Ignite配置
集群发现
Ignite的发现机制,根据不同的使用场景,有两种实现:
- TCP/IP发现:面向百级集群节点设计和优化;
- ZooKeeper发现:允许将Ignite集群节点数扩展至百级甚至千级,仍然保证扩展性和性能。
1.TCP/IP发现
1.1.概述
Ignite中,通过DiscoverySpi节点可以彼此发现对方,Ignite提供了TcpDiscoverySpi作为DiscoverySpi的默认实现,它使用TCP/IP来作为节点发现的实现,可以配置成基于组播的或者基于静态IP的.
1.2.组播IP探测器
TcpDiscoveryMulticastIpFinder使用组播来发现网格内的每个节点。它也是默认的IP探测器。除非打算覆盖默认的设置否则不需要指定它。
下面的例子显示了如何通过Spring XML配置文件或者通过Java代码编程式地进行配置:
TcpDiscoverySpi spi = new TcpDiscoverySpi();
TcpDiscoveryMulticastIpFinder ipFinder = new TcpDiscoveryMulticastIpFinder();
ipFinder.setMulticastGroup("228.10.10.157");
spi.setIpFinder(ipFinder);
IgniteConfiguration cfg = new IgniteConfiguration();
// Override default discovery SPI.
cfg.setDiscoverySpi(spi);
// Start Ignite node.
Ignition.start(cfg);1.3.静态IP探测器
对于组播被禁用的情况,TcpDiscoveryVmIpFinder会使用预配置的IP地址列表。
唯一需要提供的就是至少一个远程节点的IP地址,但是为了保证冗余一个比较好的做法是在未来的某些时间点提供2-3个计划启动的网格节点的IP地址。只要建立了与任何一个已提供的IP地址的连接,Ignite就会自动地发现其它的所有节点。
注意
除了在配置中指定地址,还可以在IGNITE_TCP_DISCOVERY_ADDRESSES环境变量或者同名的系统属性中进行指定,地址列表可以用逗号分隔,也可以包含可选的端口范围。
警告
TcpDiscoveryVmIpFinder默认用的是非共享模式,如果希望启动一个服务端节点,那么在该模式中的IP地址列表同时也要包含本地节点的一个IP地址。它允许节点不等待其它节点加入集群,而是成为第一个集群节点并正常运行。
TcpDiscoverySpi spi = new TcpDiscoverySpi();
TcpDiscoveryVmIpFinder ipFinder = new TcpDiscoveryVmIpFinder();
// Set initial IP addresses.
// Note that you can optionally specify a port or a port range.
ipFinder.setAddresses(Arrays.asList("1.2.3.4", "1.2.3.5:47500..47509"));
spi.setIpFinder(ipFinder);
IgniteConfiguration cfg = new IgniteConfiguration();
// Override default discovery SPI.
cfg.setDiscoverySpi(spi);
// Start Ignite node.
Ignition.start(cfg);1.4.组播和静态IP探测器
可以同时使用基于组播和静态IP的发现,这种情况下,除了通过组播接受地址以外,如果有,TcpDiscoveryMulticastIpFinder也可以与预配置的静态IP地址列表一起工作,就像上面描述的基于静态IP的发现一样。
下面的例子显示了如何配置使用了静态IP地址的组播IP探测器。
TcpDiscoverySpi spi = new TcpDiscoverySpi();
TcpDiscoveryMulticastIpFinder ipFinder = new TcpDiscoveryMulticastIpFinder();
// Set Multicast group.
ipFinder.setMulticastGroup("228.10.10.157");
// Set initial IP addresses.
// Note that you can optionally specify a port or a port range.
ipFinder.setAddresses(Arrays.asList("1.2.3.4", "1.2.3.5:47500..47509"));
spi.setIpFinder(ipFinder);
IgniteConfiguration cfg = new IgniteConfiguration();
// Override default discovery SPI.
cfg.setDiscoverySpi(spi);
// Start Ignite node.
Ignition.start(cfg);1.5.基于ZooKeeper的发现
如果使用ZooKeeper 来整合分布式环境,也可以利用它进行Ignite节点的发现,这是通过TcpDiscoveryZooKeeperIpFinder实现的(注意需要启用ignite-zookeeper模块)。
TcpDiscoverySpi spi = new TcpDiscoverySpi();
TcpDiscoveryZooKeeperIpFinder ipFinder = new TcpDiscoveryZooKeeperIpFinder();
// Specify ZooKeeper connection string.
ipFinder.setZkConnectionString("127.0.0.1:2181");
spi.setIpFinder(ipFinder);
IgniteConfiguration cfg = new IgniteConfiguration();
// Override default discovery SPI.
cfg.setDiscoverySpi(spi);
// Start Ignite node.
Ignition.start(cfg);1.6.故障检测超时
故障检测超时用于确定一个集群节点在与远程节点连接失败时可以等待多长时间。
集群中的每个节点都是与其它节点连接在一起的,在发现SPI这个层级,NodeA会向NodeB发送心跳消息(还有其它在集群内传输的系统消息),如果后者在failureDetectionTimeout指定的时间范围内没有反馈,那么NodeB会被从集群中踢出。
根据集群的硬件和网络条件,这个超时时间是调整发现SPI的故障检测功能的最简单的方式。
注意
这些TcpDiscoverySpi的超时配置参数是自动控制的,比如套接字超时,消息确认超时以及其它的,如果显式地设置了这些参数中的任意一个,故障超时设置都会被忽略掉。
关于故障检测超时的配置,对于服务端节点是通过IgniteConfiguration.setFailureDetectionTimeout(long)方法配置的,对于客户端节点是通过IgniteConfiguration.setClientFailureDetectionTimeout(long)方法配置的。关于默认值,服务端节点为10秒,客户端节点为30秒,这个时间可以使发现SPI在大多数的私有和虚拟化环境下可靠地工作,但是对于一个稳定的低延迟网络来说,这个参数设置成大约200毫秒会更有助于快速地进行故障的检测和响应。
1.7.配置
下面的配置参数可以对TcpDiscoverySpi进行可选的配置,在TcpDiscoverySpi的javadoc中还可以看到完整的配置参数列表:
| setter方法 | 描述 | 默认值 |
|---|---|---|
setIpFinder(TcpDiscoveryIpFinder) |
用于节点IP地址信息共享的IP探测器 | TcpDiscoveryMulticastIpFinder,部分实现如下:TcpDiscoverySharedFsIpFinder,TcpDiscoveryS3IpFinder,TcpDiscoveryJdbcIpFinder,TcpDiscoveryVmIpFinder |
setLocalAddress(String) |
设置发现SPI使用的本地主机IP地址 | 如果未提供,默认会使用发现的第一个非loopback地址,如果没有可用的非loopback地址,那么会使用java.net.InetAddress.getLocalHost() |
setLocalPort(int) |
SPI监听端口 | 47500 |
setLocalPortRange(int) |
本地端口范围,本地节点会试图绑定从localPort开始的第一个可用的端口,直到localPort+localPortRange | 100 |
setReconnectCount(int) |
节点与其它节点试图(重新)建立连接的次数 | 2 |
setNetworkTimeout(long) |
用于拓扑操作的最大超时时间 | 5000 |
setSocketTimeout(long) |
设置Socket操作超时时间,这个超时时间用于限制连接时间以及写Socket时间 | 2000 |
setAckTimeout(long) |
设置收到发送消息的确认的超时时间,如果在这个时间段内未收到确认,发送会被认为失败然后SPI会试图重新发送消息 | 2000 |
setJoinTimeout(long) |
设置加入超时时间,如果使用了非共享的IP探测器然后节点通过IP探测器无法与任何地址建立连接,节点会在这个时间段内仍然试图加入集群。如果所有地址仍然无响应,会抛出异常然后节点启动失败,0意味着一直等待 | 0 |
setThreadPriority(int) |
SPI启动的线程的线程优先级 | 0 |
setStatisticsPrintFrequency(int) |
统计输出的频率(毫秒),0意味着不需要输出。如果值大于0那么日志就会激活,然后每隔一段时间就会以INFO级别输出一个状态,这对于跟踪拓扑的问题非常有用。 | 0 |
2.ZooKeeper发现
2.1.概述
Ignite使用TCP/IP发现机制,将集群节点组织成环状拓扑结构有其优点,也有缺点。比如在一个有上百个节点的拓扑中,系统消息遍历所有的节点需要花很多秒,就结果来说,基本的事件处理,比如新节点加入或者故障节点检测,就会影响整个集群的响应能力和性能。
ZooKeeper发现机制是为需要保证伸缩性和线性扩展的大规模Ignite集群而设计的。但是同时使用Ignite和ZooKeeper需要配置和管理两个分布式系统,这很有挑战性。因此,建议仅在打算扩展到成百或者上千个节点时才使用该发现机制。否则,最好使用TCP/IP发现。
ZooKeeper发现使用ZooKeeper作为同步的单点,然后将Ignite集群组织成一个星型拓扑,这时ZooKeeper集群位于中心,然后Ignite节点通过它进行发现事件的交换。

值得一提的是,ZooKeeper发现仅仅是发现机制的一个实现,不会影响Ignite节点间的通信(可以看网络配置章节)。节点之间一旦通过ZooKeeper发现机制彼此探测到,它们就会使用Communication SPI进行点对点的通信。
2.2.配置
ZookeeperDiscoverySpi zkDiscoSpi = new ZookeeperDiscoverySpi();
zkDiscoSpi.setZkConnectionString(
"127.0.0.1:34076,127.0.0.1:43310,127.0.0.1:36745");
zkDiscoSpi.setSessionTimeout(30_000);
zkDiscoSpi.setZkRootPath("");
zkDiscoSpi.setJoinTimeout(10_000);
IgniteConfiguration cfg = new IgniteConfiguration();
//Override default discovery SPI.
cfg.setDiscoverySpi(zkDiscoSpi);
// Start Ignite node.
Ignition.start(cfg);zkConnectionString:ZooKeeper服务器地址列表;sessionTimeout:如果无法通过发现SPI进行事件消息的交换,多久之后节点会被视为断开连接。
2.3.故障和脑裂处理
在拓扑分区的情况下,一些节点由于位于分离的网络段而不能相互通信,这可能导致处理用户请求失败或不一致的数据修改。
ZooKeeper发现机制通过如下的方式来处理拓扑分区(脑裂)以及单个节点之间的通信故障:
注意
假定集群中的所有节点都可以访问ZooKeeper集群。事实上,如果一个节点与ZooKeeper断开,那么它就会停止,然后其它节点就会将其视为故障或者失联。
当节点发现它不能连接到集群中的其它节点时,它就通过向ZooKeeper集群发布特殊请求来启动一个通信故障解决进程。该进程启动后,所有节点尝试彼此连接,并将连接尝试的结果发送到协调进程的节点(协调器节点)。基于此信息,协调器节点创建表示集群中的网络状况的连接图,而进一步的动作取决于网络分区的类型。
集群被分为若干个不相交的部分
如果集群被分成几个独立的部分,每个部分(作为一个集群)可能认为自己是一个主集群并继续处理用户请求,从而导致数据不一致。为了避免这种情况,只有节点数量最多的部分保持活动,而其它部分的节点会被关闭。

上图显示集群被分为了两个部分,小集群中的节点(右侧的部分)会被终止。

当有多个最大的部分时,具有最大数量的客户端的部分保持活动,而其它部分则关闭。
节点间部分连接丢失
一些节点无法连接到其它一些节点,这意味着虽然这些节点没有完全与集群断开连接,但是无法与一些节点交换数据,因此不能成为集群的一部分。在下图中,一个节点不能连接到其它两个节点:

这时,任务就是找到每个节点可以连接到每个其它节点的最大部分,这通常是一个难题,在可接受的时间内无法解决。协调器节点会使用启发式算法来寻找最佳近似解,解中忽略的节点将被关闭。
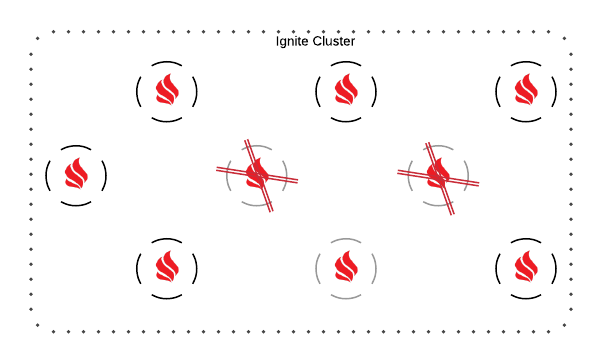
ZooKeeper集群分区
在大规模集群中,ZooKeeper集群可以跨越多个数据中心和地理上不同的位置,由于拓扑分割,它可以分成多个段。如果出现这种情况,ZooKeeper将检查是否存在一个包含所有ZooKeeper节点的一半以上的段(对于ZooKeeper继续其操作来说,需要这么多节点),如果找到,这个段将接管Ignite集群的管理,而其它段将被关闭。如果没有这样的段,ZooKeeper将关闭它的所有节点。
在ZooKeeper集群分区的情况下,Ignite集群可以分割也可以不分割。在任何情况下,当关闭ZooKeeper节点时,相应的Ignite节点将尝试连接到可用ZooKeeper节点,如果不能这样做,则将关闭。
下图是将Ignite集群和ZooKeeper集群分割成两个部分的拓扑分区示例。如果集群部署在两个数据中心,则可能出现这种情况。这时,位于数据中心B的ZooKeeper节点将自动关闭,而位于数据中心B的Ignite节点因为无法连接到其余ZooKeeper节点,因此也将关闭自己。

2.4.自定义发现事件
将环形拓扑变更为星型拓扑,影响了发现SPI处理自定义发现事件的方式。因为环形拓扑是线性的,这意味着每个发现消息是被节点顺序处理的,因此在某个特定时间,只会有一个节点在处理消息。
而在ZooKeeper发现机制中,协调器会同时将发现消息发送给所有节点,结果就是消息的并行处理。
这种并行处理的结果就是,ZooKeeper发现机制不允许对自定义发现事件的修改,比如,节点不允许为发现消息添加任何负载。
2.5.Ignite和ZooKeeper的配置一致性
使用ZooKeeper发现机制,需要确保两个系统的配置参数相互匹配不矛盾。
比如下面的ZooKeeper简单配置:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5如果这样配置,只有过了tickTime * syncLimit时限,ZooKeeper服务器才会发觉它是否与剩余的ZooKeeper集群分区,在ZooKeeper的这段时间之内,所有的Ignite节点都会接入该已分割的ZooKeeper服务器,而不会与其它的ZooKeeper服务器进行连接。
另一方面,在Ignite端有一个sessionTimeout参数,它定义了如果节点与ZooKeeper集群断开,多长时间ZooKeeper会关闭Ignite节点的会话,如果sessionTimeout比tickTime * syncLimit小,那么Ignite节点就会被分割的ZooKeeper服务器过早地通知,即会话会在其试图连接其它的ZooKeeper服务器之前过期。
要避免这种情况发生,sessionTimeout要比tickTime * syncLimit大。