- Gmsh教程
网卡了
GmshpythonGmsh
13、在没有底层CAD模型的情况下重新擦除STL文件importgmsh#导入Gmsh库,用于几何建模和网格划分importmath#导入数学库,用于计算importos#导入操作系统库,用于处理文件路径importsys#导入系统库,用于处理命令行参数gmsh.initialize()#初始化Gmsh环境defcreateGeometryAndMesh():#清除之前的模型和数据gmsh.cle
- 需求池膨胀时如何科学排序优先级
需求分析
需求池膨胀时如何科学排序优先级主要依靠数据驱动、战略对齐、风险评估**。其中数据驱动是关键,通过收集历史数据、用户反馈与市场趋势,对各项需求进行量化评估,帮助企业在需求膨胀时做出精准排序和资源配置。实践表明,数据驱动的决策可使需求响应速度提升约30%,大大优化资源分配效果。一、需求池膨胀现象的背景与挑战、需求池指的是企业内部或市场上积累的各类需求、项目或功能请求。随着企业发展和市场环境变化,需求池
- OpenBayes 教程上新丨单卡A6000轻松部署Gemma 3,精准识别黄仁勋演讲实拍
3月12日晚间,谷歌发布了「单卡大魔王」Gemma3,号称是能在单个GPU或TPU上运行的最强模型,真实战绩也证实了官方blog所言非虚——其27B版本击败671B的满血DeepSeekV3,以及o3-mini、Llama-405B,仅次于DeepSeekR1,但在算力需求方面却远低于其他模型。如下图所示:*按照ChatbotArenaElo分数对模型进行排名;圆点表示预估的算力需求随后,谷歌也是
- Docker环境安装anythingllm
时下握今
大模型本地知识库
拉镜像dockerpullmintplexlabs/anythingllm建目录exportSTORAGE_LOCATION=$HOME/anythingllm&&\mkdir-p$STORAGE_LOCATION&&\touch"$STORAGE_LOCATION/.env"检查目录具有写权限#为目录anythingllm赋写权限chmod777anythingllm启anythingllmsu
- Flutter 适配HarmonyOS NEXT:调用原生功能实现相册选取与拍照
Flutter适配鸿蒙系统:调用原生功能实现相册选取与拍照项目背景我们的移动端项目基于Flutter开发,为控制开发周期与成本,采用了HarmonyOSNEXT(简称鸿蒙)的Flutter兼容库,并更新了部分三方库为鸿蒙的Flutter兼容库。在图片视频选择与拍摄功能上,我们之前调用的是Android和iOS的原生方法,现在需要为鸿蒙开发一套原生配合使用的方案。遇到的问题鸿蒙的Flutter兼容库
- 一切皆是映射:DQN训练加速技术:分布式训练与GPU并行
AI天才研究院
计算AI大模型企业级应用开发实战ChatGPT计算科学神经计算深度学习神经网络大数据人工智能大型语言模型AIAGILLMJavaPython架构设计AgentRPA
1.背景介绍1.1深度强化学习的兴起近年来,深度强化学习(DeepReinforcementLearning,DRL)在游戏、机器人控制、自然语言处理等领域取得了令人瞩目的成就。作为一种结合深度学习和强化学习的强大技术,DRL能够使智能体在与环境交互的过程中学习最优策略,从而实现自主决策和控制。1.2DQN算法及其局限性深度Q网络(DeepQ-Network,DQN)是DRL的一种经典算法,它利用
- 社心3章:社会信念和判断(二)
songtaiwu
心理学英文书翻译数据库
HOWDOWEJUDGEOURSOCIALWORLD?Aswehavealreadynoted,ourcognitivemechanismsareefficientandadaptive,yetoccasionallyerror-prone.Usuallytheyserveuswell.Butsometimescliniciansmisjudgepatients,employersmisjudge
- 软件定义世界下的教育创新:高校计算机实验室应重心转向开源平台
开源
一、一键式教学环境部署,节省90%准备时间•应用模板库:提供200+预置教学工具模板(如JupyterLab+TensorFlow、MySQL集群),教师可根据课程需求选择模板,5分钟内完成包含依赖库、运行环境的全栈部署。•多版本隔离:支持同一服务器并行运行不同版本框架(如Django3.2教学版与4.1开发版),避免版本冲突导致30%的课堂时间浪费。•自助式环境创建:学生通过命令行快速申请带GP
- LangChain入门:使用Python和通义千问打造免费的Qwen大模型聊天机器人
南七小僧
人工智能网站开发AI技术产品经理服务器数据库windows
前言LangChain是一个用于开发由大型语言模型(LargeLanguageModels,简称LLMs)驱动的应用程序的框架。它提供了一个灵活的框架,使得开发者可以构建具有上下文感知能力和推理能力的应用程序,这些应用程序可以利用公司的数据和APIs。这个框架由几个部分组成。LangChain库:Python和JavaScript库。包含了各种组件的接口和集成,一个基本的运行时,用于将这些组件组合
- mysql 统计同一字段不同值的个数
liudachu
Mysql数据库mysql
在一个项目中,制作呃echart图表的时候,遇到一个需求,需要从后端接口获取数据----售票员的姓名和业绩所以需要在订单表中,获取不同售票员的订单数量。订单表解决方案汇总MySQL统计一个列中不同值的数量需求:MySQL统计一个列中不同值的数量,其中origin是用户来源,其中的值有iPhone、Android、Web三种,现在需要分别统计由这三种渠道注册的用户数量。方案1:SELECTcount
- python之gmsh划分网格
老歌老听老掉牙
python有限元分析python开发语言gmsh划分网格
Gmsh(GeometryModelingandMeshingSuite)是一个开源的三维有限元网格生成器,它集成了内置的CAD引擎和后处理器。Gmsh的设计目标是提供一个快速、轻量级且用户友好的网格工具,同时具备参数化输入和高级可视化能力。Gmsh围绕几何(geometry)、网格(mesh)、求解器(solver)和后处理(post-processing)四个模块构建,用户可以通过图形用户界面
- 探索 LangChain、Hugging Face、LM Studio 等 AI 应用工具
Alex程
langchain人工智能
目录1.LangChainv0.2简介安装概念指南简单试用(1)模型选择(2)基础操作(3)更多操作Runnable调用链的连接Runnable并行自定义函数RunnableLambda额外assign参数(4)langchain.js2.HuggingFace简介如何调用API3.LMStudio简介LMStudio服务器JavaScript/TypeScriptSDK4.Dify.AI简介安装
- 美团Leaf分布式ID生成器使用教程:号段模式与Snowflake模式详解
Cloud_.
分布式
引言在分布式系统中,生成全局唯一ID是核心需求之一。美团开源的Leaf提供了两种分布式ID生成方案:号段模式(高可用、依赖数据库)和Snowflake模式(高性能、去中心化)。本文将手把手教你如何配置和使用这两种模式,并解析其核心机制。一、Leaf号段模式使用教程1.环境准备数据库:MySQL5.7+Java环境:JDK1.8+Leaf源码:从GitHub克隆Leaf仓库(推荐使用feature/
- PHP接入阿里云图片审核
骑着蜗牛闯宇宙
xiaophp阿里云开发语言
多个service使用接口ImageBatchModerationgetenv("ALIBABA_CLOUD_ACCESS_KEY_ID"),//必填,请确保代码运行环境设置了环境变量ALIBABA_CLOUD_ACCESS_KEY_SECRET。"accessKeySecret"=>getenv("ALIBABA_CLOUD_ACCESS_KEY_SECRET")]);//Endpoint请参考
- echarts柱状图区间滚动
没有天赋的搬砖者
echarts前端javascript
constxData=['00:00','01:00','02:00','03:00','04:00','05:00','06:00'];constbarData=[5,20,36,10,10,20];option={tooltip:{show:true,trigger:'axis',confine:true,formatter(item){consthtml=`${xData[item[0].d
- RSA加密算法
不会搬砖的淡水鱼
网络服务器安全
RSA加密算法:数学魔术背后的安全守护者RSA加密算法(Rivest-Shamir-Adleman)是一种广泛使用的公钥加密算法,它在信息安全领域具有重要作用。RSA是由罗纳德·李维斯特(RonRivest)、阿迪·萨莫尔(AdiShamir)和伦纳德·阿德曼(LeonardAdleman)在1977年一起提出的。当时他们三人都在麻省理工学院工作。RSA就是他们三人姓氏开头字母拼在一起组成的。RS
- 基础算法--欧拉函数
不会搬砖的淡水鱼
基础算法算法java数据结构
欧拉函数(Euler’stotientfunction),也称为费马函数,是一个与正整数相关的数论函数,用符号φ(n)表示。欧拉函数φ(n)定义为小于或等于n的正整数中与n互质的数的个数。RSA加密算法(Rivest-Shamir-Adleman)就是通过欧拉函数进行公钥加密。具体而言,对于给定的正整数n,欧拉函数φ(n)计算满足以下条件的k的个数:1≤k≤n,且k与n互质(即k和n的最大公约数为
- H5语音识别功能(Web Speech API+科大讯飞)
辣辣1
语音识别前端
H5语音识别效果图:方案一:WebSpeechAPI(免费,IE浏览器可用,谷歌浏览器不可用)方案一:WebSpeechAPI开始停止识别结果:{{finalTranscript}}{{interimTranscript}}import{ref,onMounted,onBeforeUnmount}from"vue";constisSupported=ref(false);constisRecord
- 《Flutter从入门到实战:手把手构建跨平台应用(万字深度解析)》
前端极客探险家
flutter
目录标题前言:为什么选择Flutter?一、Flutter基础篇:环境搭建与核心概念1.1开发环境配置1.2项目结构深度解析二、核心机制:Widget与渲染原理2.1Widget树构建原理2.2状态管理方案对比三、企业级开发实战3.1工程化架构设计3.2典型功能实现四、进阶开发技巧4.1性能优化方案4.2平台特定代码集成五、项目实战:开发企业级Todo应用(深度扩展版)5.1项目初始化与工程化配置
- 初学python100例-案例4 计算一年第几天 多种不同解法 少儿编程案例讲解
小兔子编程
初学python100例python学习python100例python计算天数python算法python案例
题目输入某年某月某日,判断这一天是这一年的第几天?解法1程序分析1、以5月2日为例,应该先把前四个月的加起来,2、然后再加上2天即本年的第几天,3、特殊情况,闰年且输入月份大于2时需考虑多加一天:4、闰年1、年份能被4整除;2、年份若是100的整数倍的话需被400整除,否则是平年。程序源代码:year=int(input('year:\n'))month=int(input('month:\n')
- 推荐一个开源的高效头像生成工具,支持API调用
计算机小手
经验分享开源软件
一、简介集成多种头像生成方案,包括:ugly-avatar、multiavatar、jdenticon、facesjs、dicebear等支持docker部署,支持API调用项目开源地址:GitHub-luler/hello_avatar:轻松搭建生成简易头像的api服务二、安装准备好docker、docker-compose环境新建docker-compose.yml,配置内容如下:versio
- Trae AI 上新 SSHremote:服务器 Python 接口日志排查实战指南
芯作者
DD:日记人工智能深度学习机器学习
在当今的软件开发中,服务器端的稳定性和可靠性至关重要。然而,生产环境中的问题往往难以预测,尤其是接口返回502错误却无日志记录的情况,更是让开发者头疼不已。幸运的是,字节跳动推出的AI原生IDE——Trae,近期上线的SSHremote功能,为远程服务器日志排查提供了全新的解决方案。本文将结合实战案例,深入探讨如何利用TraeAI的SSHremote功能高效排查Python接口日志问题,并分享创新
- Python入门程序练习004:输入某年某月某日,判断这一天是这一年的第几天?
若北辰
Python实战练习
【程序4】题目:输入某年某月某日,判断这一天是这一年的第几天?1.程序分析:其实这一题的难度不在于编程,而在于对闰年有没有一些基本的认识,相信很多人都知道闰年,但是又不太清楚具体怎么判断闰年。在下面两个条件中只要满足一个即是闰年:1、能被4整除但是不能被一百整除2、能被四百整除。为了方便记忆,总结为:四年一闰,百年不闰,四百年再闰那么判断出闰年和平年(除了闰年其他都是平年)之后呢,其实只要记住:闰
- 保姆级 STM32 HAL 库外部中断教学
CircuitWizard
单片机stm32单片机嵌入式硬件
1.外部中断概述为什么用外部中断?当按键按下时,CPU无需轮询检测引脚状态,而是通过中断机制立即响应,提高效率,适用于实时性要求高的场景。关键概念EXTI(ExternalInterrupt/EventController):STM32的外设,负责管理外部中断/事件。NVIC(NestedVectoredInterruptController):管理中断优先级和使能。GPIO与EXTI的映射:每个
- 主流区块链平台对 EVM 的依赖情况分类说明
倒霉男孩
区块链知识区块链
文章目录概要1.EVM兼容链BinanceSmartChain(BSC)Polygon(PoS链)AvalancheC-ChainFantomOptimism/Arbitrum2.非EVM链3.混合型链AvalanchePolygonSupernetsBNBChain概要1.EVM兼容链这些链直接支持以太坊虚拟机,开发者可用Solidity编写合约,并复用以太坊工具链:BinanceSmartCh
- 华为新系统鸿蒙手机8月发布,华为将发布鸿蒙手机操作新系统
许逸YIXU
华为新系统鸿蒙手机8月发布
华为将发布鸿蒙手机操作新系统华为正式发布鸿蒙手机操作系统,6月2日晚,华为正式发布了HarmonyOS2.0,以及一系列搭载鸿蒙OS2操作系统的智能手机、智能手表和平板电脑。“万物互联时代,没有人会是一座孤岛。”华为将发布鸿蒙手机操作新系统1“万物互联时代,没有人会是一座孤岛。”6月2日的HarmonyOS2及华为全场景新品发布会上,华为常务董事、消费者业务CEO余承东如是说。HarmonyOS是
- 指令系统和计算机体系结构——一文解析冯·诺依曼架构
点滴汇聚江河
软考-软件设计师架构
文章目录一、核心思想二、核心组成部分1.中央处理器(CPU)2.内存(Memory)3.输入/输出(I/O)设备4.总线(Bus)三、工作流程四、冯·诺依曼架构的局限性五、现代计算机的改进1.流水线技术(Pipeline)关键机制2.高速缓存(Cache)关键机制3.多核CPU(Multi-Core)关键挑战与解决方案4.乱序执行(Out-of-OrderExecution)关键技术5.其他关键改
- 【知识图谱】开发经验记录:CORS(跨域资源共享)问题
niuuuu16
基于知识图谱的智能助教系统知识图谱人工智能经验分享javaspringboot
尝试前后端交互时出现了这样的报错:AccesstoXMLHttpRequestat'http://localhost:8080/api/courses'fromorigin'http://localhost:8081'hasbeenblockedbyCORSpolicy:No'Access-Control-Allow-Origin'headerispresentontherequestedreso
- 含光热电站、有机有机朗肯循环、P2G的综合能源优化调度(Matlab代码实现)
创新优化代码学习
能源matlab前端
个人主页欢迎来到本博客❤️❤️博主优势:博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。⛳️座右铭:行百里者,半于九十。本文目录如下:目录1概述含光热电站、有机朗肯循环与P2G的综合能源优化调度研究一、技术基础与系统作用二、多技术协同机制三、优化调度模型构建四、典型案例与仿真分析五、未来研究方向结论2运行结果3参考文献4Matlab代码实现1概述光热发电(concentratingsolarp
- PyCharm的终端(terminal)中进入指定conda虚拟环境
我不是程序员
软件开发工作基础知识pycharmcondalinux
参考这篇博文:PyCharm的终端(terminal)中进入指定conda虚拟环境_pycharm配置conda终端-CSDN博客
- Java实现的简单双向Map,支持重复Value
superlxw1234
java双向map
关键字:Java双向Map、DualHashBidiMap
有个需求,需要根据即时修改Map结构中的Value值,比如,将Map中所有value=V1的记录改成value=V2,key保持不变。
数据量比较大,遍历Map性能太差,这就需要根据Value先找到Key,然后去修改。
即:既要根据Key找Value,又要根据Value
- PL/SQL触发器基础及例子
百合不是茶
oracle数据库触发器PL/SQL编程
触发器的简介;
触发器的定义就是说某个条件成立的时候,触发器里面所定义的语句就会被自动的执行。因此触发器不需要人为的去调用,也不能调用。触发器和过程函数类似 过程函数必须要调用,
一个表中最多只能有12个触发器类型的,触发器和过程函数相似 触发器不需要调用直接执行,
触发时间:指明触发器何时执行,该值可取:
before:表示在数据库动作之前触发
- [时空与探索]穿越时空的一些问题
comsci
问题
我们还没有进行过任何数学形式上的证明,仅仅是一个猜想.....
这个猜想就是; 任何有质量的物体(哪怕只有一微克)都不可能穿越时空,该物体强行穿越时空的时候,物体的质量会与时空粒子产生反应,物体会变成暗物质,也就是说,任何物体穿越时空会变成暗物质..(暗物质就我的理
- easy ui datagrid上移下移一行
商人shang
js上移下移easyuidatagrid
/**
* 向上移动一行
*
* @param dg
* @param row
*/
function moveupRow(dg, row) {
var datagrid = $(dg);
var index = datagrid.datagrid("getRowIndex", row);
if (isFirstRow(dg, row)) {
- Java反射
oloz
反射
本人菜鸟,今天恰好有时间,写写博客,总结复习一下java反射方面的知识,欢迎大家探讨交流学习指教
首先看看java中的Class
package demo;
public class ClassTest {
/*先了解java中的Class*/
public static void main(String[] args) {
//任何一个类都
- springMVC 使用JSR-303 Validation验证
杨白白
springmvc
JSR-303是一个数据验证的规范,但是spring并没有对其进行实现,Hibernate Validator是实现了这一规范的,通过此这个实现来讲SpringMVC对JSR-303的支持。
JSR-303的校验是基于注解的,首先要把这些注解标记在需要验证的实体类的属性上或是其对应的get方法上。
登录需要验证类
public class Login {
@NotEmpty
- log4j
香水浓
log4j
log4j.rootCategory=DEBUG, STDOUT, DAILYFILE, HTML, DATABASE
#log4j.rootCategory=DEBUG, STDOUT, DAILYFILE, ROLLINGFILE, HTML
#console
log4j.appender.STDOUT=org.apache.log4j.ConsoleAppender
log4
- 使用ajax和history.pushState无刷新改变页面URL
agevs
jquery框架Ajaxhtml5chrome
表现
如果你使用chrome或者firefox等浏览器访问本博客、github.com、plus.google.com等网站时,细心的你会发现页面之间的点击是通过ajax异步请求的,同时页面的URL发生了了改变。并且能够很好的支持浏览器前进和后退。
是什么有这么强大的功能呢?
HTML5里引用了新的API,history.pushState和history.replaceState,就是通过
- centos中文乱码
AILIKES
centosOSssh
一、CentOS系统访问 g.cn ,发现中文乱码。
于是用以前的方式:yum -y install fonts-chinese
CentOS系统安装后,还是不能显示中文字体。我使用 gedit 编辑源码,其中文注释也为乱码。
后来,终于找到以下方法可以解决,需要两个中文支持的包:
fonts-chinese-3.02-12.
- 触发器
baalwolf
触发器
触发器(trigger):监视某种情况,并触发某种操作。
触发器创建语法四要素:1.监视地点(table) 2.监视事件(insert/update/delete) 3.触发时间(after/before) 4.触发事件(insert/update/delete)
语法:
create trigger triggerName
after/before
- JS正则表达式的i m g
bijian1013
JavaScript正则表达式
g:表示全局(global)模式,即模式将被应用于所有字符串,而非在发现第一个匹配项时立即停止。 i:表示不区分大小写(case-insensitive)模式,即在确定匹配项时忽略模式与字符串的大小写。 m:表示
- HTML5模式和Hashbang模式
bijian1013
JavaScriptAngularJSHashbang模式HTML5模式
我们可以用$locationProvider来配置$location服务(可以采用注入的方式,就像AngularJS中其他所有东西一样)。这里provider的两个参数很有意思,介绍如下。
html5Mode
一个布尔值,标识$location服务是否运行在HTML5模式下。
ha
- [Maven学习笔记六]Maven生命周期
bit1129
maven
从mvn test的输出开始说起
当我们在user-core中执行mvn test时,执行的输出如下:
/software/devsoftware/jdk1.7.0_55/bin/java -Dmaven.home=/software/devsoftware/apache-maven-3.2.1 -Dclassworlds.conf=/software/devs
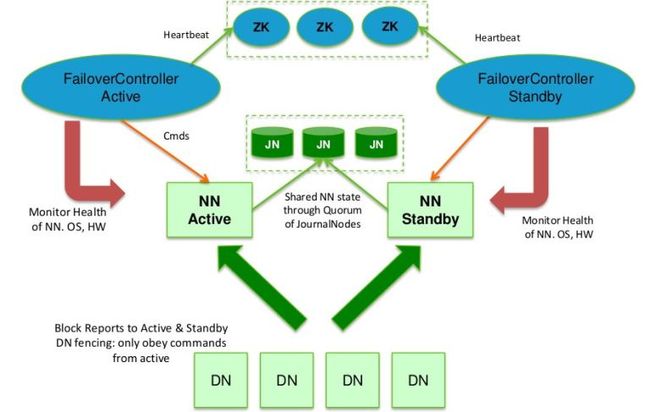
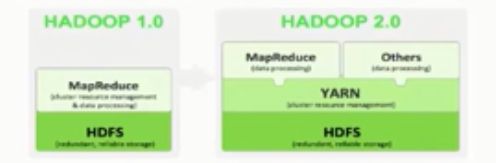
- 【Hadoop七】基于Yarn的Hadoop Map Reduce容错
bit1129
hadoop
运行于Yarn的Map Reduce作业,可能发生失败的点包括
Task Failure
Application Master Failure
Node Manager Failure
Resource Manager Failure
1. Task Failure
任务执行过程中产生的异常和JVM的意外终止会汇报给Application Master。僵死的任务也会被A
- 记一次数据推送的异常解决端口解决
ronin47
记一次数据推送的异常解决
需求:从db获取数据然后推送到B
程序开发完成,上jboss,刚开始报了很多错,逐一解决,可最后显示连接不到数据库。机房的同事说可以ping 通。
自已画了个图,逐一排除,把linux 防火墙 和 setenforce 设置最低。
service iptables stop
- 巧用视错觉-UI更有趣
brotherlamp
UIui视频ui教程ui自学ui资料
我们每个人在生活中都曾感受过视错觉(optical illusion)的魅力。
视错觉现象是双眼跟我们开的一个玩笑,而我们往往还心甘情愿地接受我们看到的假象。其实不止如此,视觉错现象的背后还有一个重要的科学原理——格式塔原理。
格式塔原理解释了人们如何以视觉方式感觉物体,以及图像的结构,视角,大小等要素是如何影响我们的视觉的。
在下面这篇文章中,我们首先会简单介绍一下格式塔原理中的基本概念,
- 线段树-poj1177-N个矩形求边长(离散化+扫描线)
bylijinnan
数据结构算法线段树
package com.ljn.base;
import java.util.Arrays;
import java.util.Comparator;
import java.util.Set;
import java.util.TreeSet;
/**
* POJ 1177 (线段树+离散化+扫描线),题目链接为http://poj.org/problem?id=1177
- HTTP协议详解
chicony
http协议
引言
- Scala设计模式
chenchao051
设计模式scala
Scala设计模式
我的话: 在国外网站上看到一篇文章,里面详细描述了很多设计模式,并且用Java及Scala两种语言描述,清晰的让我们看到各种常规的设计模式,在Scala中是如何在语言特性层面直接支持的。基于文章很nice,我利用今天的空闲时间将其翻译,希望大家能一起学习,讨论。翻译
- 安装mysql
daizj
mysql安装
安装mysql
(1)删除linux上已经安装的mysql相关库信息。rpm -e xxxxxxx --nodeps (强制删除)
执行命令rpm -qa |grep mysql 检查是否删除干净
(2)执行命令 rpm -i MySQL-server-5.5.31-2.el
- HTTP状态码大全
dcj3sjt126com
http状态码
完整的 HTTP 1.1规范说明书来自于RFC 2616,你可以在http://www.talentdigger.cn/home/link.php?url=d3d3LnJmYy1lZGl0b3Iub3JnLw%3D%3D在线查阅。HTTP 1.1的状态码被标记为新特性,因为许多浏览器只支持 HTTP 1.0。你应只把状态码发送给支持 HTTP 1.1的客户端,支持协议版本可以通过调用request
- asihttprequest上传图片
dcj3sjt126com
ASIHTTPRequest
NSURL *url =@"yourURL";
ASIFormDataRequest*currentRequest =[ASIFormDataRequest requestWithURL:url];
[currentRequest setPostFormat:ASIMultipartFormDataPostFormat];[currentRequest se
- C语言中,关键字static的作用
e200702084
C++cC#
在C语言中,关键字static有三个明显的作用:
1)在函数体,局部的static变量。生存期为程序的整个生命周期,(它存活多长时间);作用域却在函数体内(它在什么地方能被访问(空间))。
一个被声明为静态的变量在这一函数被调用过程中维持其值不变。因为它分配在静态存储区,函数调用结束后并不释放单元,但是在其它的作用域的无法访问。当再次调用这个函数时,这个局部的静态变量还存活,而且用在它的访
- win7/8使用curl
geeksun
win7
1. WIN7/8下要使用curl,需要下载curl-7.20.0-win64-ssl-sspi.zip和Win64OpenSSL_Light-1_0_2d.exe。 下载地址:
http://curl.haxx.se/download.html 请选择不带SSL的版本,否则还需要安装SSL的支持包 2. 可以给Windows增加c
- Creating a Shared Repository; Users Sharing The Repository
hongtoushizi
git
转载自:
http://www.gitguys.com/topics/creating-a-shared-repository-users-sharing-the-repository/ Commands discussed in this section:
git init –bare
git clone
git remote
git pull
git p
- Java实现字符串反转的8种或9种方法
Josh_Persistence
异或反转递归反转二分交换反转java字符串反转栈反转
注:对于第7种使用异或的方式来实现字符串的反转,如果不太看得明白的,可以参照另一篇博客:
http://josh-persistence.iteye.com/blog/2205768
/**
*
*/
package com.wsheng.aggregator.algorithm.string;
import java.util.Stack;
/**
- 代码实现任意容量倒水问题
home198979
PHP算法倒水
形象化设计模式实战 HELLO!架构 redis命令源码解析
倒水问题:有两个杯子,一个A升,一个B升,水有无限多,现要求利用这两杯子装C
- Druid datasource
zhb8015
druid
推荐大家使用数据库连接池 DruidDataSource. http://code.alibabatech.com/wiki/display/Druid/DruidDataSource DruidDataSource经过阿里巴巴数百个应用一年多生产环境运行验证,稳定可靠。 它最重要的特点是:监控、扩展和性能。 下载和Maven配置看这里: http
- 两种启动监听器ApplicationListener和ServletContextListener
spjich
javaspring框架
引言:有时候需要在项目初始化的时候进行一系列工作,比如初始化一个线程池,初始化配置文件,初始化缓存等等,这时候就需要用到启动监听器,下面分别介绍一下两种常用的项目启动监听器
ServletContextListener
特点: 依赖于sevlet容器,需要配置web.xml
使用方法:
public class StartListener implements
- JavaScript Rounding Methods of the Math object
何不笑
JavaScriptMath
The next group of methods has to do with rounding decimal values into integers. Three methods — Math.ceil(), Math.floor(), and Math.round() — handle rounding in differen

 QQ截图20180306183158.png
QQ截图20180306183158.png