人脸识别损失函数之Center Loss
人脸识别的难点在于:
1、不同类人脸类别之间的分类界限不明显;
2、人脸之间的相似度很高,人类也难以区分;
3、人脸的特征分类困难。
解决途径:
1、网络模型:
残差 深度可分类 稠密网络 densenet alexet inception net 等等。。
2、损失函数:
对于回归问题,常用的损失函数是均方误差(MSE,Mean Squared Error)。
对于分类问题,常用的损失函数为交叉熵(CE,Cross Entropy)。交叉熵一般与one-hot和softmax在一起使用。
改进多分类损失函数,对细微特征的能达到好的分类效果。
一、One-Hot
在分类问题中,one-hot编码是目标类别的表达方式。目标类别需要由文字标签,转换为one-hot编码的标签。one-hot向量,在目标类别的索引位置是1,在其他位置是0。类别的数量就是one-hot向量的维度。在one-hot编码中,假设类别变量之间相互独立。同时,在多分类问题中,one-hot与softmax组合使用。
import numpy as np
def one_hot(arr):
"""
概率矩阵转换为One-Hot矩阵
arr = np.array([[0.1, 0.5, 0.4], [0.2, 0.1, 0.6]])
:param arr: 概率矩阵
:return: One-Hot矩阵
"""
arr_size = arr.shape[1] # 类别数
arr_max = np.argmax(arr, axis=1) # 最大值位置
oh_arr = np.eye(arr_size)[arr_max] # One-Hot矩阵
return oh_arr
二、Softmax
softmax使得神经网络的多个输出值的总和为1,softmax的输出值就是概率分布,应用于多分类问题。softmax也属于激活函数。softmax、one-hot和cross-entropy,一般组合使用。

import numpy as np
def softmax(x):
orig_shape=x.shape
if len(x.shape)>1:
#矩阵
tmp=np.max(x,axis=1) # 取最大值
x-=tmp.reshape((x.shape[0],1)) # 减等最大值,防止指数爆炸
x=np.exp(x)
tmp=np.sum(x,axis=1) # 重定义tmp为公式分母
x/=tmp.reshape((x.shape[0],1))
print("matrix")
else:
#向量
tmp=np.max(x)
x-=tmp
x=np.exp(x)
tmp=np.sum(x)
x/=tmp
print("vector")
return x
三、Cross-entropy
熵,热力学中表征物质状态的参量之一,用符号S表示,其物理意义是体系混乱程度的度量。香农提出了“信息熵”的概念,才解决了对信息的量化度量问题。
给定两个概率分布:p(理想结果)和q(随机分布),则通过q来表示p的交叉熵为:

交叉熵刻画的是通过概率分布q来表达概率分布p的困难程度,其中p是正确答案,q是预测值,也就是交叉熵值越小,两个概率分布越接近。这样我们可以用交叉熵来比较经过softmax输出和one-hot编码(标签)之间的距离,即模型的输出和真值,再对得到的损失进行优化。
四、Softmax Loss
多分类激活函数 softmax:将输入范围正负无穷,输出为:0~1的概率值,可以扩大相邻数值间的差距,所有概率的和为一。对softmax激活后的结果再使用交叉熵就是Softmax loss,使用Softmax loss可以刚好把人脸分开,但不能进行很好的应用。因为softmax经过了独热编码,标签为正时,yj=1,负yj=0。公式简化为:

softmax输出为0~1之间的值,求log之后:值域为负无穷到0,求负后为0到正无穷。当损失为0时,softmax输出值为1,刚好满足交叉熵的定义。
下图中,当Pj为softmax输出的(0~1)概率时,两者等价。


在使用Softmax Loss对手写数字识别的分类时,可视化效果如下图。贴个论文地址。
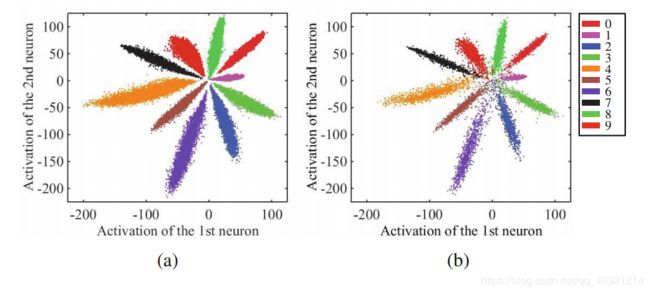
对于可以看出的10个分类而言,我们希望分类效果好意味着,让每个类之间的距离变得更大,分的更开。而且:类的中心处没有分开,我们要在增加类间距的同时,还要减小类内距离,这里引入Center loss来配合原损失函数达到给每个类规划一个中心并使其在分类的同时,类内距离减小。注意:Center loss不可以单独去使用,要配合Softmax loss。
在这段发展过程中还有两个插曲:Siamese Network 、Triplet Loss。这里不展开讨论了。
五、Center Loss
论文链接:https://ydwen.github.io/papers/WenECCV16.pdf
原文片段:增加类间距的同时,还要减小类内距离。

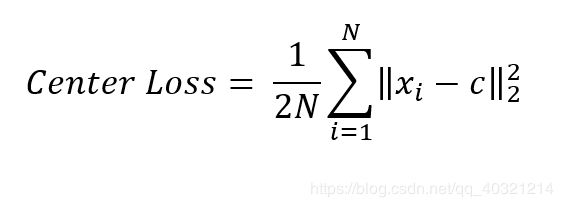
类中心c:
每一个样本的特征需要通过一个好的网络到达特征层获得,这样计算完后所有样本的特征的平均值为类中心c,而好的网络需要是在有类中心加入的情况下才能得到。
优化过程:
每个类别的中心c无法直接获得,我们将其放到网络里根据输入的feature和label的形状自己生成,在每一个batch里更新center.即随机初始化center,而后每一个batch里计算当前数据与center的距离,而后将这个梯度形式的距离加到center上。类似于参数修正。同样的类似于梯度下降法,这里再增加一个scale度量α,使得center不会抖动。一般设置为0.5。可以视其为步长或者学习率。

如何配合使用呢?看以下公式:

红色框是Softmax loss,蓝色框是Center loss,其中的λ是人为给定的平衡两个损失的权重,见下图中不同λ对应的分类效果有所不同。看在训练时更加侧重于哪个损失。在训练人脸数据集时,一般取值0.001,在训练数字10分类时一般给1或者2都行。

如何将Center loss应用到实际项目中呢?见下图中,我们需要将倒数第二层经过最大值池化的输出通过全连接层输出,这部分是用来做Center loss的,另外一部分,经过最后一层卷积输出的再经过全连接层输出,用来做Softmax loss。在提取人脸特征时,需要经过池化后输出的维度N大于128,因为这里维度越高,学习的信息也就越全面,在进行手写数字分类任务中,N=2,这里是为了可视化我们的分类效果。

综上所述,我们使用Softmax loss 来达到增大类间距离的目的,使用Center loss 来达到使类内距离减小的目的。下篇讲一下ArcSoftmax。
Center loss的缺点:
1、因为他在使用时为每个类都要确定一个中心,相当于在正常分类的同时,增加了类别中心的计算和更新,对我们的硬件要求较高;
2、因为正则化方式L2范数的平方问题,而Center loss又是用所有点对中心点进行计算后取均值,其中的离群点会对整体结果有较大影响,导致离群点不容易回归;
3、Center loss不适合用于对类别差异较大数据分类,而用于单类多目标(同一类,类间相似,类外不同)的数据适用于人脸,手写数字的分类。
手写数字10分类Center loss效果代码,目前Pytorch没有封装Center loss的函数需要自己写。第一部分代码是单独Center loss损失的设计测试,第二部分是使用两个优化器单独优化softmax loss和center loss,第三部分是训练。
在这里补上center loss求解形状变换图:

Part 1
import torch
import torch.nn as nn
def center_loss(output=None,feature, label, lambdas):
"""
:param output: shape[N,10] 网络输出,用于做BCEloss 这里用来生成center的shape[0],如手写数字为10个类
:param feature: shape[N,2] 特征层数据,用于做损失
:param label: shape[N] 标签
:param lambdas: λ超参数(学习率、步长)
:return: loss
"""
label = label.unsqueeze(0)
center = nn.Parameter(torch.randn(output.shape[1], feature.shape[1]), requires_grad=True).cuda()
#center: torch.Size([10, 2]) 其中10为类别数,2为center的维度,可视化过程中为2用于绘图。
#注意:feature与label对应的为一类,例如 feature的第4个[N,2]对应的类别为label中的[N],这样我们就要为每一个feature的相同的类规定一个中心,使用centreloss把这些相同类的拉到一堆。
#首先随机给定中心,但是要确定center的shape,因为特征点要与中心点相减,但是现在维度形状不一样
#使用index_select让center按照标签的形式扩张
#torch.index_select()函数:
label = label.squeeze()
center_exp = center.index_select(dim=0, index=label.long())
#center_exp: torch.Size([N, 2]) 原来center为[10,2]: 10为总的类别数,2为每个类的中心点,center_exp为根据label索引排列为[N,2],这样相当于为N个数据都对应了一个中心点。
#bins=int(max(label).item() + 1):当前批次label中包含的类别,不能用长度
#max=int(max(label).item()
count = torch.histc(label, bins=int(max(label).item() + 1), min=0, max=int(max(label).item()))
#做统计直方图,统计每个类别出现了几次
#count: torch.size([10]):10为这批次里有10个类,其中每个对应的数字就是该类别出现的次数
count_exp = count.index_select(dim=0, index=label.long())
#按照label去扩张,同样得到的是每个label的元素按照N个去对应的该类别所对应的出现的次数。
#下面做个图
#count_exp: torch.size([N])
loss = lambdas/2*torch.mean(torch.div(torch.sum(torch.pow(feature - center_exp, 2), dim=1), count_exp))
return loss
Part 2 网络及损失
import torch.nn as nn
import torch
import matplotlib.pyplot as plt
class CenterLoss(nn.Module):
def __init__(self, cls_num, feature_num):
super().__init__()
self.cls_num = cls_num
self.center = nn.Parameter(torch.randn(cls_num, feature_num))
def forward(self, xs, ys):
center_exp = self.center.index_select(dim=0, index=ys.long())
count = torch.histc(ys, bins=self.cls_num, min=0, max=self.cls_num - 1)
count_dis = count.index_select(dim=0, index=ys.long())
return torch.mean(torch.div(torch.sum(torch.pow(xs - center_exp, 2), dim=1), count_dis))
class Net2(nn.Module):
def __init__(self):
super().__init__()
self.conv_layer = nn.Sequential(
nn.Conv2d(1, 32, 5, 1, 2), # 28*28
nn.BatchNorm2d(32),
nn.PReLU(),
nn.Conv2d(32, 32, 5, 1, 2), # 28*28
nn.BatchNorm2d(32),
nn.PReLU(),
nn.MaxPool2d(2, 2), # 14*14
nn.Conv2d(32, 64, 5, 1, 2), # 14*14
nn.BatchNorm2d(64),
nn.PReLU(),
nn.Conv2d(64, 64, 5, 1, 2), # 14*14
nn.BatchNorm2d(64),
nn.PReLU(),
nn.MaxPool2d(2, 2), # 7*7
nn.Conv2d(64, 128, 5, 1, 2), # 7*7
nn.BatchNorm2d(128),
nn.PReLU(),
nn.Conv2d(128, 128, 5, 1, 2), # 7*7
nn.BatchNorm2d(128),
nn.PReLU(),
nn.MaxPool2d(2, 2) # 3*3
)
self.feature = nn.Linear(128 * 3 * 3, 2) # 2:(x,y)
self.output_layer = nn.Linear(2, 10)
self.center_loss_layer = CenterLoss(10, 2)
# self.center_loss = self.center_loss_layer()
def forward(self, xs):
_feature = self.conv_layer(xs)
y_conv = torch.reshape(_feature, [-1, 128 * 3 * 3])
y_feature = self.feature(y_conv) # [N 2]
y_output = torch.log_softmax(self.output_layer(y_feature), dim=1)
# print(y_feature.shape, y_output.shape)
return y_feature, y_output
def get_loss(self, features, labels):
loss_center = self.center_loss_layer(features, labels)
return loss_center
def visualize(self, feat, labels, epoch):
# plt.ion()
color = ['#ff0000', '#ffff00', '#00ff00', '#00ffff', '#0000ff',
'#ff00ff', '#990000', '#999900', '#009900', '#009999']
plt.clf()
for i in range(10):
plt.plot(feat[labels == i, 0], feat[labels == i, 1], '.', c=color[i])
plt.legend(['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'], loc='upper right')
# plt.xlim(xmin=-5, xmax=5)
# plt.ylim(ymin=-5, ymax=5)
plt.title("epoch=%d" % epoch)
plt.savefig('./images/epoch=%d.jpg' % epoch)
# plt.draw()
# plt.pause(0.001)
Part 3 训练
import torch
import torch.nn as nn
import torch.utils.data as data
import torchvision
import torchvision.transforms as transforms
from center.Center_loss_Net import CenterLoss, Net2
import os
import numpy as np
if __name__ == '__main__':
save_path1 = "./params3/net_center1.pth"
train_data = torchvision.datasets.MNIST(root=r"C:\Projects", download=False, train=True,
transform=transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=[0.5, ],
std=[0.5, ])]))
train_loader = data.DataLoader(dataset=train_data, shuffle=True, batch_size=100)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net = Net2().to(device)
if os.path.exists(save_path1):
net.load_state_dict(torch.load(save_path1))
else:
print("NO Param")
lossfn_cls = nn.NLLLoss()
optimzer = torch.optim.Adam(net.parameters())
optimzer2 = torch.optim.SGD(net.center_loss_layer.parameters(), lr=0.5, momentum=0.9)
epoch = 0
while True:
feat_loader = []
label_loader = []
for i, (x, y) in enumerate(train_loader):
x = x.to(device)
y = y.to(device)
# x = torch.reshape(x, [-1, 28*28])
feature, output = net.forward(x)
# feature2, output2 = net2.forward(x)
# print(feature.shape) # [N,2]
# print(feature.shape)#[N,2]
# print(output.shape)#[N,10]
# center = nn.Parameter(torch.randn(output.shape[1], feature.shape[1]))
# print(center.shape)#[10,2]
loss_cls = lossfn_cls(output, y)
# y = y.float()
# loss_cls, loss_center = net.get_loss(output, feature)
# loss_center = lossfn_2(feature2, feature2, y)
# print(feature2, y)
loss_center = net.get_loss(features=feature, labels=y)
loss = loss_cls + loss_center
optimzer.zero_grad()
optimzer2.zero_grad()
# loss_cls.backward(retain_graph)
# loss_center.backward()
loss.backward()
optimzer.step()
optimzer2.step()
# feature.shape=[100,2]
# y.shape=[100]
feat_loader.append(feature)
label_loader.append(y)
if i % 20 == 0:
print("epoch:", epoch, "i:", i, "total:", loss.item(), "softmax_loss:", loss_cls.item(), "center_loss:",
loss_center.item())
feat = torch.cat(feat_loader, 0)
labels = torch.cat(label_loader, 0)
'---------------'
# print(feat.shape)#feat.shape=[60000,2]
# print(labels.shape)#feat.shape=[60000]
'-------------------'
net.visualize(feat.data.cpu().numpy(), labels.data.cpu().numpy(), epoch)
epoch += 1
torch.save(net.state_dict(), save_path1)
# torch.save(net2.state_dict(), save_path2)
if epoch == 150:
break