目标检测 之 RetinaNet(Focal Loss for Dense Object Detection)
目标检测的派系:
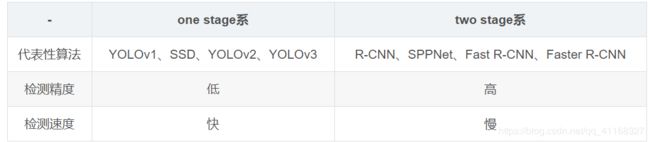

这种鱼(speed)与熊掌(accuracy)不可兼得的局面一直成为Detection的瓶颈。
作者认为单阶段的精度差在于单阶段检测器中
类别不平衡
,负样本比例远远大于正样本,占据样本中多数,影响网络的优化。
1、什么是“类别不平衡”呢?
详细来说,检测算法在早期会生成一大波的bbox。而一幅常规的图片中,顶多就那么几个object。这意味着,绝大多数的bbox属于background。
2、“类别不平衡”又如何会导致检测精度低呢?
因为bbox数量爆炸。
正是因为bbox中属于background的bbox太多了,所以如果分类器无脑地把所有bbox统一归类为background,accuracy也可以刷得很高。于是乎,分类器的训练就失败了。分类器训练失败,检测精度自然就低了。
3、那为什么two-stage系就可以避免这个问题呢?
因为two-stage系有RPN。第一个stage的RPN会对anchor进行简单的二分类(只是简单地区分是前景还是背景,并不区别究竟属于哪个细类)。经过该轮初筛,属于background的bbox被大幅砍削。虽然其数量依然远大于前景类bbox,但是至少数量差距已经不像最初生成的anchor那样夸张了。就等于是
从 “类别 极 不平衡” 变成了 “类别 较 不平衡” 。
不过,其实two-stage系的detector也不能完全避免这个问题,只能说是在很大程度上减轻了“类别不平衡”对检测精度所造成的影响。
接着到了第二个stage时,分类器登场,在初筛过后的bbox上进行难度小得多的第二波分类(这次是细分类)。这样一来,分类器得到了较好的训练,最终的检测精度自然就高啦。但是经过这么两个stage一倒腾,操作复杂,检测速度就被严重拖慢了。
4、那为什么one-stage系无法避免该问题呢?
因为one stage系的detector直接在首波生成的“类别极不平衡”的bbox中就进行难度极大的细分类,意图直接输出bbox和标签(分类结果)。而原有交叉熵损失(CE)作为分类任务的损失函数,无法抗衡“类别极不平衡”,容易导致分类器训练失败。因此,one-stage detector虽然保住了检测速度,却丧失了检测精度。
He Kaiming的《Focal Loss》
该篇文章指出,“类别不平衡”是one-stage detector在精度上逊于two-stage detector的病结所在。
CE(cross-entropy) loss
以下为典型的交叉熵loss,它广泛用于当下的图像分类、检测CNN网络当中。

Balanced CE loss
考虑到上节中提到的类别不平衡问题对最终training loss的不利影响,我们自然会想到可通过在loss公式中使用与目标存在概率成反比的系数对其进行较正。如下公式即是此朴素想法的体现。它也是作者最终Focus loss的baseline。

Focal loss定义
以下是作者提出的focal loss的想法。

下图为focal loss与常规CE loss的对比。从中,我们易看出focal loss所加的指数式系数可对正负样本对loss的贡献自动调节。当某样本类别比较明确些,它对整体loss的贡献就比较少;而若某样本类别不易区分,则对整体loss的贡献就相对偏大。这样得到的loss最终将集中精力去诱导模型去努力分辨那些难分的目标类别,于是就有效提升了整体的目标检测准度。不过在此focus loss计算当中,我们引入了一个新的hyper parameter即γ。一般来说新参数的引入,往往会伴随着模型使用难度的增加。在本文中,作者有试者对其进行调节,线性搜索后得出将γ设为2时,模型检测效果最好。

在最终所用的focal loss上,作者还引入了α系数,它能够使得focal loss对不同类别更加平衡。实验表明它会比原始的focal loss效果更好。

本质改进点在于,在原本的 交叉熵误差
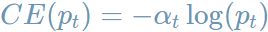 前面乘上了
前面乘上了
 这一权重。
这一权重。
该权重的影响:

也就是说,一旦乘上了该权重,量大的类别所贡献的loss被大幅砍削,量少的类别所贡献的loss几乎没有多少降低。虽然整体的loss总量减少了,但是训练过程中量少的类别拥有了更大的话语权,更加被model所关心了。
为此,FAIR还专门写了一个简单的one-stage detector来验证focal loss的强大。并将该网络结构起名RetinaNet:
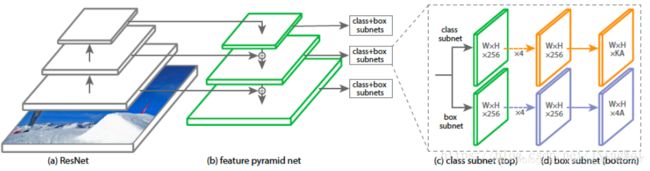
RetinaNet本质上是由resnet+FPN+两个FCN子网络组成,设计思路是backbone选择vgg、resnet等有效的特征提取网络,主要尝试了resnet50、resnet101,FPN是针对resnet里面形成的多尺度特征进行强化利用获得表达力更强包含多尺度目标区域信息的feature map,最后在FPN的feature map集合上分别使用两个结构相同但是不share参数的FCN子网络,从而完成目标框类别分类和bbox位置回归任务;
Anchor信息:anchor的面积从
 在特征金字塔p3到p7等级上,在每一个level上都有三种不同的长宽比例{1:2,1:1,2:1},针对denser scale coverage,在每一个level的anchor集合上加入
在特征金字塔p3到p7等级上,在每一个level上都有三种不同的长宽比例{1:2,1:1,2:1},针对denser scale coverage,在每一个level的anchor集合上加入
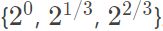 三种不同的size;每一个anchor分配一个长度为K的vector作为分类信息,以及一个长度为4的bbox回归信息;
三种不同的size;每一个anchor分配一个长度为K的vector作为分类信息,以及一个长度为4的bbox回归信息;
致谢 :
https://blog.csdn.net/JNingWei/article/details/80038594