行为识别(action recognition)技术趋势
计算机视觉领域的杰出学者Andrew Zisserman同Deepmind团队的技术讨论中对人类行为识别的技术趋势和Kinetics数据集的应用做了探讨分析,Andrew Zisserman其团队曾提出过名噪一时的VGG模型,在行为识别领域也有深入研究,因此其报告值得认真理解分析,现将其摘录整理如下,报告原题目为《Human action recognition and the Kinetics dataset》,报告分为三部分。
第一部分 Kinetics数据集
Kinetics数据集其完整名称为“Kinetics human action video dataset”,其中包含了各种人类行为,如下图所示为部分示例。建立这样一个数据库,其目的和建立ImageNet的初衷类似,主要为了给算法研究提供一个公共的平台。因此这个数据集也可以被称为ImageNet for human action recognition。其中包含的数据 1)已经经过了剪辑,即和内容无关的视频没有保留;2)视频中记录的都是人的行为;3)行为已经经过分类,具有类别标签。kinetics足够大,因此可以用于进行神经网络的架构设计与比较,另一个重要用途是它可以作为其它任务的预训练模型,例如在未剪辑过的视频中对行为在时序上进行定位。

截止到2018年,Kinetics数据集的参数分别如下,每段视频时长为10秒,每段视频都裁剪自不同的Yoube视频,对于每一类行为,在执行人、视角以及执行具体方式上都有较大的不同,即数据具有内在的多样性,这一点从上面的图例中也可能够看出。

行为类别中包含人独自的行为,例如挥手,眨眼,奔跑,跳跃等,如下图所示:


也包括人与人之间的交互,例如拥抱,亲吻,握手等,如下图所示:

此外,还有人与物体之间的交互,如开门,割草,洗碗等,如下图所示:



数据集通过如下流程建立:

和kinetics400相比,kinetcis600不仅类别数量从400类扩展到了600类,每类的数据也从400左右扩展到了600以上。另外在标签语义上更加精确,解耦了类别和查询文本之间的关系,例如"folding paper"还能匹配到"origami"以及"dobrar papel"(意)。kinetics600还拥有更多的只有身体的类别,如图所示:

拥有更多脸相关的类别

更多的手部类别

以及更多基础工具的使用(除图中所示外还有使用油漆滚轮、圆锯、扳手等)

此外和相似物体的行为也更多了

舞蹈类别变多

更多与随机的物品互动

在文献“Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset,Joao Carreira, Andrew Zisserman, CVPR 17”中,对比了各种神经网络在kinetics上的表现,并对Two-Stream I3D模型进行了详细介绍。

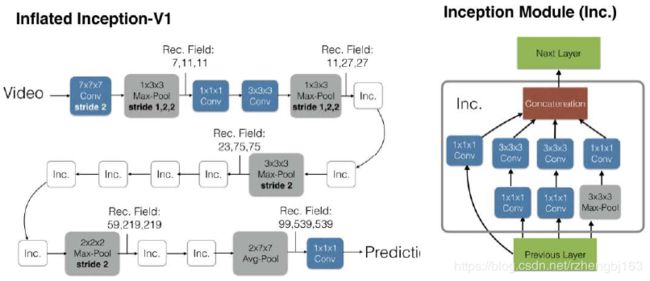

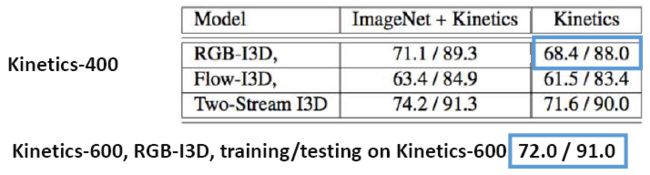
在文献“A Short Note about Kinetics-600 Authors: Joao Carreira, Eric Noland, Andras Banki-Horvath, Chloe Hillier, Andrew Zisserman, arXiv 2018”中作者对比了kinetics400和kinetics600上的效果,可见对于RGB-I3D来说,数据集的增大对识别效果的改善有较为明显影响。
第二部分 通过在Kinetics上预训练进行行为识别
性能评估在四个数据集上进行:
1. UCF-101 – 分类
2. HMD-51 – 分类
3. Charades – 时间定位
4. AVA – 时空定位
UCF101数据集示例

HMD-51 示例

两个数据集的统计信息如表所示


以上数据来自于actionrecognition.net
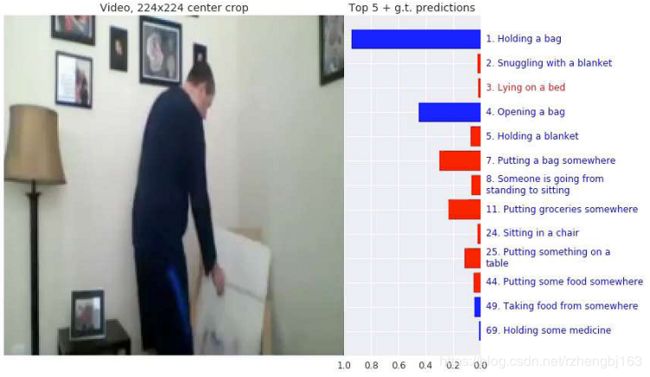
Charades数据集-行为定位,如图所示为其中一个例子(用kinetic400预训练过的I3D模型达到了当前最佳水平,赢得了CVPR 2017年的Charades挑战)
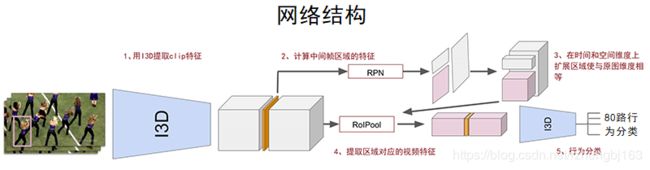
AVA(原子视觉行为)数据集,

AVA: A video dataset of spatio-temporally localized atomic visual actions, C. Gu, C. Sun, D. A. Ross, C. Vondrick, C. Pantofaru,Y. Li, S. Vijayanarasimhan, G. Toderici, S. Ricco, R. Sukthankar, C. Schmid, and J. Malik, CVPR 2018.
AVA中的80个原子行为:

AVA 2018 挑战赛
在空间/时间上定位原子行为,要求帧平均准确值 (mAP) > 0.5 重叠度(ioU),测试对象为来自131个视频源中的15分钟片段,每秒1关键帧(fps)

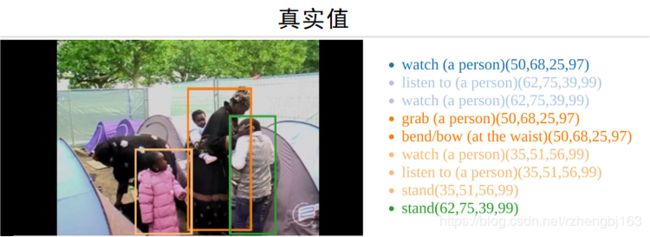

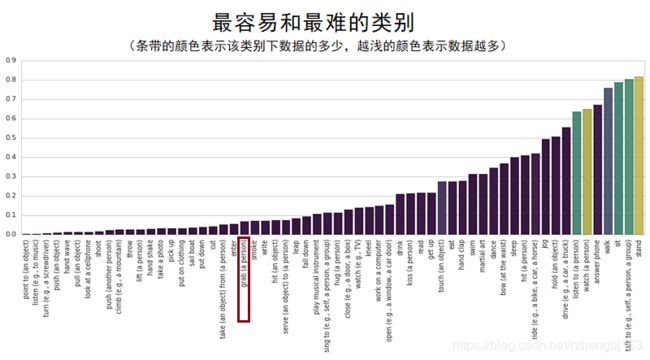
下图所示为最容易和最难的类别,其中grab这一类可以看到不算是最难的,但是在上面的预测中没有正确出现。
A Better Baseline for AVA, Rohit Girdhar, João Carreira, Carl Doersch, Andrew Zisserman, arXiv 2018
第三部分 行为识别未来发展
以下是Andrew Zisserman分享的一些思考,从视频源来说,对于帧的时间序列,如图所示,哪些对于识别行为是需要的?一个关键帧?一组无序的帧?有序的帧序列?……





K. Simonyan, A. Zisserman, "Two-Stream Convolutional Networks for Action Recognition in Videos", NIPS 2014
在Kinetics-400上取得的最好效果
Top-1精确度如下表所示

上述模型来自如下四篇论文
• Rethinking Spatiotemporal Feature Learning: Speed-Accuracy Trade-offs in Video Classification, Saining Xie, Chen Sun,
Jonathan Huang, Zhuowen Tu, Kevin Murphy, ECCV 2018
• Temporal segment networks: Towards good practices for deep action recognition, Wang, L., Xiong, Y.,Wang, Z., Qiao, Y., Lin. D., Tang, X., Van Gool, L., ECCV 2016
• Non-local Neural Networks, Xiaolong Wang, Ross Girshick, Abhinav Gupta, and Kaiming He, CVPR 2018
• Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset, Joao Carreira, Andrew Zisserman, CVPR 17
从上表可以看出:目前的性能上线大约为不到80%,增加光流大约可以提高3%左右的性能,可以得出结论,RGB模型仍然不能完整的学习到运动信息。
相关论文
What Makes a Video a Video: Analyzing Temporal Information in Video Understanding Models and Datasets De-An Huang, Vignesh Ramanathan, Dhruv Mahajan, Lorenzo Torresani, Manohar Paluri, Li Fei-Fei, and Juan Carlos Niebles, CVPR 2018。论文结论:C3D模型(使用16帧)是在没有利用运动信息的情况下识别kinetic400中35%的类别的。这即是说:或是模型不能从这些类别中学到运动信息,亦或是这些类别不需要运动信息也可以实现分类。
总结
当前这一代主流神经网络架构:并没有在kinetic上达到应有的效果,这一原因可能是因为没有充分学习到运动信息。这一领域还需要更多的创新……研究问题:如何开发能更有效学习到运动信息的网络架构?如何为行为识别开发更轻量级的架构?未来:Kinetics-800即将发布;针对Kinetics and AVA 挑战赛将举行研讨会。