6.NLTK之学习文本分类
有监督分类(Supervised Classification)
如果分类的建立基于包含每个输入的正确标签的训练语料,被称为有监督分类。其框架图如下:
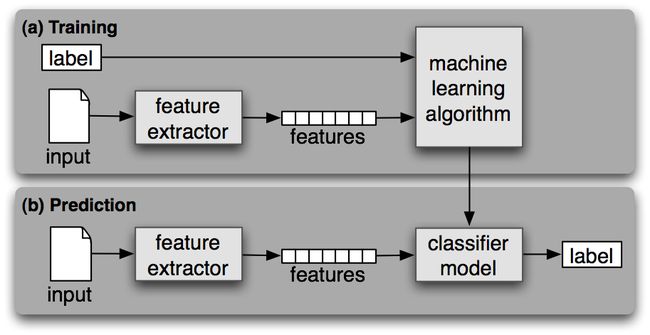
性别鉴定(Gender Identification)
以下特征提取器函数建立一个字典:
>>> def gender_features(word):
... return {'last_letter': word[-1]}
>>> gender_features('Shrek')
{'last_letter': 'k'}这个函数返回的字典被称为 特征集。
>>> from nltk.corpus import names
>>> import random
>>> names = ([(name, 'male') for name in names.words('male.txt')] +
... [(name, 'female') for name in names.words('female.txt')])
>>> random.shuffle(names)接下来,我们使用特征提取器处理名称数据,并划分特征集的结果链表为一个训练集和一个测试集。训练集用于训练一个新的“朴素贝叶斯”分类器。
>>> featuresets = [(gender_features(n), g) for (n,g) in names]
>>> train_set, test_set = featuresets[500:], featuresets[:500]
>>> classifier = nltk.NaiveBayesClassifier.train(train_set)现在,让我们在上面测试一些没有出现在训练数据中的名字:
>>> classifier.classify(gender_features('Neo'))
'male'
>>> classifier.classify(gender_features('Trinity'))
'female'用测试集生成准确率:
>>> nltk.classify.accuracy(classifier, test_set)
0.758然后,检查分类器,确定哪些特征对于区分名字的性别是最有效的。
>>> classifier.show_most_informative_features(5)
Most Informative Features
last_letter = 'a' female : male = 38.3 : 1.0
last_letter = 'k' male : female = 31.4 : 1.0
last_letter = 'f' male : female = 15.3 : 1.0
last_letter = 'p' male : female = 10.6 : 1.0
last_letter = 'w' male : female = 10.6 : 1.0选择正确的特征(Choosing The Right Features)
下面这个特征提取器返回的特征集包括大量指定的特征,从而导致对于相对较小的名字语料库过拟合。
def gender_features2(name):
features = {}
features["first_letter"] = name[0].lower()
features["last_letter"] = name[-1].lower()
for letter in 'abcdefghijklmnopqrstuvwxyz':
features["count({})".format(letter)] = name.lower().count(letter)
features["has({})".format(letter)] = (letter in name.lower())
return features如果你提供太多的特征,那么该算法将高度依赖你的训练数据的特征,从而一般化到新的例子的效果不会很好。这个问题被称为 过拟合,当运作在小训练集上时尤其会有问题。
用上面所示的特征提取器训练朴素贝叶斯分类器,将会过拟合这个相对较小的训练集,造成这个系统的精度比只考虑每个名字最后一个字母的分类器的精度低约 1%。
>>> featuresets = [(gender_features2(n), g) for (n,g) in names]
>>> train_set, test_set = featuresets[500:], featuresets[:500]
>>> classifier = nltk.NaiveBayesClassifier.train(train_set)
>>> print nltk.classify.accuracy(classifier, test_set)
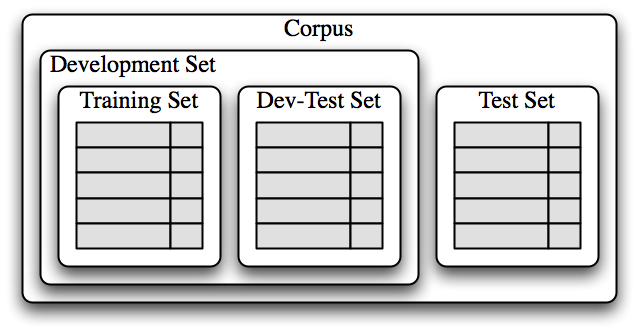
0.748一旦初始特征集被选定,完善特征集的一个非常有成效的方法是 错误分析。首先,我们选择一个 开发集,包含用于创建模型的语料数据。然后将这种开发集分为 训练集和 开发测试集。
>>> train_names = names[1500:]
>>> devtest_names = names[500:1500]
>>> test_names = names[:500]训练集用于训练模型,开发测试集用于进行错误分析,测试集用于系统的最终评估。下图显示了将语料数据划分成不同的子集。
>>> train_set = [(gender_features(n), g) for (n,g) in train_names]
>>> devtest_set = [(gender_features(n), g) for (n,g) in devtest_names]
>>> test_set = [(gender_features(n), g) for (n,g) in test_names]
>>> classifier = nltk.NaiveBayesClassifier.train(train_set)
>>> nltk.classify.accuracy(classifier, devtest_set)
0.765使用开发测试集,我们可以生成一个分类器预测名字性别时的错误列表。
>>> errors = []
>>> for (name, tag) in devtest_names:
... guess = classifier.classify(gender_features(name))
... if guess != tag:
... errors.append( (tag, guess, name) )然后,可以检查errors里面的个别错误案例,尝试确定什么额外信息将使其能够作出正确的决定(或者现有的哪部分信息导致其做出错误的决定)。然后可以相应的调整特征集。
文档分类(Document Classification)
我们选择电影评论语料库,将每个评论归类为正面或负面。
>>> from nltk.corpus import movie_reviews
>>> documents = [(list(movie_reviews.words(fileid)), category)
... for category in movie_reviews.categories()
... for fileid in movie_reviews.fileids(category)]
>>> random.shuffle(documents)我们为文档定义一个特征提取器,我们可以为每个词定义一个特性表示该文档是否包含这个词。我们一开始构建一个整个语料库中前 2000个最频繁的词的链表。然后,定义一个特征提取器,简单地检查这些词是否在一个给定的文档中。
all_words = nltk.FreqDist(w.lower() for w in movie_reviews.words())
word_features = list(all_words)[:2000]
def document_features(document):
document_words = set(document)
features = {}
for word in word_features:
features['contains({})'.format(word)] = (word in document_words)
return features然后,我们用特征提取器来训练一个分类器。
featuresets = [(document_features(d), c) for (d,c) in documents]
train_set, test_set = featuresets[100:], featuresets[:100]
classifier = nltk.NaiveBayesClassifier.train(train_set)我们可以使用 show_most_informative_features()来找出哪些特征是分类器发现最有信息量的。
>>> print(nltk.classify.accuracy(classifier, test_set))
0.81
>>> classifier.show_most_informative_features(5)
Most Informative Features
contains(outstanding) = True pos : neg = 11.1 : 1.0
contains(seagal) = True neg : pos = 7.7 : 1.0
contains(wonderfully) = True pos : neg = 6.8 : 1.0
contains(damon) = True pos : neg = 5.9 : 1.0
contains(wasted) = True neg : pos = 5.8 : 1.0探索上下文语境
下面,我们将传递整个(未标注的)句子,以及目标词的索引。
def pos_features(sentence, i):
features = {"suffix(1)": sentence[i][-1:],
"suffix(2)": sentence[i][-2:],
"suffix(3)": sentence[i][-3:]}
if i == 0:
features["prev-word"] = ""
else:
features["prev-word"] = sentence[i-1]
return features
>>> pos_features(brown.sents()[0], 8)
{'suffix(3)': 'ion', 'prev-word': 'an', 'suffix(2)': 'on', 'suffix(1)': 'n'}
>>> tagged_sents = brown.tagged_sents(categories='news')
>>> featuresets = []
>>> for tagged_sent in tagged_sents:
... untagged_sent = nltk.tag.untag(tagged_sent)
... for i, (word, tag) in enumerate(tagged_sent):
... featuresets.append((pos_features(untagged_sent, i), tag) )
>>> size = int(len(featuresets) * 0.1)
>>> train_set, test_set = featuresets[size:], featuresets[:size]
>>> classifier = nltk.NaiveBayesClassifier.train(train_set)
>>> nltk.classify.accuracy(classifier, test_set)
0.78915962207856782