深度学习part2:基于tensorflow2.0手写体识别初体验
文章目录
- 基于tensorflow2.0下的手写体识别初体验
- 1.手写体识别代码复现
- 2.部分代码流程介绍
- 3.手写体识别结果可视化
基于tensorflow2.0下的手写体识别初体验
1.手写体识别代码复现
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Flatten, Dense, Conv2D, MaxPooling2D, Dropout
from tensorflow.keras import datasets
#验证集一般用于进一步确定模型中的超参数(例如正则项系数、神经网络中隐层的节点个数,k值等)
#测试集只是用于评估模型的精确度(即泛化能力)
(train_images,train_labels),(test_images,test_labels) = datasets.mnist.load_data()#用于下载数据集
#数据处理
train_images = train_images.reshape(60000,28*28).astype('float32')/255#归一化
test_images = test_images.reshape(10000,28*28).astype('float32')/255
print(train_images.shape)
print('prediction:',train_labels[10000])
train_labels = tf.keras.utils.to_categorical(train_labels)#to_categorical指将整数类别转化成onehot类别
test_labels = tf.keras.utils.to_categorical(test_labels)
#建造模型
#Sequential指模型建造
#Dense指全连接层,输出512维,激励函数为relu,输入形式(28*28)格式
#第二个连接层输出256维
model = Sequential([Dense(512,activation='relu',input_shape=(28*28,)),
Dense(256,activation='relu'),
Dropout(0.4),#失活率,防止过拟合
Dense(10,activation='softmax')])#softmax指经过函数输出类别(acc的计算)
#categorical_crossentropy指多类区分的损失函数
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['acc'])
history = model.fit(train_images,train_labels,
epochs=10,batch_size=128,#训练十次,训练样本数量
validation_data=(test_images,test_labels))#validation_data可以获取更好的超参数,防止过拟合
#model.predict(test_images)
#model.predict_class(test_images)
model.evaluate(test_images, test_labels)
2.部分代码流程介绍
1.Keras
Keras是一个由Python编写的开源人工神经网络库,可以作为Tensorflow、Microsoft-CNTK和Theano的高阶应用程序接口,进行深度学习模型的设计、调试、评估、应用和可视化 。(详细介绍https://keras.io)
2.数据预处理(转载)
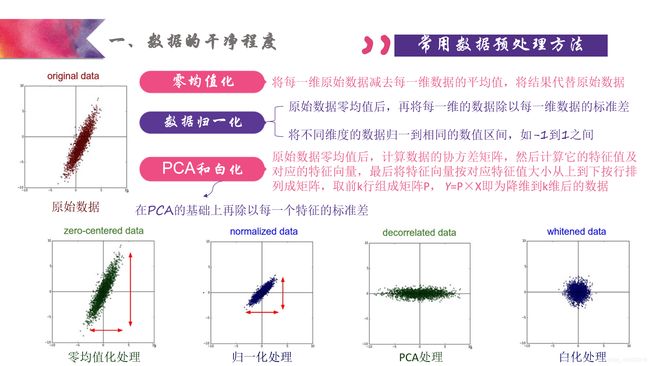
数据的加噪(本次代码由于下载数据集无需加噪,若是有兴趣自己制作数据集就需要加噪)
3.数据集图片及标签
- 打印图片格式


可见图片有784个特征点(故将它做成28*28)
- 图片内部
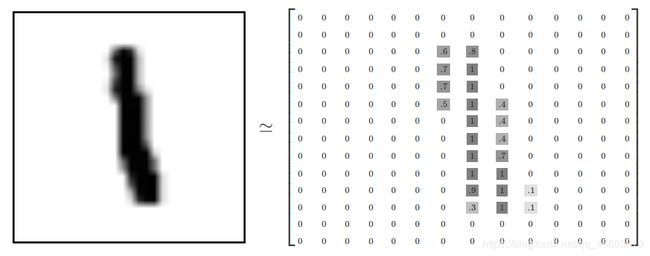
- 图片的标签(及它的预测值)
如果想将这样的分类数据转成我们习惯的0-9数字,可以使用TensorFlow中内置的函数argmax
train_labels = tf.argmax(mnist.train.labels, 1)
下面图片
![]()
4.建立模型(这里用到简单的全连接层模型,一般用卷积神经网络)
-
Dropout(用来防止过拟合,也叫失活率)
想更多了解可访问https://blog.csdn.net/program_developer/article/details/80737724 -
softmax(指分类的预测值及accuracy)
想更多了解可访问https://blog.csdn.net/bitcarmanlee/article/details/8232085
5.编译,训练,评估
代码里标注清楚了。
这里简答讲述一下model.evaluate和model.prediction的差异
model.evaluate需要输入数据及标签,通过预测结果和标签误差进行评估(建议)
model.prediction只需要输入数据,直接评估预测结果
3.手写体识别结果可视化
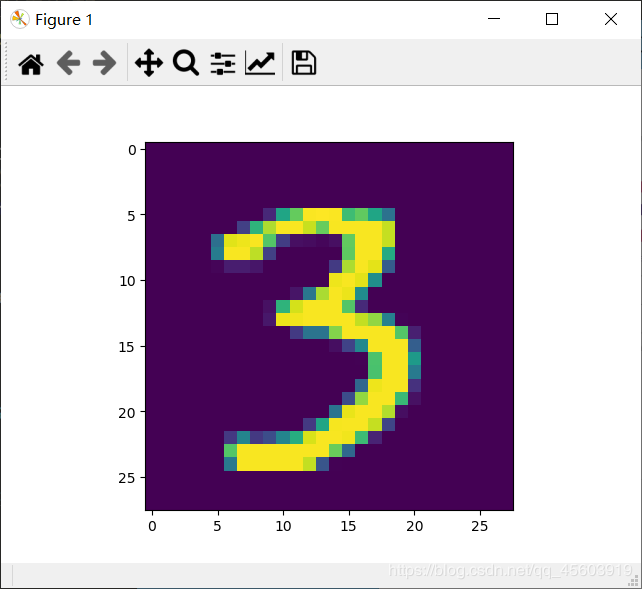
图片可视化(不太标准)
def plot_image(image):
image_file=plt.imshow(image.reshape(28,28))
plt.show(image_file)
plot_image(train_images[10000])
print(train_labels[10000])
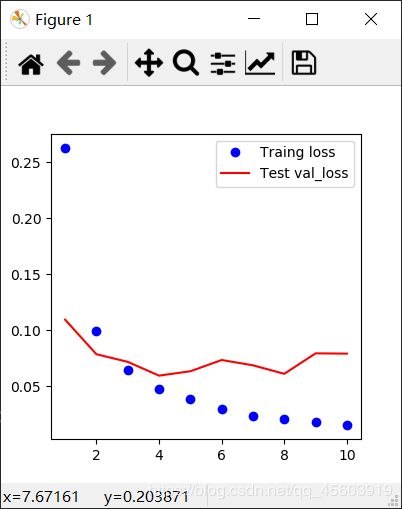
训练结果可视化(plt作图,部分转载)
# 结果可视化
acc = history.history.get('acc')
val_acc = history.history.get('val_acc')
loss = history.history.get('loss')
val_loss = history.history.get('val_loss')
epochs = range(1, len(acc)+1)
plt.figure(figsize=(4,4))
plt.plot(epochs, acc, 'bo', label='Traing acc')
plt.plot(epochs, val_acc, 'r', label='Test acc')
plt.legend()
plt.show()
plt.figure(figsize=(4,4))
plt.plot(epochs, loss, 'bo', label='Traing loss')
plt.plot(epochs, val_loss, 'r', label='Test val_loss')
plt.legend()
plt.show()
精度结果
这个模型精度基本可以稳定在0.995左右

损失函数结果
本文为作者学习记录笔记,可能有众多不足,望指出。谢谢!!!