Doris(原Palo)简介
写在前面:
Doris 由百度大数据部研发 ,之前叫百度 Palo,2018年贡献到 Apache 社区后,更名为 Doris 。
本博客主要从业务角度(我们为什么会选择使用它,如何用)来对Doris进行简要介绍。
1、Doris简介
Doris是一个MPP的OLAP系统,以较低的成本提供在大数据集上的高性能分析和报表查询功能。
MPP (Massively Parallel Processing),即大规模并行处理。简单来说,MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果(与Hadoop相似)。
注:
MPPDB与Hadoop都是将运算分布到节点中独立运算后进行结果合并(分布式计算),但由于依据的理论和采用的技术路线不同而有各自的优缺点和适用范围。我们现在大数据存储与处理趋势:MPPDB+Hadoop混搭使用,用MPP处理PB级别的、高质量的结构化数据,同时为应用提供丰富的SQL和事物支持能力;用Hadoop实现半结构化、非结构化数据处理。这样可以同时满足结构化、半结构化和非结构化数据的高效处理需求。
2、Doris架构
Doris主要整合了Google Mesa(数据模型),Apache Impala(MPP Query Engine)和Apache ORCFile (存储格式,编码和压缩) 的技术。
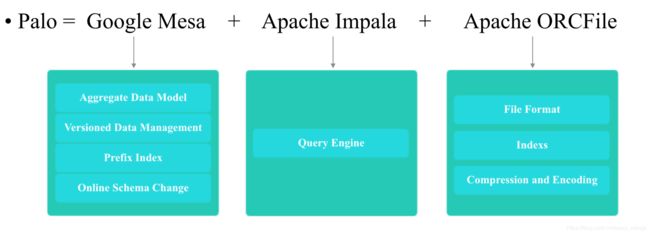
为什么要将这三种技术整合?
Mesa是一种高度可扩展的分析数据存储系统,用于存储与Google的互联网广告业务有关的关键测量数据。Mesa旨在满足一系列复杂且具有挑战性的用户和系统需求,包括接近实时的数据提取和查询能力,以及针对大数据和查询量的高可用性,可靠性,容错性和可伸缩性。
Impala是为Hadoop数据处理环境从头开始构建的现代开源MPP SQL引擎。
Mesa可以满足我们许多存储需求的需求,但是Mesa本身不提供SQL查询引擎;Impala是一个非常好的MPP SQL查询引擎,但是缺少完美的分布式存储引擎;ORCFile:采用列式存储(只访问查询涉及的列,能大量降低系统I/O;列数据相对来说比较类似,压缩比更高;每一列由一个线索来处理,更有利于查询的并发处理)。因此选择了这三种技术的组合。
Doris的系统架构如下,Doris主要分为FE和BE两个组件,FE主要负责查询的编译,分发和元数据管理(基于内存,类似HDFS NN);BE主要负责数据的存储、以及查询计划的执行。
3、Doris VS Kylin
首先我们将Doris和Kylin进行对比,来探讨我们在什么情况下会选择使用Doris。当然此处对比,仅仅是方便我们知道在什么场景下该如何选择,技术本身是没有好坏之分的。
3.1 整体比较

3.2 功能具体比较
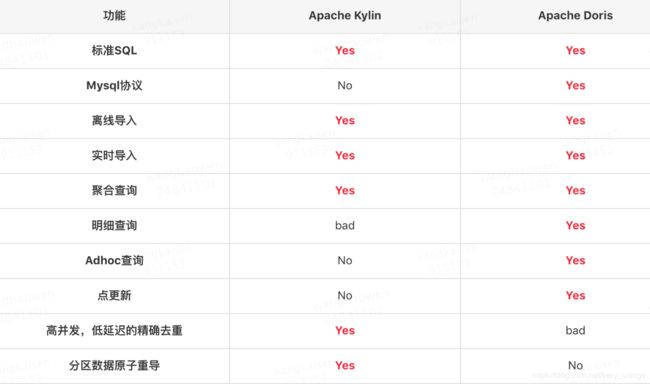
在实际的业务中,点变更和精确去重是我们十分关注的feature。
1、Schema变更:由于业务原因,Schema的变更会十分频繁。Kylin中用户对Cube Schema的任何改变,都需要在Staging环境重刷所有数据,然后切到Prod环境。整个过程周期很长,资源浪费比较严重。而Doris支持Online Schema Change。
2、精确去重:Kylin的可支持亿级的精确去重,但Doris只支持百万级别的精确去重
以下两章节来介绍下这两个特性。
4、Schema Change
Doris为什么支持Schema Change?
Doirs中的Segment文件,是可以进行Compaction的。具体是因为mesa的数据版本化管理。
数据的版本化虽然可以解决读写冲突和更新的原子性,但是也带来了以下问题:
- 存储成本。 多版本意味着我们需要存储多份数据,但是由于聚合后的数据一般比较小,所以这个问题还好。
- 查询时延。 如果有很多版本,那么查询时需要遍历的版本数据就会很多,自然就会增大查询时延。
为了解决这两个问题,常见的思路就是及时删除不需要的、过期的数据,以及将小的文件merge为大的文件。

如上图所示,Mesa的merge策略,引入了cumulative compaction和base compaction的概念。 Mesa中将包含了一定版本的数据称为deltas, 表示为[V1, V2],刚实时写入的小deltas, 称之为singleton deltas,然后每到一定的版本数,图中是10,就通过cumulative compaction将10个singleton deltas合并为1个cumulative deltas,最终每天会通过base compaction将所有一定周期的内的deltas都合并为base deltas。 所以查询时只需要查询1个base deltas, 1个cumulative deltas和少数singleton deltas即可。
注意,compaction是在后台并发和异步执行的,此外由于Mesa的存储是按照key有序存储的,所以deltas的merge是线性时间的。
支持哪种?
Doris中目前进行schema change的方式有三种,sorted schema change,direct schema change, linked schema change。
- linked schema change: 无需转换数据,直接完成。新摄入的数据都按照新的Schema处理,对于旧数据,新加列的值直接用对应数据类型的默认值填充。例如加列操作。
ALTER TABLE site_visit ADD COLUMN click bigint SUM default '0'; - sorted schema change: 改变了列的排序方式,需对数据进行重新排序。例如删除排序列中的一列, 字段重排序。
ALTER TABLE site_visit DROP COLUMN city; - direct schema change: 就是重刷全量数据,成本最高,和kylin的做法类似。例如修改列的类型。
ALTER TABLE site_visit MODIFY COLUMN username varchar(64);
5、精确去重
Kylin是典型的用空间换时间的OLAP引擎,它是基于全局字典和RoaringBitmap实现的基于预计算的精确去重。可支持亿级的精确去重。
而Doris本身只支持百万级的现场精确去重。
Doris计算精确去重时会拆分为两步:
按照所有的group by 字段和精确去重的字段进行聚合
按照所有的group by 字段进行聚合
SELECT a, COUNT(DISTINCT b, c), MIN(d), COUNT(*) FROM T GROUP BY a
* - 1st phase grouping exprs: a, b, c
* - 1st phase agg exprs: MIN(d), COUNT(*)
* - 2nd phase grouping exprs: a
* - 2nd phase agg exprs: COUNT(*), MIN(), SUM()
下面是个简单的等价转换的例子:
select count(distinct lo_ordtotalprice) from ssb_sf20.v2_lineorder;
select count(*) from (select count(*) from ssb_sf20.v2_lineorder group by lo_ordtotalprice) a;
Doris现场精确去重计算性能和去重列的基数、去重指标个数、过滤后的数据大小成负相关;
更新-----基于bitmap的预计算的精确去重,由我司同学贡献,目前已在美团内部上线。用户可以在聚合模型下创建bitmap类型的value列。
6、数据模型
接下来我们介绍一下聚合模型,明细模型。以便我们在使用时知道选择哪个模型
6.1 Aggregate模型(聚合模型):
十分适合有固定模式的报表类查询场景。我们接下来以实际的例子来说明什么是聚合模型,以及如何正确的使用聚合模型。
示例1:导入数据聚合
CREATE TABLE IF NOT EXISTS example_db.expamle_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间",
)
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
... /* 省略 Partition 和 Distribution 信息 */
;
Doris中按照相同的key进行聚合,最终只保留聚合后的数据。换句话说,即明细数据会丢失,用户不能够再查询到聚合前的明细数据了。
示例2:保留明细数据
CREATE TABLE IF NOT EXISTS example_db.expamle_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`date` DATE NOT NULL COMMENT "数据灌入日期时间",
`timestamp` DATETIME NOT NULL COMMENT "数据灌入时间,精确到秒",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`last_visit_date` DATETIME REPLACE DEFAULT "1970-01-01 00:00:00" COMMENT "用户最后一次访问时间",
`cost` BIGINT SUM DEFAULT "0" COMMENT "用户总消费",
`max_dwell_time` INT MAX DEFAULT "0" COMMENT "用户最大停留时间",
`min_dwell_time` INT MIN DEFAULT "99999" COMMENT "用户最小停留时间",
)
AGGREGATE KEY(`user_id`, `date`, `timestamp`, `city`, `age`, `sex`)
... /* 省略 Partition 和 Distribution 信息 */
;
增加了一列 timestamp,记录精确到秒的数据灌入时间。
因加入了 timestamp 列,所有行的 Key 都不完全相同。所以存储的数据,和导入数据完全一样,没有发生任何聚合,保存了完整的明细数据
6.2 Uniq模型(唯一主键):
在某些多维分析场景下,用户更关注的是如何获得 Primary Key 唯一性约束。因此,我们引入了 Uniq 的数据模型。该模型本质上是聚合模型的一个特例,也是一种简化的表结构表示方式。
示例1:
CREATE TABLE IF NOT EXISTS example_db.expamle_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",
`city` VARCHAR(20) COMMENT "用户所在城市",
`age` SMALLINT COMMENT "用户年龄",
`sex` TINYINT COMMENT "用户性别",
`phone` LARGEINT COMMENT "用户电话",
`address` VARCHAR(500) COMMENT "用户地址",
`register_time` DATETIME COMMENT "用户注册时间"
)
UNIQUE KEY(`user_id`, `user_name`)
... /* 省略 Partition 和 Distribution 信息 */
;
这是一个典型的用户基础信息表。这类数据没有聚合需求,只需保证主键唯一性。(这里的主键为 user_id + username)
等价于:
CREATE TABLE IF NOT EXISTS example_db.expamle_tbl
(
`user_id` LARGEINT NOT NULL COMMENT "用户id",
`username` VARCHAR(50) NOT NULL COMMENT "用户昵称",
`city` VARCHAR(20) REPLACE COMMENT "用户所在城市",
`age` SMALLINT REPLACE COMMENT "用户年龄",
`sex` TINYINT REPLACE COMMENT "用户性别",
`phone` LARGEINT REPLACE COMMENT "用户电话",
`address` VARCHAR(500) REPLACE COMMENT "用户地址",
`register_time` DATETIME REPLACE COMMENT "用户注册时间"
)
AGGREGATE KEY(`user_id`, `user_name`)
... /* 省略 Partition 和 Distribution 信息 */
;
6.3 Duplicate模型(冗余模型):
在某些多维分析场景下,数据既没有主键,也没有聚合需求。因此,我们引入 Duplicate 数据模型来满足这类需求。
示例1:
CREATE TABLE IF NOT EXISTS example_db.expamle_tbl
(
`timestamp` DATETIME NOT NULL COMMENT "日志时间",
`type` INT NOT NULL COMMENT "日志类型",
`error_code` INT COMMENT "错误码",
`error_msg` VARCHAR(1024) COMMENT "错误详细信息",
`op_id` BIGINT COMMENT "负责人id",
`op_time` DATETIME COMMENT "处理时间"
)
DUPLICATE KEY(`timestamp`, `type`) /* 只是指明底层数据按照这些列进行排序 */
... /* 省略 Partition 和 Distribution 信息 */
;
总结:

7、提高查询效率
本章节我们来介绍一下前缀索引,RollUp表这些概念,其最根本的作用是提高某些查询的查询效率(无论是通过聚合来减少数据量,还是修改列顺序以匹配前缀索引)
7.1 ROLLUP(上卷) :
rollup语法
ALTER TABLE mart_general_model.dprpt_aggr_poi_d ADD ROLLUP h_p_c_c_p(hp_cal_dt,city,age);
7.1.1 Aggregate 和 Uniq 模型中的 ROLLUP
Doris中聚合模型的RollUp表和Kylin中的Cuboid作用一样。
ROLLUP 表的基本作用,在于在 Base 表的基础上,获得更粗粒度的聚合数据

Doris中RollUp表的路由规则如下:
选择包含所有查询列的RollUp表
按照过滤和排序的Column筛选最符合的RollUp表
按照Join的Column筛选最符合的RollUp表
行数最小的
7.1.2 Duplicate模型中的 ROLLUP
因Duplicate模型没有聚合的语意,也就失去了“上卷”这一层含义,因此Doris明细模型的RollUp表主要是用来调整排序的顺序,可以实现二级索引的功能。 语法和聚合模型一样。
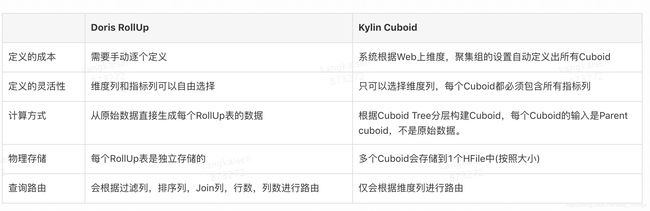
7.1.3 Doris Rollup VS Kylin Cuboid
因Doris中RollUp表和Kylin的Cuboid等价,因此我们来对两者比较一下。
7.2 前缀索引
前缀索引,即在排序的基础上,实现的一种根据给定前缀列,快速查询数据的索引方式。
本质上,Doris 的数据存储在类似 SSTable(一种有序的数据结构,可以按照指定的列进行排序存储)的数据结构中。在这种数据结构上,以排序列作为条件进行查找,会非常的高效。
Doris中将一行数据的前 36 个字节 作为这行数据的前缀索引。当遇到 VARCHAR 类型时,前缀索引会直接截断。
Eg1:以下表结构的前缀索引为 user_id(8Byte) + age(8Bytes) + message(prefix 20 Bytes)
| ColumnName | Type |
|---|---|
| user_id | bigint |
| age | int |
| message | varchar(100) |
| max_dwell_time | datetime |
| min_dwell_time | datetime |
当我们的查询条件,是前缀索引的前缀时,可以极大的加快查询速度。比如在第一个例子中,我们执行如下查询:
SELECT * FROM table WHERE user_id=1829239 and age=20;
该查询的效率会远高于如下查询:
SELECT * FROM table WHERE age=20;
所以在建表时,正确的选择列顺序,能够极大地提高查询效率。
7.3 分区和分桶
Doris支持两级分区存储, 第一层为RANGE分区(partition), 第二层为HASH分桶(bucket)。
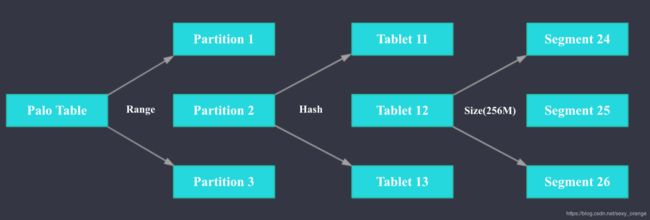
PARTITION BY RANGE(`hp_cal_dt`) //按照日期一级分区
DISTRIBUTED BY HASH(poi_id) BUCKETS 30; //按照高基数维度二级分区(建议采用区分度大的列做分桶)
参考文档:
https://doris.apache.org/
https://github.com/apache/incubator-doris/wiki/Data-Model%2C-Rollup-%26-Prefix-Index
https://ai.google/research/pubs/pub42851
https://blog.bcmeng.com/post/apache-kylin-vs-baidu-palo.html