浅谈自定义通讯协议——TLV
最近在做实验室的温度上报项目时,需要用到TLV来封装数据(Tag-Length-Value),然后通过客户端传送给服务器端,并作相应数据解析,再得到相应的数据。在具体了解TLV协议之前,我们先对通讯协议做一个简单的介绍。

所谓通讯协议就是指通信双方对数据传送控制的一种约定。约定中包括对数据格式,同步方式,传送速度,传送步骤,纠错方式以及控制字符定义等问题做出统一规定,通信双方必须共同遵守,倘若一方不遵守,便会直接导致数据不能被解析!更通俗来讲,它可以理解两个节点之间为了协同工作实现信息交换,协商一定的规则和约定,例如规定字节序,各个字段类型等。我们最常见到的可能是TCP(传输控制协议)/IP(网际协议)、UDP(用户数据报协议)等。
不过,上面提到的这些协议是操作系统已经设定好了的,并且广泛应用在网络通信中。最重要的一点是我们不能更改这些协议。而用户自定义的通讯协议就不同了,它的实现需要用户自己设定数据发送的格式以及数据的封装形式,然后通过上面的网络传输协议发送给对端,对端再根据自己定义好的协议对数据进行解析,从而得到想要的数据!很明显,TLV协议便是其中的一种。
这里插入一个简单应用通讯协议的例子,现在A机器通过网络socket发送数据给B机器,设定数据内容为:0x14 0x30 0x47 0x33。如果没有相应的协议规范,那么B机器只是接收了这几个字节的数据,但这些数据所代表的含义就不得而知了。现在我们规定前两个字节是温度,后两个字节是湿度,那么通过这个协议,B机器就可以对接收到的数据进行解析,从而获得温度是20.48摄氏度,相对湿度是48.71%。
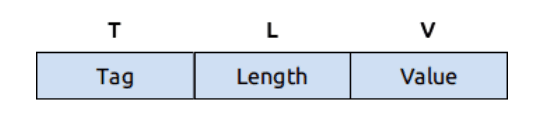
TLV是基于ASN.1标准的一种BER编码方式。由数据的类型Tag(T),数据的长度Length(L),数据的值Value(V)构成的一组数据报文。TLV是基于二进制编码的,将数据以(T -L- V)的形式编码为字节数组,即TLV是字节流的数据传输协议。它规定了一帧数据的首个字节或几个字节来表示数据类型,紧接着一个或几个字节表示数据长度,最后是数据的内容。
细心的同学可以发现上述的例子中的协议其实是存在很大的隐患的,假如现在A机器不仅仅需要发送温度和湿度的数据,还要发送电压值。此时B机器接收到的数据仍为:0x14 0x30 0x47 0x33,那此时根据这个协议要怎么解析呢?是解析成温度和湿度的组合,还是温度和电压的组合,亦或是湿度和电压的组合?
很明显之前协议的可扩展性是很差的。于是我们可以把之前定义好的协议进行改进,将其修改为TLV格式,首先定义类型,温度为0x01,湿度为0x02,电压为0x03,接着类型后面是一帧数据的长度,最后是数据的内容。如此一来,我们所发送的是数据格式也要根据协议做出调整。假设B机器此时接收到的数据为:0x01 0x04 0x14 0x30 0x02 0x04 0x47 0x33.这样一来,B机器根据协议解析数据,首先判断类型,首字节为0x01,便判断为温度,再判断长度为0x04,则这帧数据为四个字节,即到0x30 为止,最后解析数据内容,至此一帧数据便解析完了!接着再根据协议解析下一帧数据0x02 0x04 0x47 0x33。
我们利用C语言编程通过字节流发送数据,其实就是将TLV协议应用在我们的程序中,达到对我们想要发送的数据进行封装的目的。实际上,TLV只是大致规定了封装格式,并没有固定的形式,相反这需要我们用户自己设定,因为每个用户所要发送的数据类型、长度或者内容大都是不同的!
上面的例子只是简单的TLV协议应用,但这并不代表所有的TLV数据封装都是数据类型Tag是一个字节表示,数据长度Length也足以用一个字节描述。对于一些数据类型超过一个字节的TLV数据报文,便不能判断出首字节后面的字节就是数据的长度Length了,甚至一些数据的长度Length都超过了一个字节所能描述的范围,因此我们需要对协议进行灵活变通!具体的一些规则请大家参考我的这篇博客
(https://blog.csdn.net/qq_43296898/article/details/88824963)
通过前面的简单介绍想必大家已经对TLV协议有了一定的认识,但不要认为刚才定义的TLV协议已经是个完备的协议了!学通信的小伙伴都知道,目前数据的可靠性传输是很难实现的,比如你跟你的小伙伴就算是面对面交谈,都可能出现会错意的情况,更何况是在网际间以字节为单位的数据传输呢!

再次举例,假设A机器发送的数据仍为:0x01 0x04 0x14 0x30 0x02 0x04 0x47 0x33,但此时B机器接收到的数据丢失了第一个字节(0x01) 0x04 0x14 0x30 0x02 0x04 0x47 0x33,那么此时B机器该如何解析呢?答案是B机器解析到首字节为0x04,在数据类型中并未定义(我们只是定义了温度为0x01,湿度为0x02,电压为0x03),所以B机器便把这段数据丢掉,再次解析直至到0x02,解析出为湿度,然后继续解析!
这时读者心里可能有疑问,那假如发送的数据为:0x01 0x02 0x06 0x30 0x02 0x04 0x47 0x33,接收到的数据为:0x02 0x06 0x30 0x02 0x04 0x47 0x33。可见丢失了(0x01) 首字节的数据,那接收到这样的数据,B机器依然解析,只不过这次数据的首字节是我们实现定义好的数据类型,然后又是长度,最后解析出的内容不全乱了吗?是的,没错,确实是全乱了!
所以我们刚才简单定义的TLV协议是不完善的。为了完善我们的TLV协议,我们仍需要在我们的TLV协议数据封装格式之前加上一个帧头!作为每一帧数据解析的起始部分。
现在我们便进行改进,在每一帧数据之前加上一个帧头0xFD,这样一来,A机器再次发送数据则为:0xFD 0x01 0x04 0x14 0x30 0xFD 0x02 0x04 0x47 0x33,现在B机器接收到的数据为:0x04 0x14 0x30 0xFD 0x02 0x04 0x47 0x33。丢失了(0xFD 0x01)这部分数据。那么B机器会判断接收到的数据的首字节是否为帧头,再进行数据解析,因为0x04 0x14 0x30这里面没有包含帧头0xFD,所以会丢弃这些错误报文继续找下一个0xFD开始的报文(0xFD 0x02 0x04 0x47 0x33),这种情况下可以前一个错误报文并不会影响后一个正常报文的处理。这样,通过加入帧头的机制,可以解决一帧出错导致所有报文都出错的问题。
但是…就算是这样还是会发生错误,假如刚才发送的数据是这样的:
0xFD 0x01 0x04 0xFD 0x30(第一帧数据) 0xFD 0x02 0x04 0x47 0x33(第二帧数据), 现在B机器接收到的数据为: 0x01 0x04 0xFD 0x30 0xFD 0x02 0x04 0x47 0x33。 丢失了(0xFD 0x01)这两个字节的数据。这样的话,岂不是也乱套了?所以帧头只有一个字节的话,数据传输出现差错的概率依然不可忽略!
这时,如果我们使用两个或者四个字节的帧头的话,数据传输出错的概率就会降得更低。接下来,数据传输又出现了问题!怎么回事呢?我已经把协议完善的很到位了,好气哦…
到底是怎么回事呢,原来是这样,A机器发送的数据:0xFD 0x01 0x04 0xFD 0x01 0xFD 0x02 0x04 0x47 0x33然而B机器接收到的数据为:0x04 0xFD 0x01 0xFD 0x02 0x04 0x47 0x33。很明显第一帧数据出错,但可恨的是解析到第一个0xFD,后面的0x01也符合我们之前定义的Tag类型,然后第二个0xFD就被解析成了数据的长度Length!然后就再次全乱了…
有了上面的教训,这里我们再次对协议进行完善,这次我们在每帧数据的最后加上一个CRC校验和,那么一旦每帧数据出错了,那么CRC校验时就一定会出错,这样就会去解析下一帧数据了。
至此我们实现了一个比较完备的通信协议:
【帧头(n字节)】 【Tag】【Length】 【nBytes Value】 【CRC校验和】