Python3网络爬虫实战解析——静态小说网爬取(使用正则表达式解析)
网络小说爬取(静态网页):
小说网站-笔趣看:https://www.biqukan.com/
《一念永恒》章节目录:https://www.biqukan.com/1_1094/
笔趣看是一个盗版小说网站,这里有很多起点中文网的小说,该网站小说的更新速度稍滞后于起点中文网正版小说的更新速度。并且该网站只支持在线浏览,不支持小说打包下载。因此,本次实战就是从该网站爬取并保存一本名为《一念永恒》的小说,该小说是耳根的一部玄幻小说。
完整代码
写入文本文件存储。完整编写代码如下:
#小说爬取
# -*- coding:UTF-8 -*-
import requests
import re
import sys
class Noveldownloader(object):
def __init__(self):
#笔趣网url
self.main_url = 'https://www.biqukan.com'
#目录url
self.contents_url = 'https://www.biqukan.com/1_1094/'
#章节名
self.titles = []
#章节url
self.chapter_urls =[]
#章节数
self.nums = 0
#请求头
self.headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Connection': 'keep-alive',
'Accept-Encoding': 'br, gzip, deflate',
'Accept-Language':'zh-cn',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) \
AppleWebKit/605.1.15 (KHTML, like Gecko) Version/11.1 Safari/605.1.15'
}
def get_download_url(self):
'''
获取章节url
'''
res = requests.get(self.contents_url,headers=self.headers)
res.encoding ='gbk'
#print(res.text)
pattern = re.compile(r'(.*?) ')
#dd标签列表
ddlist = pattern.findall(res.text)[16:1358]
self.nums = len(ddlist)
for item in ddlist:
#匹配章节标题并加入列表
self.titles.append(re.findall(r'(.*?)',item)[0])
#匹配章节URL并加入列表
self.chapter_urls.append(self.main_url+re.findall(r'href ="(.*?)"',item)[0])
def get_contents(self,url):
'''
获取文章内容
'''
res = requests.get(url,headers=self.headers)
res.encoding = 'gbk'
#print(response.text)
pattern = re.compile(r'(.*?)')
texts = pattern.findall(res.text)[0]
#除去
和 :
content_result = texts.replace(" "*8,"\n\n").replace("
","")
return content_result
def writer(self,title,path,content):
with open(path,'a') as f:
f.write(title + '\n')
f.write(content)
f.write('\n\n\n')
if __name__ == '__main__':
#实例化下载对象
noveld1 = Noveldownloader()
#获取章节链接
noveld1.get_download_url()
print("开始下载:")
for num in range(noveld1.nums):
noveld1.writer(noveld1.titles[num],"一念永恒.txt",\
noveld1.get_contents(noveld1.chapter_urls[num]))
sys.stdout.write("已下载:%.3f%%" % float(num/noveld1.nums) +'\r')
sys.stdout.flush()
print("下载完成!")
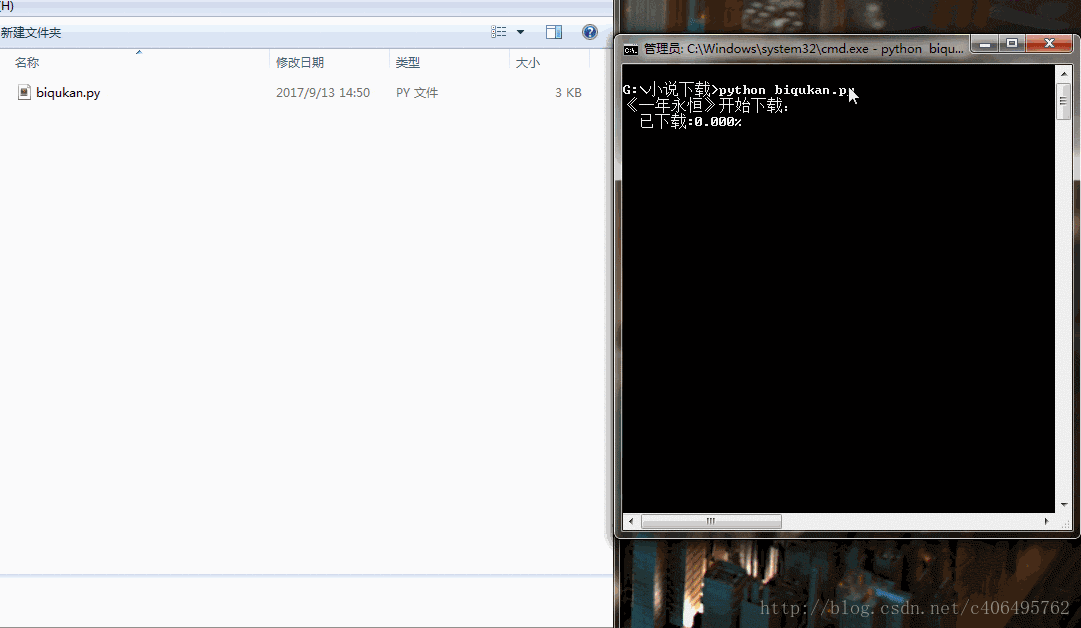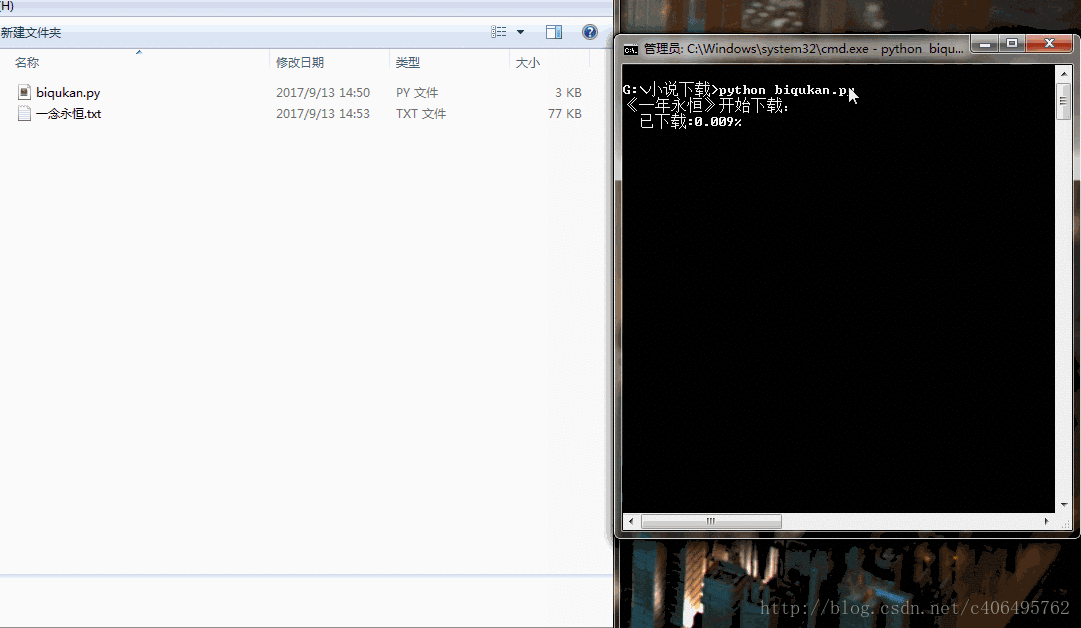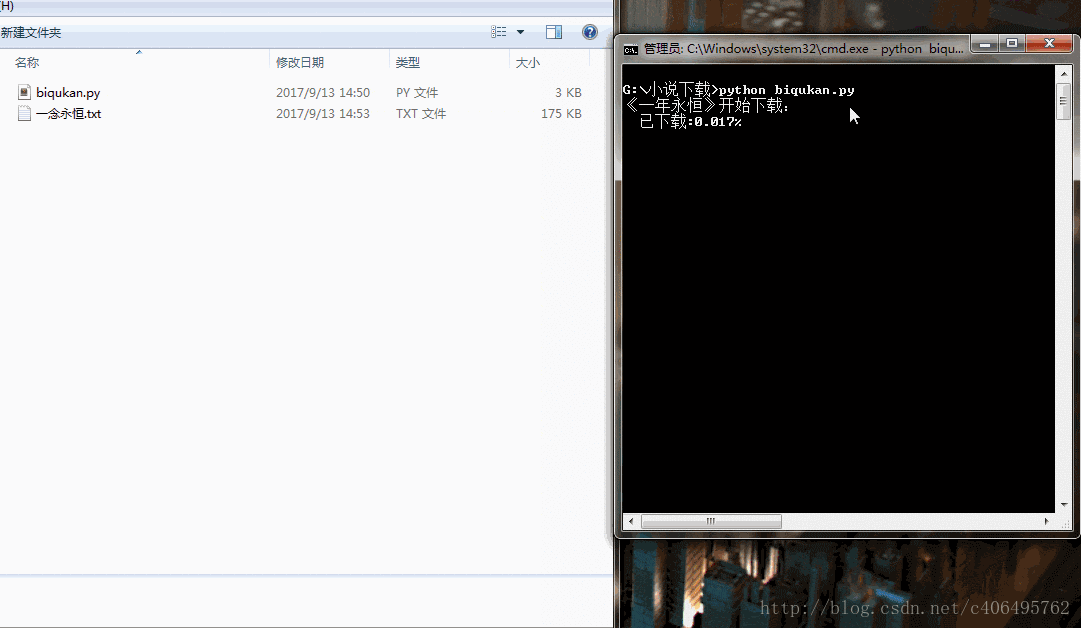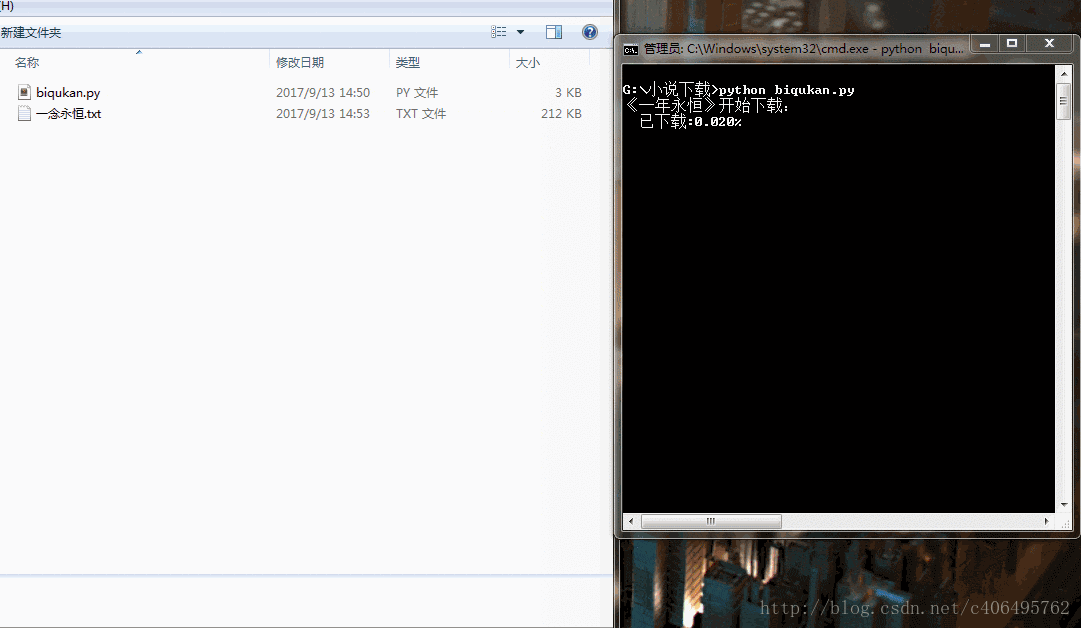
运行代码,可以看到如下结果(很简单的程序,单进程跑,没有开进程池。下载速度略慢):