一、序列化器中的类属性字段
- 序列化中所定义的类属性字段,一般情况下与模型类字段相对应
- 默认情况下,这些类属性字段既可以进行序列化输出,也可以进行反序列化输入
- 不需要输入(反序列化)、输出(序列化)的字段,则不需要定义
- 只需要反序列化输入,则定义
write_only = True - 只需要序列化输出,则定义
read_only = True - 响应的参数如果是多个查询集,需要在
JsonResponse()中传参many=True
二、类属性字段的参数
- 1.通用参数
read_only = True:当前字段只能进行序列化输出(用于不需要反序列化输入的字段)
write_only = True:当前字段只能进行反序列化输入,不进行序列化输出
required = True:在反序列化时是必填字段,默认为True
allow_null = False:当前字段是否允许传None,默认是False(必填字段False,反之则True)
allow_blank = False:当前字段是否运行为空,默认是False(必填字段False,反之则True)
default = xx:指定在反序列化时,当前字段没值时所使用的默认值
validators=校验器:当前字段所使用的校验器(下面介绍常用的)
error_messages:包含错误key-value的字段(下面会举例)
label:当前字段在前端的api页面中所显示的字段名称 - 2.选项参数
max_length:字段最大长度
min_length:字段最小长度
trim_whitespace:是否截断空字符串
max_value:字段最大值
min_value:字段最小值
三、反序列化_校验机制
- 调用序列化器对象的
is_valid()方法,校验前端参数的正确性,不调用则不校验 - 校验成功返回
True、校验失败返回False -
is_valid(raise_exception = True):校验失败后,则抛出异常 - 当调用
is_valid()之后,才能调用序列化器对象的errors属性,内容为校验的错误提示(dict) - 在
views.py中,如果传参进行了输入反序列化的话,那么需要调用的是经过校验后的数据,比如说新增数据,应该是:xxx类.objects.create(**serializer.validated_data)
try:
# 不符合规则则抛出错误
serializer.is_valid(raise_exception=True)
except Exception as e:
# 返回序列化器原有的dict类型的错误信息
return JsonResponse(serializer.errors)
四、rest_framework的校验器(用于validators=校验器)
rest_framework.framework中有有多个验证器,这里用其中一个最常见的UniqueValidator唯一验证器示例,更多见:https://juejin.im/post/5aa93246518825555c1d5bba
UniqueValidator唯一校验器
该验证器可用于在模型字段上强制实施 unique=True 约束。它需要一个必需的参数和一个可选的 messages 参数:
1.queryset 必须 - 这是校验唯一性的查询集,一般是模型类.objects.all()
2.message - 校验失败时使用的错误消息
3.lookup - 用于查找已校验值的现有实例。默认为 'exact'例子:修改之前的
serializer.py,对name字段使用UniqueValidator唯一校验器
from rest_framework import serializers
# from login.serializer import UserModelSerializer
from rest_framework.viewsets import ModelViewSet
from login.models import User
from rest_framework.validators import UniqueValidator
class UserSerializer(serializers.Serializer):
"""
该验证器可用于在模型字段上强制实施 unique=True 约束。它需要一个必需的参数和一个可选的 messages 参数:
queryset 必须 - 这是验证唯一性的查询集。
message - 验证失败时使用的错误消息。
lookup - 用于查找已验证值的现有实例。默认为 'exact'
"""
name = serializers.CharField(label='用户名', max_length=128, min_length = 10, help_text='用户名',
validators=[
UniqueValidator(
queryset=User.objects.all(),
message="该用户名已存在"
)
],
error_messages = {
## 键值对,对应上面的限制条件,以及对应的提示
"max_length":"最长128个字符",
"min_length ":"最短10个字符"
}
)
password = serializers.CharField(label='账号密码', max_length=256, help_text='账号密码', )
email = serializers.EmailField(label='账号密码', max_length=128, help_text='账号密码',
allow_null=True, allow_blank=True, default='')
sex = serializers.CharField(label='账号密码', max_length=128, help_text='账号密码', )
c_time = serializers.DateTimeField(label='创建时间', help_text='创建时间', read_only=True)
- 结果
1.这里使用httpie工具的一个传输json文件为参数的技巧
a.创建一个名为user.json的文件,内容如下:
{
"name": "张三",
"password": "qw123ssd的",
"email": "[email protected]",
"sex": "男"
}
b.在项目路径使用httpie的命令:http POST http://127.0.0.1:8000/users/ < test/user.json
c.结果:

五、自定义校验器
- 注意
1.如果自定义校验器中定义的字段,是在所调用的序列化类中所调用的模型类是没有定义的字段。那么就是相当于在模型类的基础上对字段进行了拓展,并且要在class Meta的fields = ('拓展字段',)中定义上,不然就会报错(关于ModelSerializer下篇讲)
2.如果一个字段有两个校验器,分别是框架自带的、自定义的,那么会优先校验框架自带的,如果框架自带的没通过,还会再去校验自定义的校验器,但是不会去进行单字段校验和联合字段的校验;如果两个校验器都通过了,才会去进行单字段校验和联合字段的校验 - 在
views.py的序列化类上面,添加一个自定义校验器函数。
比如校验用户名需要含有'用户'两个字:
def is_unique_user_name(name):
if '用户' not in name:
raise serializers,ValidationError('用户名称必须含有“用户”')
else:
return name
然后在下面的序列化类中这样调用(看注释):
from rest_framework import serializers
from rest_framework.viewsets import ModelViewSet
from login.models import User
from rest_framework.validators import UniqueValidator
class UserSerializer(serializers.Serializer):
name = serializers.CharField(label='用户名', max_length=128, help_text='用户名',
validators=[
UniqueValidator(
queryset=User.objects.all(),
message="该用户名已存在"
),
is_unique_user_name # 在这里调用自定义校验器
])
### 下面内容省略
六、自定义校验字段级别单个字段的校验
如果想要对某个特定的字段机械能自定义的验证规则,那么可以在所写的Serializer子类中,添加validate_的方法来指定自定义该字段的验证
-
validate_方法需要返回一个验证过的数据,或者抛出一个serializers.ValidationError异常 - 例子,修改
serializer.py文件
from rest_framework import serializers
from rest_framework.viewsets import ModelViewSet
from login.models import User
from rest_framework.validators import UniqueValidator
class UserSerializer(serializers.Serializer):
# 自定义字段级别的验证
def validate_name(self, value):
"""
用户名需要以“用户”开头
:return:
"""
if not str(value).startswith('用户'):
# 抛出erializers.ValidationError异常
raise serializers.ValidationError(detail='用户名需要以用户两个字开头')
# 返回一个验证过的数据
else:
return attrs
## 下面内容无需修改
name = serializers.CharField(label='用户名', max_length=128, help_text='用户名',
validators=[
UniqueValidator(
queryset=User.objects.all(),
message="该用户名已存在"
)
])
password = serializers.CharField(label='账号密码', max_length=256, help_text='账号密码', )
email = serializers.EmailField(label='账号密码', max_length=128, help_text='账号密码',
allow_null=True, allow_blank=True, default='')
sex = serializers.CharField(label='账号密码', max_length=128, help_text='账号密码', )
c_time = serializers.DateTimeField(label='创建时间', help_text='创建时间', read_only=True)
-
传不是“用户”开头的name:
 验证失败
验证失败 -
传以“用户”开头的name:(json数据中,email打错了,所以email值为空)
 验证成功,创建user
验证成功,创建user
七、自定义验证字段级别多个字段的验证
单个字段的校验,走的是validate_方法
多个字段的组合校验,走的是validate方法
- 和
validate_方法一样,validate方法也是在在所写的Serializer子类中,添加validate方法方法,进行自定义多个字段的验证 - 例子,在
serializer.py文件中的Serializer子类添加这个方法,其他不变
# 自定义多个字段的组合验证规则
def validate(self, attrs):
"""
password和email必需含有“lzl”这三个字母
:return:
"""
if "lzl" not in attrs['password'] or "lzl" not in attrs['email']:
raise serializers.ValidationError(detail='password和email必需含有“lzl”这三个字母')
else:
return attrs
-
传不符合规则的参数
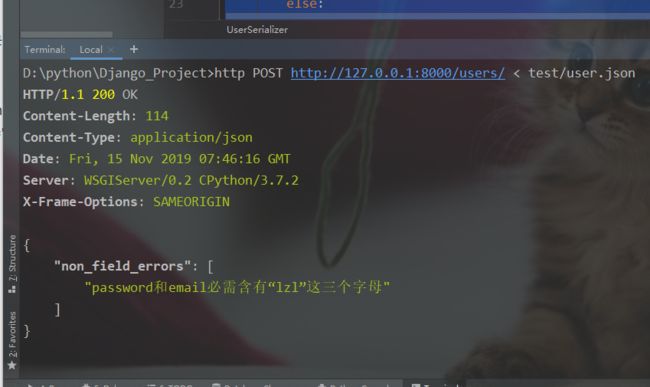 校验不通过
校验不通过 -
传符合规则的参数
 校验通过,创建user
校验通过,创建user
七、校验器的顺序
- 顺序如下:
1.首先是进行字段定义时所设置的限制条件(包含validators的列表条目),从左到右开始校验
2.然后到单字段validators_filename方法的校验
3.接着到多字段validators方法的校验 - 校验失败的逻辑:
1.不管前面的校验是否成功,“进行字段定义时所设置的限制条件(包含validators的列表条目)”的条件都将全部进行校验;如果都失败,则对应的失败提示都会进行响应
2.如果步骤1的校验都失败,就不会进行单字段和多字段的校验
八、优化views.py的代码
在之前的代码中,操作数据库的代码是放在views方法中。那么,是否可以放到序列化器中呢?这样在调用序列化器时,就能跟着对数据库进行对应的操作,比如:create、update操作
1.优化的前提,需了解
- 在
views.py的方法中,创建序列化器对象时,如果只传参data,那么在调用save()方法时,实际上调用的是序列化器对象的create()方法 - 在
views.py的方法中,创建序列化器对象时,如果传参data和instance,那么在调用save()方法时,实际上调用的是序列化器对象的update()方法
2.基于上面,可进行的优化
1.可重写序列化器对象的create()方法,从而优化views.py中的新增方法
2.可重写序列化器对象的update()方法,从而优化views.py中的修改方法
- 1.重写序列化器对象
UserSerializer的create()和update()方法
def create(self, validated_data):
"""
新增user
:param validated_data:
:return:
"""
return User.objects.create(**validated_data)
# 如果在创建UserSerializer对象时,传参data和instance,则在调用save()方法时,
# 实际调用的是序列化器对象中的update()方法
def update(self, instance, validated_data):
"""
更新user
:param instance:
:param validated_data:
:return:
"""
instance.name = validated_data['name']
instance.password = validated_data['password']
instance.email = validated_data['email']
instance.sex = validated_data['sex']
# instance.c_time = validated_data['c_time'] # 这个字段只读,不进行反序列化,所以注释
instance.save()
return instance
- 2.优化
views.py的新增和修改方法
a.新增方法
class Users(View):
def post(self, request):
"""V1.3"""
user_dict = json.loads(request.body.decode('utf8'), encoding='utf8')
# 实例化序列化器,只给data传值
serializer = UserSerializer(data=user_dict)
try:
serializer.is_valid(raise_exception=True)
except Exception as e:
return JsonResponse(serializer.errors)
serializer.save() # 这里实际调用的是序列化器的create方法
return JsonResponse(serializer.data, status=201)
b.修改方法
class UserDetail(View):
def put(self, request, pk):
"""V1.2"""
old_user = User.objects.get(id=pk)
user_dict = json.loads(request.body.decode('utf8'), encoding='utf8')
# 实例化序列化器,给instance和data传值(instance:需要修改的模型类对象、data:前端传来的修改数据,需进行反序列化和序列化)
serializer = UserSerializer(instance=old_user, data=user_dict)
try:
serializer.is_valid(raise_exception=True)
except Exception as e:
raise JsonResponse(serializer.errors)
serializer.save() # 实际调用的是序列化器的update方法
return JsonResponse(serializer.data, status=201)
-
3.结果
a.新增方法
 新增成功
新增成功
b.修改方法
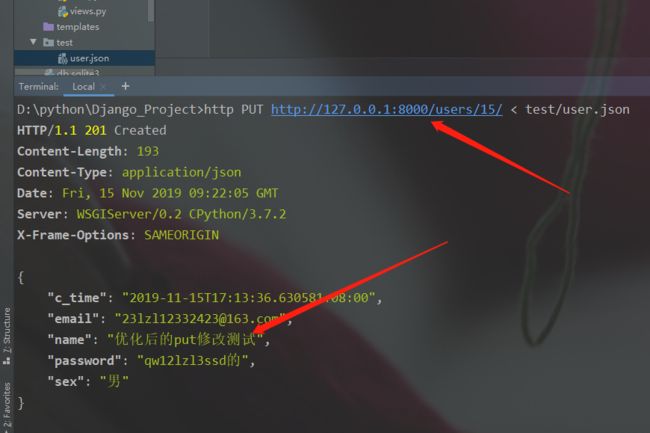 修改成功
修改成功