python爬虫学习教程,用python爬取新浪微博数据
爬取新浪微博信息,并写入csv/txt文件,文件名为目标用户id加".csv"和".txt"的形式,同时还会下载该微博原始图片(可选)。
运行环境
- 开发语言:python2/python3
- 系统: Windows/Linux/macOS
以爬取迪丽热巴的微博为例,她的微博昵称为"Dear-迪丽热巴",id为1669879400(后面会讲如何获取用户id)。我们选择爬取她的原创微博。程序会自动生成一个weibo文件夹,我们以后爬取的所有微博都被存储在这里。然后程序在该文件夹下生成一个名为"Dear-迪丽热巴"的文件夹,迪丽热巴的所有微博爬取结果都在这里。"Dear-迪丽热巴"文件夹里包含一个csv文件、一个txt文件和一个img文件夹,img文件夹用来存储下载到的图片。
csv文件结果如下所示:
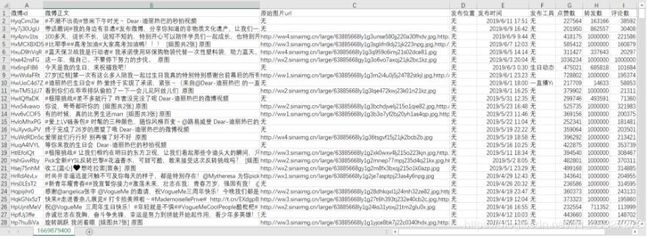
txt文件结果如下所示:
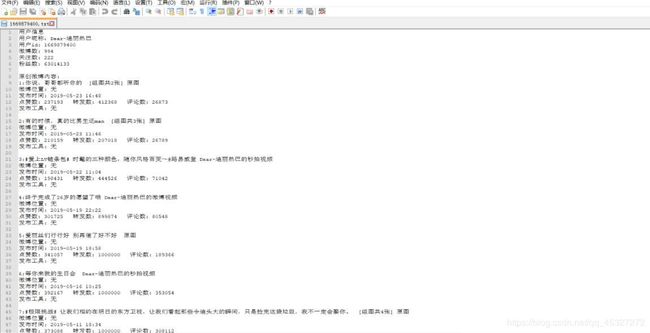
下载的图片如下所示:

img文件夹
本次下载了766张图片,大小一共1.15GB,包括她原创微博中的图片和转发微博转发理由中的图片。图片名为yyyymmdd+微博id的形式,若某条微博存在多张图片,则图片名中还会包括它在微博图片中的序号。本次下载有一张图片因为超时没有下载下来,该图片url被写到了not_downloaded_pictures.txt。
源码分享:
'''
在学习过程中有什么不懂得可以加我的
python学习交流扣扣qun,934109170
群里有不错的学习教程、开发工具与电子书籍。
与你分享python企业当下人才需求及怎么从零基础学习好python,和学习什么内容。
'''
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import codecs
import csv
import os
import random
import re
import sys
import traceback
from collections import OrderedDict
from datetime import datetime, timedelta
from time import sleep
import requests
from lxml import etree
from tqdm import tqdm
class Weibo(object):
cookie = {'Cookie': 'your cookie'} # 将your cookie替换成自己的cookie
def __init__(self, user_id, filter=0, pic_download=0):
"""Weibo类初始化"""
if not isinstance(user_id, int):
sys.exit(u'user_id值应为一串数字形式,请重新输入')
if filter != 0 and filter != 1:
sys.exit(u'filter值应为0或1,请重新输入')
if pic_download != 0 and pic_download != 1:
sys.exit(u'pic_download值应为0或1,请重新输入')
self.user_id = user_id # 用户id,即需要我们输入的数字,如昵称为"Dear-迪丽热巴"的id为1669879400
self.filter = filter # 取值范围为0、1,程序默认值为0,代表要爬取用户的全部微博,1代表只爬取用户的原创微博
self.pic_download = pic_download # 取值范围为0、1,程序默认值为0,代表不下载微博原始图片,1代表下载
self.nickname = '' # 用户昵称,如“Dear-迪丽热巴”
self.weibo_num = 0 # 用户全部微博数
self.got_num = 0 # 爬取到的微博数
self.following = 0 # 用户关注数
self.followers = 0 # 用户粉丝数
self.weibo = [] # 存储爬取到的所有微博信息
def deal_html(self, url):
"""处理html"""
try:
html = requests.get(url, cookies=self.cookie).content
selector = etree.HTML(html)
return selector
except Exception as e:
print('Error: ', e)
traceback.print_exc()
def deal_garbled(self, info):
"""处理乱码"""
try:
info = (info.xpath('string(.)').replace(u'\u200b', '').encode(
sys.stdout.encoding, 'ignore').decode(sys.stdout.encoding))
return info
except Exception as e:
print('Error: ', e)
traceback.print_exc()
def get_nickname(self):
"""获取用户昵称"""
try:
url = 'https://weibo.cn/%d/info' % (self.user_id)
selector = self.deal_html(url)
nickname = selector.xpath('//title/text()')[0]
self.nickname = nickname[:-3]
if self.nickname == u'登录 - 新' or self.nickname == u'新浪':
sys.exit(u'cookie错误或已过期,请按照README中方法重新获取')
print(u'用户昵称: ' + self.nickname)
except Exception as e:
print('Error: ', e)
traceback.print_exc()
def get_user_info(self, selector):
"""获取用户昵称、微博数、关注数、粉丝数"""
try:
self.get_nickname() # 获取用户昵称
user_info = selector.xpath("//div[@class='tip2']/*/text()")
self.weibo_num = int(user_info[0][3:-1])
print(u'微博数: ' + str(self.weibo_num))
self.following = int(user_info[1][3:-1])
print(u'关注数: ' + str(self.following))
self.followers = int(user_info[2][3:-1])
print(u'粉丝数: ' + str(self.followers))
print('*' * 100)
except Exception as e:
print('Error: ', e)
traceback.print_exc()
def get_page_num(self, selector):
"""获取微博总页数"""
try:
if selector.xpath("//input[@name='mp']") == []:
page_num = 1
else:
page_num = (int)(
selector.xpath("//input[@name='mp']")[0].attrib['value'])
return page_num
except Exception as e:
print('Error: ', e)
traceback.print_exc()
def get_long_weibo(self, weibo_link):
"""获取长原创微博"""
try:
selector = self.deal_html(weibo_link)
info = selector.xpath("//div[@class='c']")[1]
wb_content = self.deal_garbled(info)
wb_time = info.xpath("//span[@class='ct']/text()")[0]
weibo_content = wb_content[wb_content.find(':') +
1:wb_content.rfind(wb_time)]
return weibo_content
except Exception as e:
print('Error: ', e)
traceback.print_exc()
def get_original_weibo(self, info, weibo_id):
"""获取原创微博"""
try:
weibo_content = self.deal_garbled(info)
weibo_content = weibo_content[:weibo_content.rfind(u'赞')]
a_text = info.xpath('div//a/text()')
if u'全文' in a_text:
weibo_link = 'https://weibo.cn/comment/' + weibo_id
wb_content = self.get_long_weibo(weibo_link)
if wb_content:
weibo_content = wb_content
return weibo_content
except Exception as e:
print('Error: ', e)
traceback.print_exc()
def get_long_retweet(self, weibo_link):
"""获取长转发微博"""
try:
wb_content = self.get_long_weibo(weibo_link)
weibo_content = wb_content[:wb_content.rfind(u'原文转发')]
return weibo_content
except Exception as e:
print('Error: ', e)
traceback.print_exc()
def get_retweet(self, info, weibo_id):
"""获取转发微博"""
try:
original_user = info.xpath("div/span[@class='cmt']/a/text()")
if not original_user:
wb_content = u'转发微博已被删除'
return wb_content
else:
original_user = original_user[0]
wb_content = self.deal_garbled(info)
wb_content = wb_content[wb_content.find(':') +
1:wb_content.rfind(u'赞')]
wb_content = wb_content[:wb_content.rfind(u'赞')]
a_text = info.xpath('div//a/text()')
if u'全文' in a_text:
weibo_link = 'https://weibo.cn/comment/' + weibo_id
weibo_content = self.get_long_retweet(weibo_link)
if weibo_content:
wb_content = weibo_content
retweet_reason = self.deal_garbled(info.xpath('div')[-1])
retweet_reason = retweet_reason[:retweet_reason.rindex(u'赞')]
wb_content = (retweet_reason + '\n' + u'原始用户: ' + original_user +
'\n' + u'转发内容: ' + wb_content)
return wb_content
except Exception as e:
print('Error: ', e)
traceback.print_exc()
def is_original(self, info):
"""判断微博是否为原创微博"""
is_original = info.xpath("div/span[@class='cmt']")
if len(is_original) > 3:
return False
else:
return True
def get_weibo_content(self, info, is_original):
"""获取微博内容"""
try:
weibo_id = info.xpath('@id')[0][2:]
if is_original:
weibo_content = self.get_original_weibo(info, weibo_id)
else:
weibo_content = self.get_retweet(info, weibo_id)
print(weibo_content)
return weibo_content
except Exception as e:
print('Error: ', e)
traceback.print_exc()
def get_publish_place(self, info):
"""获取微博发布位置"""
try:
div_first = info.xpath('div')[0]
a_list = div_first.xpath('a')
publish_place = u'无'
for a in a_list:
if ('place.weibo.com' in a.xpath('@href')[0]
and a.xpath('text()')[0] == u'显示地图'):
weibo_a = div_first.xpath("span[@class='ctt']/a")
if len(weibo_a) >= 1:
publish_place = weibo_a[-1]
if (u'视频' == div_first.xpath(
"span[@class='ctt']/a/text()")[-1][-2:]):
if len(weibo_a) >= 2:
publish_place = weibo_a[-2]
else:
publish_place = u'无'
publish_place = self.deal_garbled(publish_place)
break
print(u'微博发布位置: ' + publish_place)
return publish_place
except Exception as e:
print('Error: ', e)
traceback.print_exc()
def get_publish_time(self, info):
"""获取微博发布时间"""
try:
str_time = info.xpath("div/span[@class='ct']")
str_time = self.deal_garbled(str_time[0])
publish_time = str_time.split(u'来自')[0]
if u'刚刚' in publish_time:
publish_time = datetime.now().strftime('%Y-%m-%d %H:%M')
elif u'分钟' in publish_time:
minute = publish_time[:publish_time.find(u'分钟')]
minute = timedelta(minutes=int(minute))
publish_time = (datetime.now() -
minute).strftime('%Y-%m-%d %H:%M')
elif u'今天' in publish_time:
today = datetime.now().strftime('%Y-%m-%d')
time = publish_time[3:]
publish_time = today + ' ' + time
elif u'月' in publish_time:
year = datetime.now().strftime('%Y')
month = publish_time[0:2]
day = publish_time[3:5]
time = publish_time[7:12]
publish_time = year + '-' + month + '-' + day + ' ' + time
else:
publish_time = publish_time[:16]
print(u'微博发布时间: ' + publish_time)
return publish_time
except Exception as e:
print('Error: ', e)
traceback.print_exc()
def get_publish_tool(self, info):
"""获取微博发布工具"""
try:
str_time = info.xpath("div/span[@class='ct']")
str_time = self.deal_garbled(str_time[0])
if len(str_time.split(u'来自')) > 1:
publish_tool = str_time.split(u'来自')[1]
else:
publish_tool = u'无'
print(u'微博发布工具: ' + publish_tool)
return publish_tool
except Exception as e:
print('Error: ', e)
traceback.print_exc()
def get_weibo_footer(self, info):
"""获取微博点赞数、转发数、评论数"""
try:
footer = {}
pattern = r'\d+'
str_footer = info.xpath('div')[-1]
str_footer = self.deal_garbled(str_footer)
str_footer = str_footer[str_footer.rfind(u'赞'):]
weibo_footer = re.findall(pattern, str_footer, re.M)
up_num = int(weibo_footer[0])
print(u'点赞数: ' + str(up_num))
footer['up_num'] = up_num
retweet_num = int(weibo_footer[1])
print(u'转发数: ' + str(retweet_num))
footer['retweet_num'] = retweet_num
comment_num = int(weibo_footer[2])
print(u'评论数: ' + str(comment_num))
footer['comment_num'] = comment_num
return footer
except Exception as e:
print('Error: ', e)
traceback.print_exc()
def extract_picture_urls(self, info, weibo_id):
"""提取微博原始图片url"""
try:
a_list = info.xpath('div/a/@href')
first_pic = 'https://weibo.cn/mblog/pic/' + weibo_id + '?rl=0'
all_pic = 'https://weibo.cn/mblog/picAll/' + weibo_id + '?rl=1'
if first_pic in a_list:
if all_pic in a_list:
selector = self.deal_html(all_pic)
preview_picture_list = selector.xpath('//img/@src')
picture_list = [
p.replace('/thumb180/', '/large/')
for p in preview_picture_list
]
picture_urls = ','.join(picture_list)
else:
if info.xpath('.//img/@src'):
preview_picture = info.xpath('.//img/@src')[-1]
picture_urls = preview_picture.replace(
'/wap180/', '/large/')
else:
sys.exit(
u"爬虫微博可能被设置成了'不显示图片',请前往"
u"'https://weibo.cn/account/customize/pic',修改为'显示'"
)
else:
picture_urls = '无'
return picture_urls
except Exception as e:
print('Error: ', e)
traceback.print_exc()
def get_picture_urls(self, info, is_original):
"""获取微博原始图片url"""
try:
weibo_id = info.xpath('@id')[0][2:]
picture_urls = {}
if is_original:
original_pictures = self.extract_picture_urls(info, weibo_id)
picture_urls['original_pictures'] = original_pictures
if not self.filter:
picture_urls['retweet_pictures'] = '无'
else:
retweet_url = info.xpath("div/a[@class='cc']/@href")[0]
retweet_id = retweet_url.split('/')[-1].split('?')[0]
retweet_pictures = self.extract_picture_urls(info, retweet_id)
picture_urls['retweet_pictures'] = retweet_pictures
a_list = info.xpath('div[last()]/a/@href')
original_picture = '无'
for a in a_list:
if a.endswith(('.gif', '.jpeg', '.jpg', '.png')):
original_picture = a
break
picture_urls['original_pictures'] = original_picture
return picture_urls
except Exception as e:
print('Error: ', e)
traceback.print_exc()
def download_pic(self, url, pic_path):
"""下载单张图片"""
try:
p = requests.get(url)
with open(pic_path, 'wb') as f:
f.write(p.content)
except Exception as e:
error_file = self.get_filepath(
'img') + os.sep + 'not_downloaded_pictures.txt'
with open(error_file, 'ab') as f:
url = url + '\n'
f.write(url.encode(sys.stdout.encoding))
print('Error: ', e)
traceback.print_exc()
def download_pictures(self):
"""下载微博图片"""
try:
print(u'即将进行图片下载')
img_dir = self.get_filepath('img')
for w in tqdm(self.weibo, desc=u'图片下载进度'):
if w['original_pictures'] != '无':
pic_prefix = w['publish_time'][:11].replace(
'-', '') + '_' + w['id']
if ',' in w['original_pictures']:
w['original_pictures'] = w['original_pictures'].split(
',')
for j, url in enumerate(w['original_pictures']):
pic_suffix = url[url.rfind('.'):]
pic_name = pic_prefix + '_' + str(j +
1) + pic_suffix
pic_path = img_dir + os.sep + pic_name
self.download_pic(url, pic_path)
else:
pic_suffix = w['original_pictures'][
w['original_pictures'].rfind('.'):]
pic_name = pic_prefix + pic_suffix
pic_path = img_dir + os.sep + pic_name
self.download_pic(w['original_pictures'], pic_path)
print(u'图片下载完毕,保存路径:')
print(img_dir)
except Exception as e:
print('Error: ', e)
traceback.print_exc()
def get_one_weibo(self, info):
"""获取一条微博的全部信息"""
try:
weibo = OrderedDict()
is_original = self.is_original(info)
if (not self.filter) or is_original:
weibo['id'] = info.xpath('@id')[0][2:]
weibo['content'] = self.get_weibo_content(info,
is_original) # 微博内容
picture_urls = self.get_picture_urls(info, is_original)
weibo['original_pictures'] = picture_urls[
'original_pictures'] # 原创图片url
if not self.filter:
weibo['retweet_pictures'] = picture_urls[
'retweet_pictures'] # 转发图片url
weibo['original'] = is_original # 是否原创微博
weibo['publish_place'] = self.get_publish_place(info) # 微博发布位置
weibo['publish_time'] = self.get_publish_time(info) # 微博发布时间
weibo['publish_tool'] = self.get_publish_tool(info) # 微博发布工具
footer = self.get_weibo_footer(info)
weibo['up_num'] = footer['up_num'] # 微博点赞数
weibo['retweet_num'] = footer['retweet_num'] # 转发数
weibo['comment_num'] = footer['comment_num'] # 评论数
else:
weibo = None
return weibo
except Exception as e:
print('Error: ', e)
traceback.print_exc()
def get_one_page(self, page):
"""获取第page页的全部微博"""
try:
url = 'https://weibo.cn/u/%d?page=%d' % (self.user_id, page)
selector = self.deal_html(url)
info = selector.xpath("//div[@class='c']")
is_exist = info[0].xpath("div/span[@class='ctt']")
if is_exist:
for i in range(0, len(info) - 2):
weibo = self.get_one_weibo(info[i])
if weibo:
self.weibo.append(weibo)
self.got_num += 1
print('-' * 100)
except Exception as e:
print('Error: ', e)
traceback.print_exc()
def get_filepath(self, type):
"""获取结果文件路径"""
try:
file_dir = os.path.split(os.path.realpath(
__file__))[0] + os.sep + 'weibo' + os.sep + self.nickname
if type == 'img':
file_dir = file_dir + os.sep + 'img'
if not os.path.isdir(file_dir):
os.makedirs(file_dir)
if type == 'img':
return file_dir
file_path = file_dir + os.sep + '%d' % self.user_id + '.' + type
return file_path
except Exception as e:
print('Error: ', e)
traceback.print_exc()
def write_csv(self, wrote_num):
"""将爬取的信息写入csv文件"""
try:
result_headers = [
'微博id',
'微博正文',
'原始图片url',
'发布位置',
'发布时间',
'发布工具',
'点赞数',
'转发数',
'评论数',
]
if not self.filter:
result_headers.insert(3, '被转发微博原始图片url')
result_headers.insert(4, '是否为原创微博')
result_data = [w.values() for w in self.weibo][wrote_num:]
if sys.version < '3': # python2.x
reload(sys)
sys.setdefaultencoding('utf-8')
with open(self.get_filepath('csv'), 'ab') as f:
f.write(codecs.BOM_UTF8)
writer = csv.writer(f)
if wrote_num == 0:
writer.writerows([result_headers])
writer.writerows(result_data)
else: # python3.x
with open(self.get_filepath('csv'),
'a',
encoding='utf-8-sig',
newline='') as f:
writer = csv.writer(f)
if wrote_num == 0:
writer.writerows([result_headers])
writer.writerows(result_data)
print(u'%d条微博写入csv文件完毕,保存路径:' % self.got_num)
print(self.get_filepath('csv'))
except Exception as e:
print('Error: ', e)
traceback.print_exc()
def write_txt(self, wrote_num):
"""将爬取的信息写入txt文件"""
try:
temp_result = []
if wrote_num == 0:
if self.filter:
result_header = u'\n\n原创微博内容: \n'
else:
result_header = u'\n\n微博内容: \n'
result_header = (u'用户信息\n用户昵称:' + self.nickname + u'\n用户id: ' +
str(self.user_id) + u'\n微博数: ' +
str(self.weibo_num) + u'\n关注数: ' +
str(self.following) + u'\n粉丝数: ' +
str(self.followers) + result_header)
temp_result.append(result_header)
for i, w in enumerate(self.weibo[wrote_num:]):
temp_result.append(
str(wrote_num + i + 1) + ':' + w['content'] + '\n' +
u'微博位置: ' + w['publish_place'] + '\n' + u'发布时间: ' +
w['publish_time'] + '\n' + u'点赞数: ' + str(w['up_num']) +
u' 转发数: ' + str(w['retweet_num']) + u' 评论数: ' +
str(w['comment_num']) + '\n' + u'发布工具: ' +
w['publish_tool'] + '\n\n')
result = ''.join(temp_result)
with open(self.get_filepath('txt'), 'ab') as f:
f.write(result.encode(sys.stdout.encoding))
print(u'%d条微博写入txt文件完毕,保存路径:' % self.got_num)
print(self.get_filepath('txt'))
except Exception as e:
print('Error: ', e)
traceback.print_exc()
def write_file(self, wrote_num):
"""写文件"""
if self.got_num > wrote_num:
self.write_csv(wrote_num)
self.write_txt(wrote_num)
def get_weibo_info(self):
"""获取微博信息"""
try:
url = 'https://weibo.cn/u/%d' % (self.user_id)
selector = self.deal_html(url)
self.get_user_info(selector) # 获取用户昵称、微博数、关注数、粉丝数
page_num = self.get_page_num(selector) # 获取微博总页数
wrote_num = 0
page1 = 0
random_pages = random.randint(1, 5)
for page in tqdm(range(1, page_num + 1), desc=u'进度'):
self.get_one_page(page) # 获取第page页的全部微博
if page % 20 == 0: # 每爬20页写入一次文件
self.write_file(wrote_num)
wrote_num = self.got_num
# 通过加入随机等待避免被限制。爬虫速度过快容易被系统限制(一段时间后限
# 制会自动解除),加入随机等待模拟人的操作,可降低被系统限制的风险。默
# 认是每爬取1到5页随机等待6到10秒,如果仍然被限,可适当增加sleep时间
if page - page1 == random_pages and page < page_num:
sleep(random.randint(6, 10))
page1 = page
random_pages = random.randint(1, 5)
self.write_file(wrote_num) # 将剩余不足20页的微博写入文件
if not self.filter:
print(u'共爬取' + str(self.got_num) + u'条微博')
else:
print(u'共爬取' + str(self.got_num) + u'条原创微博')
except Exception as e:
print('Error: ', e)
traceback.print_exc()
def start(self):
"""运行爬虫"""
try:
self.get_weibo_info()
print(u'信息抓取完毕')
print('*' * 100)
if self.pic_download == 1:
self.download_pictures()
except Exception as e:
print('Error: ', e)
traceback.print_exc()
def main():
try:
# 使用实例,输入一个用户id,所有信息都会存储在wb实例中
user_id = 1669879400 # 可以改成任意合法的用户id(爬虫的微博id除外)
filter = 1 # 值为0表示爬取全部微博(原创微博+转发微博),值为1表示只爬取原创微博
pic_download = 1 # 值为0代表不下载微博原始图片,1代表下载微博原始图片
wb = Weibo(user_id, filter, pic_download) # 调用Weibo类,创建微博实例wb
wb.start() # 爬取微博信息
print(u'用户昵称: ' + wb.nickname)
print(u'全部微博数: ' + str(wb.weibo_num))
print(u'关注数: ' + str(wb.following))
print(u'粉丝数: ' + str(wb.followers))
if wb.weibo:
print(u'最新/置顶 微博为: ' + wb.weibo[0]['content'])
print(u'最新/置顶 微博位置: ' + wb.weibo[0]['publish_place'])
print(u'最新/置顶 微博发布时间: ' + wb.weibo[0]['publish_time'])
print(u'最新/置顶 微博获得赞数: ' + str(wb.weibo[0]['up_num']))
print(u'最新/置顶 微博获得转发数: ' + str(wb.weibo[0]['retweet_num']))
print(u'最新/置顶 微博获得评论数: ' + str(wb.weibo[0]['comment_num']))
print(u'最新/置顶 微博发布工具: ' + wb.weibo[0]['publish_tool'])
except Exception as e:
print('Error: ', e)
traceback.print_exc()
if __name__ == '__main__':
main()注意事项
1.user_id不能为爬虫微博的user_id。因为要爬微博信息,必须先登录到某个微博账号,此账号我们姑且称为爬虫微博。爬虫微博访问自己的页面和访问其他用户的页面,得到的网页格式不同,所以无法爬取自己的微博信息;
2.cookie有期限限制,超过有效期需重新更新cookie。