docker+paddleserving部署手写数字识别模型
任务概述
本文利用docker+paddleserving实现手写数字识别模型在服务器上的部署。
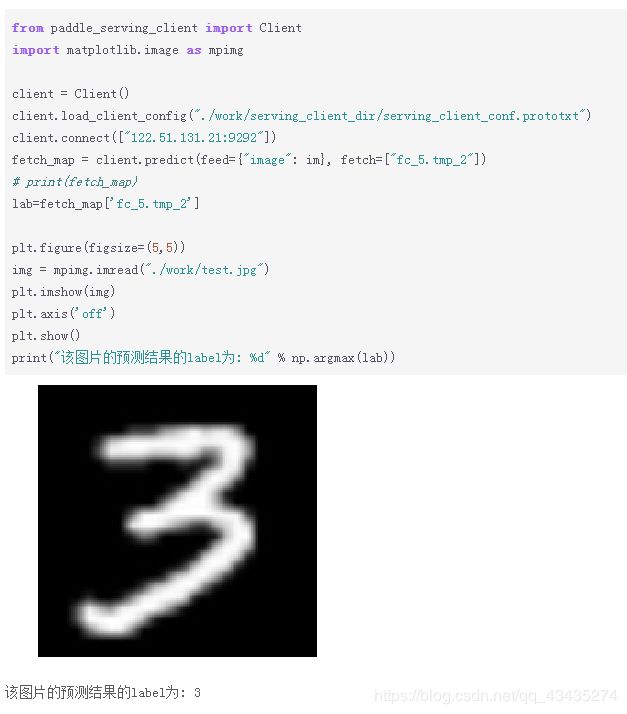
首先需要通过pip install paddle-serving-server和pip install paddle-serving-client 安装paddleserving。最后部署完成以后,预测的结果如下:
一、实现思路
1.用paddle自带的mnist数据集训练一个手写数字识别模型
2.把训练后的模型转换成paddle_serving模型
3.利用docker+paddle_serving在服务器上部署模型
二、模型训练
#导入需要的包
import numpy as np
import paddle as paddle
import paddle.fluid as fluid
from PIL import Image
import matplotlib.pyplot as plt
import os
BUF_SIZE=512
BATCH_SIZE=128
#用于训练的数据提供器,每次从缓存中随机读取批次大小的数据
train_reader = paddle.batch(
paddle.reader.shuffle(paddle.dataset.mnist.train(),
buf_size=BUF_SIZE),
batch_size=BATCH_SIZE)
#用于训练的数据提供器,每次从缓存中随机读取批次大小的数据
test_reader = paddle.batch(
paddle.reader.shuffle(paddle.dataset.mnist.test(),
buf_size=BUF_SIZE),
batch_size=BATCH_SIZE)
#用于打印,查看mnist数据
train_data=paddle.dataset.mnist.train();
sampledata=next(train_data())
print(sampledata)
# 定义多层感知器
def multilayer_perceptron(input):
# 第一个全连接层,激活函数为ReLU
hidden1 = fluid.layers.fc(input=input, size=100, act='relu')
# 第二个全连接层,激活函数为ReLU
hidden2 = fluid.layers.fc(input=hidden1, size=100, act='relu')
# 以softmax为激活函数的全连接输出层,输出层的大小必须为数字的个数10
prediction = fluid.layers.fc(input=hidden2, size=10, act='softmax')
return prediction
# 输入的原始图像数据,大小为1*28*28
image = fluid.layers.data(name='image', shape=[1, 28, 28], dtype='float32')#单通道,28*28像素值
# 标签,名称为label,对应输入图片的类别标签
label = fluid.layers.data(name='label', shape=[1], dtype='int64') #图片标签
# 获取分类器
predict = multilayer_perceptron(image)
#使用交叉熵损失函数,描述真实样本标签和预测概率之间的差值
cost = fluid.layers.cross_entropy(input=predict, label=label)
# 使用类交叉熵函数计算predict和label之间的损失函数
avg_cost = fluid.layers.mean(cost)
# 计算分类准确率
acc = fluid.layers.accuracy(input=predict, label=label)
#使用Adam算法进行优化, learning_rate 是学习率(它的大小与网络的训练收敛速度有关系)
optimizer = fluid.optimizer.AdamOptimizer(learning_rate=0.001)
opts = optimizer.minimize(avg_cost)
# 定义使用CPU还是GPU,使用CPU时use_cuda = False,使用GPU时use_cuda = True
use_cuda = False
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
# 获取测试程序
test_program = fluid.default_main_program().clone(for_test=True)
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
feeder = fluid.DataFeeder(place=place, feed_list=[image, label])
all_train_iter=0
all_train_iters=[]
all_train_costs=[]
all_train_accs=[]
def draw_train_process(title,iters,costs,accs,label_cost,lable_acc):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel("cost/acc", fontsize=20)
plt.plot(iters, costs,color='red',label=label_cost)
plt.plot(iters, accs,color='green',label=lable_acc)
plt.legend()
plt.grid()
plt.show()
EPOCH_NUM=2
model_save_dir = "/home/aistudio/work/my_inference_model"
for pass_id in range(EPOCH_NUM):
# 进行训练
for batch_id, data in enumerate(train_reader()): #遍历train_reader
train_cost, train_acc = exe.run(program=fluid.default_main_program(),#运行主程序
feed=feeder.feed(data), #给模型喂入数据
fetch_list=[avg_cost, acc]) #fetch 误差、准确率
all_train_iter=all_train_iter+BATCH_SIZE
all_train_iters.append(all_train_iter)
all_train_costs.append(train_cost[0])
all_train_accs.append(train_acc[0])
# 每200个batch打印一次信息 误差、准确率
if batch_id % 200 == 0:
print('Pass:%d, Batch:%d, Cost:%0.5f, Accuracy:%0.5f' %
(pass_id, batch_id, train_cost[0], train_acc[0]))
# 进行测试
test_accs = []
test_costs = []
#每训练一轮 进行一次测试
for batch_id, data in enumerate(test_reader()): #遍历test_reader
test_cost, test_acc = exe.run(program=test_program, #执行训练程序
feed=feeder.feed(data), #喂入数据
fetch_list=[avg_cost, acc]) #fetch 误差、准确率
test_accs.append(test_acc[0]) #每个batch的准确率
test_costs.append(test_cost[0]) #每个batch的误差
# 求测试结果的平均值
test_cost = (sum(test_costs) / len(test_costs)) #每轮的平均误差
test_acc = (sum(test_accs) / len(test_accs)) #每轮的平均准确率
print('Test:%d, Cost:%0.5f, Accuracy:%0.5f' % (pass_id, test_cost, test_acc))
#保存模型
# 如果保存路径不存在就创建
if not os.path.exists(model_save_dir):
os.makedirs(model_save_dir)
print ('save models to %s' % (model_save_dir))
fluid.io.save_inference_model(model_save_dir, #保存推理model的路径
['image'], #推理(inference)需要 feed 的数据
[predict], #保存推理(inference)结果的 Variables
exe) #executor 保存 inference model
print('训练模型保存完成!')
draw_train_process("training",all_train_iters,all_train_costs,all_train_accs,"trainning cost","trainning acc")
三、转换成Paddle Serving模型
from paddle_serving_client.io import inference_model_to_serving
inference_model_dir = "./work/my_inference_model"
serving_client_dir = "./work/serving_client_dir"
serving_server_dir = "./work/serving_server_dir"
feed_var_names, fetch_var_names = inference_model_to_serving(
inference_model_dir, serving_server_dir,serving_client_dir)
四、利用docker+paddle_serving部署模型
1.获取镜像并创建容器:
docker pull hub.baidubce.com/paddlepaddle/serving:latest
docker run -p 9292:9292 --name test -dit hub.baidubce.com/paddlepaddle/serving:latest
docker exec -it test bash
2.把转换后的模型上传到docker里后运行如下代码开启服务:
python -m paddle_serving_server.serve --model ./serving_server_dir/ --thread 10 --port 9292 &
五、结果测试
from paddle_serving_client import Client
import matplotlib.image as mpimg
client = Client()
client.load_client_config("./work/serving_client_dir/serving_client_conf.prototxt")
client.connect(["122.51.131.21:9292"])
fetch_map = client.predict(feed={"image": im}, fetch=["fc_5.tmp_2"])
# print(fetch_map)
lab=fetch_map['fc_5.tmp_2']
plt.figure(figsize=(5,5))
img = mpimg.imread("./work/test.jpg")
plt.imshow(img)
plt.axis('off')
plt.show()
print("该图片的预测结果的label为: %d" % np.argmax(lab))