象,cv.minMaxLoc()将不会为你提供所有位置。 在这种情况下,我们将使用阈值。 所以在这个例子中,我们将使用着名游戏Mario的截图,我们将在其中找到硬币。
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img_rgb = cv.imread('mario.png')
img_gray = cv.cvtColor(img_rgb, cv.COLOR_BGR2GRAY)
template = cv.imread('mario_coin.png',0)
w, h = template.shape[::-1]
res = cv.matchTemplate(img_gray,template,cv.TM_CCOEFF_NORMED)
threshold = 0.8
loc = np.where( res >= threshold)
for pt in zip(*loc[::-1]):
cv.rectangle(img_rgb, pt, (pt[0] + w, pt[1] + h), (0,0,255), 2)
cv.imwrite('res.png',img_rgb)
窗口将如下图显示:
十三、霍夫线变换
目标:
本章节你需要学习以下内容:
*我们将理解霍夫变换的概念。
*我们将看到如何使用它来检测图像中的线条。
*我们将看到以下函数:cv.HoughLines(),cv.HoughLinesP()
1、理论
如果你能够以数学形式表示该形状,则霍夫变换是一种检测任何形状的流行技术。它可以检测形状,即使它被破坏或扭曲一点点。我们将看到它如何适用于生产线。
线可以表示为 y = m x + c y=mx+c y=mx+c或以参数形式表示为 ρ = x c o s θ + y s i n θ \rho =x\ cos\theta +y\ sin\theta ρ=x cosθ+y sinθ其中 ρ \rho ρ是从原点到线的垂直距离, θ \theta θ是由该垂直线和水平轴形成的角度 以逆时针方向测量(该方向因你表示坐标系的方式而异。此表示在OpenCV中使用)。检查下图:
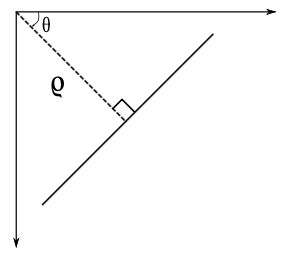
因此,如果线在原点以下通过,它将具有正rho和小于180的角度。如果它超过原点,而不是采用大于180的角度,则角度小于180,并且rho被认为是否定的。任何垂直线都有0度,水平线有90度。
现在让我们看看霍夫变换如何为线条工作。任何线都可以用这两个术语表示, ( ρ , θ ) \left ( \rho ,\theta \right ) (ρ,θ)。因此,首先它创建一个2D数组或累加器(以保存两个参数的值),并且最初设置为0。令行表示 ρ \rho ρ,列表示 θ \theta θ。阵列的大小取决于你需要的准确度。假设你希望角度精度为1度,则需要180列。对于 ρ \rho ρ,可能的最大距离是图像的对角线长度。因此,取一个像素精度,行数可以是图像的对角线长度。
考虑一个100x100的图像,中间有一条水平线。取第一点。你知道它的(x,y)值。现在在线方程中,将值 θ = 0 , 1 , 2 , ⋯ , 180 \theta= 0,1,2,\cdots ,180 θ=0,1,2,⋯,180并检查你得到的 ρ \rho ρ。对于每个 ( ρ , θ ) \left ( \rho ,\theta \right ) (ρ,θ)对,在我们的累加器中将其在相应的 ( ρ , θ ) \left ( \rho ,\theta \right ) (ρ,θ)单元格中增加1。所以现在在累加器中,单元格(50,90)= 1以及其他一些单元格。
现在取第二点就行了。和上面一样。增加与你获得的(rho,theta)对应的单元格中的值。这次,单元格(50,90)= 2.你实际做的是投票给 ( ρ , θ ) \left ( \rho ,\theta \right ) (ρ,θ)值。你可以继续执行此过程中的每个点。在每个点,单元格(50,90)将递增或投票,而其他单元格可能会或可能不会被投票。这样,最后,单元格(50,90)将获得最大票数。因此,如果你在累加器中搜索最大投票数,则会得到值(50,90),表示此图像中距离原点和角度为90度的距离为50。它在下面的动画中有很好的展示(图片提供:Amos Storkey)

这就是霍夫变换对线条的作用。 它很简单,也许你可以自己使用Numpy来实现它。 下面是显示累加器的图像。 某些位置的亮点表示它们是图像中可能线条的参数。 (图片提供:维基百科)

2、OpenCV中的霍夫变换
上面解释的所有内容都封装在OpenCV函数cv.HoughLines()中。 它只返回一个数组:math:(rho,theta)`values。 ρ \rho ρ以像素为单位测量, θ \theta θ以弧度为单位测量。第一个参数,输入图像应该是二进制图像,因此在应用霍夫变换之前应用阈值或使用精确边缘检测。 第二和第三参数分别是 ρ \rho ρ和 θ \theta θ精度。第四个参数是阈值,这意味着它应该被视为一条线的最小投票。请记住,投票数取决于该线上的点数。因此它表示应检测的最小行长度。
import cv2 as cv
import numpy as np
img = cv.imread('../data/sudoku.png')
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
edges = cv.Canny(gray,50,150,apertureSize = 3)
lines = cv.HoughLines(edges,1,np.pi/180,200)
for line in lines:
rho,theta = line[0]
a = np.cos(theta)
b = np.sin(theta)
x0 = a*rho
y0 = b*rho
x1 = int(x0 + 1000*(-b))
y1 = int(y0 + 1000*(a))
x2 = int(x0 - 1000*(-b))
y2 = int(y0 - 1000*(a))
cv.line(img,(x1,y1),(x2,y2),(0,0,255),2)
cv.imwrite('houghlines3.jpg',img)
窗口将如下图显示:

3、概率Hough变换
在霍夫变换中,你可以看到即使对于具有两个参数的行,也需要大量计算。概率Hough变换是我们看到的Hough变换的优化。它没有考虑所有要点。相反,它只需要一个足以进行线检测的随机点子集。我们必须降低门槛。 请参见下图,其中比较霍夫空间中的霍夫变换和概率霍夫变换。(图片提供:Franck Bettinger的主页)

OpenCV实现基于使用Matas,J。和Galambos,C。和Kittler,J.V。[122]的渐进概率Hough变换的线的鲁棒检测。 使用的函数是cv.HoughLinesP()。 它有两个新的论点。
- minLineLength - 最小线长。 短于此的线段将被拒绝。
- maxLineGap - 线段之间允许的最大间隙,将它们视为一条线。
最好的是,它直接返回行的两个端点。在前面的例子中,你只得到了行的参数,你必须找到所有的点。在这里,一切都是直接而简单的。
import cv2 as cv
import numpy as np
img = cv.imread('../data/sudoku.png')
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
edges = cv.Canny(gray,50,150,apertureSize = 3)
lines = cv.HoughLinesP(edges,1,np.pi/180,100,minLineLength=100,maxLineGap=10)
for line in lines:
x1,y1,x2,y2 = line[0]
cv.line(img,(x1,y1),(x2,y2),(0,255,0),2)
cv.imwrite('houghlines5.jpg',img)
窗口将如下图显示:

十四、霍夫圆变换
目标:
本章节你需要学习以下内容:
*我们将学习使用Hough变换来查找图像中的圆圈。
*我们将看到这些函数:cv.HoughCircles()
理论
圆圈在数学上表示为 ( x − x c e n t e r ) 2 + ( y − y c e n t e r ) 2 = r 2 \left ( x-x_{center} \right )^{2}+\left ( y-y_{center} \right )^{2}=r^{2} (x−xcenter)2+(y−ycenter)2=r2其中 ( x c e n t e r , y c e n t e r ) \left ( x_{center},y_{center} \right ) (xcenter,ycenter)是圆的中心,r是圆的半径。从等式中,我们可以看到我们有3个参数,因此我们需要一个用于霍夫变换的3D累加器,这将非常无效。 因此,OpenCV使用更棘手的方法,Hough Gradient Method,它使用边缘的梯度信息。
我们在这里使用的函数是cv.HoughCircles()。它有很多论据,在文档中有很好的解释。所以我们直接转到代码。
import numpy as np
import cv2 as cv
img = cv.imread('opencv-logo-white.png',0)
img = cv.medianBlur(img,5)
cimg = cv.cvtColor(img,cv.COLOR_GRAY2BGR)
circles = cv.HoughCircles(img,cv.HOUGH_GRADIENT,1,20,
param1=50,param2=30,minRadius=0,maxRadius=0)
circles = np.uint16(np.around(circles))
for i in circles[0,:]:
# draw the outer circle
cv.circle(cimg,(i[0],i[1]),i[2],(0,255,0),2)
# draw the center of the circle
cv.circle(cimg,(i[0],i[1]),2,(0,0,255),3)
cv.imshow('detected circles',cimg)
cv.waitKey(0)
cv.destroyAllWindows()
窗口将如下图显示:

十五、基于分水岭算法的图像分割
目标:
本章节你需要学习以下内容:
*我们将学习使用分水岭算法使用基于标记的图像分割
*我们将看到:cv.watershed()
1、理论
任何灰度图像都可以看作是地形表面,其中高强度表示峰和丘陵,而低强度表示山谷。你开始用不同颜色的水(标签)填充每个孤立的山谷(局部最小值)。随着水的上升,取决于附近的峰值(梯度),来自不同山谷的水,明显具有不同的颜色将开始融合。为避免这种情况,你需要在水合并的位置建立障碍。你继续填补水和建筑障碍的工作,直到所有的山峰都在水下。然后,你创建的障碍将为你提供分割结果。这是分水岭背后的“哲学”。你可以访问分水岭上的CMM网页,以便在某些动画的帮助下了解它。
但是,由于噪声或图像中的任何其他不规则性,此方法会为你提供过度调整结果。因此,OpenCV实现了一个基于标记的分水岭算法,你可以在其中指定要合并的所有谷点,哪些不合并。它是一种交互式图像分割。我们所做的是为我们所知道的对象提供不同的标签。用一种颜色(或强度)标记我们确定为前景或对象的区域,用另一种颜色标记我们确定为背景或非对象的区域,最后标记我们不确定的区域,用0标记它。这是我们的标记。然后应用分水岭算法。然后我们的标记将使用我们给出的标签进行更新,对象的边界将具有-1的值。
2、代码实现
下面我们将看到一个如何使用距离变换和分水岭来分割相互接触的物体的示例。
考虑下面的硬币图像,硬币互相接触。即使你达到阈值,它也会相互接触。

我们首先找到硬币的近似估计值。 为此,我们可以使用Otsu的二值化。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('coins.png')
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
ret, thresh = cv.threshold(gray,0,255,cv.THRESH_BINARY_INV+cv.THRESH_OTSU)
窗口将如下图显示:

现在我们需要去除图像中的任何小白噪声。为此,我们可以使用形态开放。要移除对象中的任何小孔,我们可以使用形态学闭合。所以,现在我们确切地知道靠近物体中心的区域是前景,而远离物体的区域是背景。只有我们不确定的区域是硬币的边界区域。
所以我们需要提取我们确定它们是硬币的区域。侵蚀消除了边界像素。所以无论如何,我们可以肯定它是硬币。如果物体没有相互接触,这将起作用。但由于它们相互接触,另一个好的选择是找到距离变换并应用适当的阈值。接下来我们需要找到我们确定它们不是硬币的区域。为此,我们扩大了结果。膨胀将物体边界增加到背景。这样,我们可以确保结果中背景中的任何区域都是背景,因为边界区域已被删除。见下图。

剩下的区域是我们不知道的区域,无论是硬币还是背景。 分水岭算法应该找到它。 这些区域通常围绕着前景和背景相遇的硬币边界(甚至两个不同的硬币相遇)。 我们称之为边界。 它可以从sure_bg区域中减去sure_fg区域获得。
# noise removal
kernel = np.ones((3,3),np.uint8)
opening = cv.morphologyEx(thresh,cv.MORPH_OPEN,kernel, iterations = 2)
# sure background area
sure_bg = cv.dilate(opening,kernel,iterations=3)
# Finding sure foreground area
dist_transform = cv.distanceTransform(opening,cv.DIST_L2,5)
ret, sure_fg = cv.threshold(dist_transform,0.7*dist_transform.max(),255,0)
# Finding unknown region
sure_fg = np.uint8(sure_fg)
unknown = cv.subtract(sure_bg,sure_fg)
看到结果。在阈值图像中,我们得到了一些我们确定硬币的硬币区域,现在它们已经分离。 (在某些情况下,你可能只对前景分割感兴趣,而不是分离相互接触的物体。在这种情况下,你不需要使用距离变换,只需要侵蚀就足够了。侵蚀只是提取确定前景区域的另一种方法,那就是所有。)

现在我们确定哪个是硬币区域,哪个是背景和所有。所以我们创建标记(它是一个与原始图像大小相同的数组,但是使用int32数据类型)并标记其中的区域。我们确切知道的区域(无论是前景还是背景)都标有任何正整数,但不同的整数,我们不确定的区域只是保留为零。为此,我们使用cv.connectedComponents()。它用0标记图像的背景,然后其他对象用从1开始的整数标记。
但我们知道,如果背景标记为0,分水岭会将其视为未知区域。所以我们想用不同的整数来标记它。相反,我们将用0表示由未知定义的未知区域。
# Marker labelling
ret, markers = cv.connectedComponents(sure_fg)
# Add one to all labels so that sure background is not 0, but 1
markers = markers+1
# Now, mark the region of unknown with zero
markers[unknown==255] = 0
查看JET色彩映射中显示的结果。 深蓝色区域显示未知区域。 肯定的硬币用不同的颜色着色。 与未知区域相比,确定背景的剩余区域以浅蓝色显示。

现在我们的标记准备好了。 现在是最后一步的时候,应用分水岭。 然后将修改标记图像。 边界区域将标记为-1。
markers = cv.watershed(img,markers)
img[markers == -1] = [255,0,0]

十六、基于GrabCut算法的交互式前景提取
目标:
本章节你需要学习以下内容:
*我们将看到GrabCut算法来提取图像中的前景
*我们将为此创建一个交互式应用程序。
1、理论
GrabCut算法由英国剑桥微软研究院的Carsten Rother,Vladimir Kolmogorov和Andrew Blake设计。在他们的论文中,“GrabCut”:使用迭代图切割的交互式前景提取。前景提取需要一种算法,用户交互最少,结果就是GrabCut。
从用户的角度来看它是如何工作的?最初用户在前景区域周围绘制一个矩形(前景区域应该完全在矩形内)。然后算法迭代地对其进行分段以获得最佳结果。完成。但在某些情况下,分割将不会很好,例如,它可能已将某些前景区域标记为背景,反之亦然。在这种情况下,用户需要进行精细的修饰。只需对图像进行一些描述,其中存在一些错误结果。笔划基本上说*“嘿,这个区域应该是前景,你标记它的背景,在下一次迭代中纠正它”*或它的背景相反。然后在下一次迭代中,你将获得更好的结果。
见下图。第一名球员和足球被包围在一个蓝色矩形中。然后进行一些具有白色笔划(表示前景)和黑色笔划(表示背景)的最终修饰。我们得到了一个很好的结果。

那么背景会发生什么?
- 用户输入矩形。这个矩形之外的所有东西都将被视为确定的背景(这就是之前提到的矩形应包括所有对象的原因)。矩形内的一切都是未知的。类似地,任何指定前景和背景的用户输入都被视为硬标签,这意味着它们不会在过程中发生变化。
- 计算机根据我们提供的数据进行初始标记。它标记前景和背景像素(或硬标签)
- 现在,高斯混合模型(GMM)用于模拟前景和背景。
- 根据我们提供的数据,GMM学习并创建新的像素分布。也就是说,未知像素被标记为可能的前景或可能的背景,这取决于其在颜色统计方面与其他硬标记像素的关系(它就像聚类一样)。
- 从该像素分布构建图形。图中的节点是像素。添加了另外两个节点,Source节点和Sink节点。每个前景像素都连接到Source节点,每个背景像素都连接到Sink节点。
- 将像素连接到源节点/端节点的边的权重由像素是前景/背景的概率来定义。像素之间的权重由边缘信息或像素相似性定义。如果像素颜色存在较大差异,则它们之间的边缘将获得较低的权重。
- 然后使用mincut算法来分割图形。它将图形切割成两个分离源节点和汇聚节点,具有最小的成本函数。成本函数是被切割边缘的所有权重的总和。切割后,连接到Source节点的所有像素都变为前景,连接到Sink节点的像素变为背景。
- 该过程一直持续到分类收敛为止。
如下图所示(图片提供:http://www.cs.ru.ac.za/research/g02m1682/)

2、示例
现在我们使用OpenCV进行抓取算法。 OpenCV具有此功能,cv.grabCut()。我们将首先看到它的论点:
- img - 输入图像
- mask - 这是一个掩码图像,我们指定哪些区域是背景,前景或可能的背景/前景等。它由以下标志cv.GC_BGD,cv.GC_FGD,cv.GC_PR_BGD,cv.GC_PR_FGD完成,或者只是通过图像0,1,2,3。
- rect - 矩形的坐标,包括格式为(x,y,w,h)的前景对象
- bdgModel,fgdModel - 这些是内部算法使用的数组。你只需创建两个大小为(n = 1.65)的np.float64类型零数组。
- iterCount - 算法应运行的迭代次数。
- mode - 它应该是cv.GC_INIT_WITH_RECT或cv.GC_INIT_WITH_MASK或组合,它决定我们是绘制矩形还是最终的触摸笔画。
首先让我们看看矩形模式。我们加载图像,创建一个类似的蒙版图像。我们创建了fgdModel和bgdModel。我们给出矩形参数。这一切都是直截了当的。让算法运行5次迭代。模式应该是cv.GC_INIT_WITH_RECT,因为我们使用矩形。然后运行抓取。它修改了蒙版图像。在新的掩模图像中,像素将被标记为表示背景/前景的四个标记,如上所述。因此,我们修改掩模,使得所有0像素和2像素都被置为0(即背景),并且所有1像素和3像素被置为1(即前景像素)。现在我们的最后面具准备好了。只需将其与输入图像相乘即可得到分割后的图像。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('messi5.jpg')
mask = np.zeros(img.shape[:2],np.uint8)
bgdModel = np.zeros((1,65),np.float64)
fgdModel = np.zeros((1,65),np.float64)
rect = (50,50,450,290)
cv.grabCut(img,mask,rect,bgdModel,fgdModel,5,cv.GC_INIT_WITH_RECT)
mask2 = np.where((mask==2)|(mask==0),0,1).astype('uint8')
img = img*mask2[:,:,np.newaxis]
plt.imshow(img),plt.colorbar(),plt.show()
窗口将如下图显示:

哎呀,梅西的头发不见了。 没有头发谁喜欢梅西? 我们需要把它带回来。 因此,我们将为其提供1像素(确定前景)的精细修饰。 与此同时,有些地方已经出现了我们不想要的图片,还有一些标识。 我们需要删除它们。 在那里我们提供一些0像素的修饰(确定背景)。 因此,正如我们现在所说的那样,我们在之前的案
我实际上做的是,我在绘图应用程序中打开输入图像,并在图像中添加了另一层。 在画中使用画笔工具,我在这个新图层上标记了带有黑色的白色和不需要的背景(如徽标,地面等)的前景(头发,鞋子,球等)。 然后用灰色填充剩余的背景。 然后在OpenCV中加载该掩模图像,编辑我们在新添加的掩模图像中使用相应值的原始掩模图像。 检查以下代码:
# newmask is the mask image I manually labelled
newmask = cv.imread('newmask.png',0)
# wherever it is marked white (sure foreground), change mask=1
# wherever it is marked black (sure background), change mask=0
mask[newmask == 0] = 0
mask[newmask == 255] = 1
mask, bgdModel, fgdModel = cv.grabCut(img,mask,None,bgdModel,fgdModel,5,cv.GC_INIT_WITH_MASK)
mask = np.where((mask==2)|(mask==0),0,1).astype('uint8')
img = img*mask[:,:,np.newaxis]
plt.imshow(img),plt.colorbar(),plt.show()
窗口将如下图显示:
