Faster R-CNN tensorflow版本,cpu下运行demo
官方给出的Faster R-CNN的代码是caffe框架下的,我对caffe不是很了解,一直用的是tensorflow环境,所以去网上找了一下用tensorflow实现的Faster R-CNN。找到了一篇博客https://www.cnblogs.com/toone/p/8433581.html,作者使用的是一个github上Xinlei Chen的tensorflow版本的faster rcnn代码。这里贴出github链接https://github.com/endernewton/tf-faster-rcnn
首先,按照博客里面作者的步骤,一步步实现,但是我是在自己的台式机上跑的,没有GPU,因此需要做一些修改。下面走一遍整个流程,记录下踩过的坑。
1.本机环境
ubuntu16.04
无GPU
tensorflow版本是1.7.0
python版本2.7.13 (anaconda安装,虽然系统自带python,但是使用anaconda安装可以一次性将大部分机器学习中用到的包装好,所以建议使用anaconda安装)
cython版本0.25.2
opencv-python(该博客使用的是这个,但是我装的是opencv-contrib-python3.4.1.15,也没问题,看网上说,带contrib的会有很多好处,我对这个了解不多,所以先装再看)
easydict版本1.7(博客作者用的1.6,感觉有装就可以,版本关系不大)
2.下载github项目代码和数据
git clone https://github.com/endernewton/tf-faster-rcnn.git
我是直接在home目录下建了一个我自己的文件夹jcm,然后在这个文件夹上右击,在此处打开终端,输入上面的命令就可以将整个项目代码下载到jcm文件夹下。

3.修改配置
在lib文件夹下有个setup.py文件,里面可以设置CPU和GPU的参数。如图所示
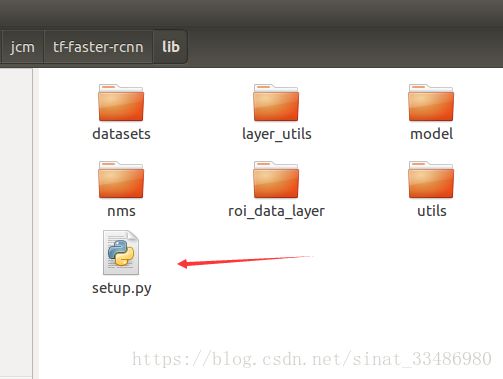
我这里没有GPU,所以选择cpu运行,此处必须做相应的修改,因为代码默认是在GPU下运行,所以按照后面编译的命令执行时会报错。
python setup.py build_ext --inplace
Traceback (most recent call last):
File "setup.py", line 58, in
CUDA = locate_cuda()
File "setup.py", line 46, in locate_cuda
raise EnvironmentError('The nvcc binary could not be '
EnvironmentError: The nvcc binary could not be located in your $PATH. Either add it to your path, or set $CUDAHOME
make: *** [all] 错误 1
问题解决:
首先按照github里面的readme,只要将USE_GPU_NMS 由原来的True改为False就可以。但是我改完发现,后面编译的时候还是会报错。
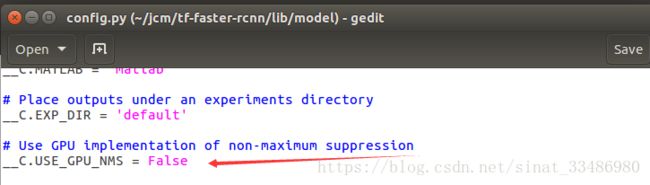
苦苦查询了很久,终于在一个贴吧找到了解决办法,地址为https://zhidao.baidu.com/question/505011922.html
我这里总结下需要修改的位置:
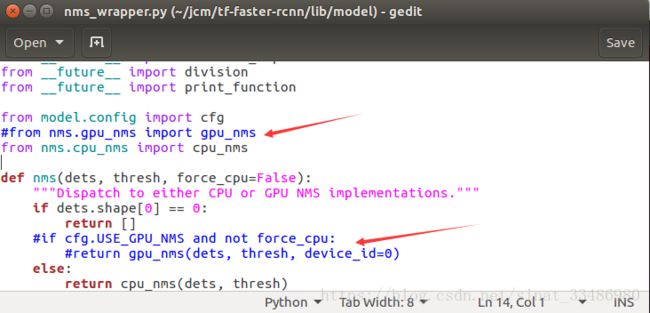
(1)修改lib/model/nms_wrapper.py
按照图中箭头所指示的地方,将代码注释,作用就是为了直接禁用掉GPU模式
(2)lib/setup.py

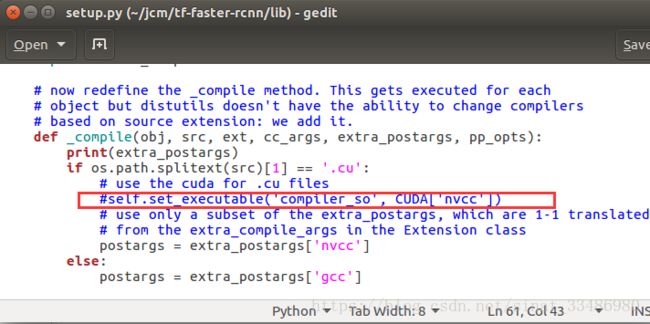
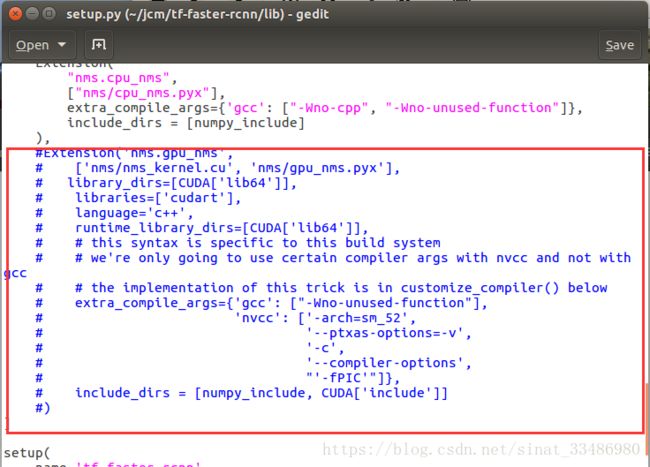
需要注意的是,不要直接用三个引号的方式整块注释,要一行一行注释。
4.链接cython 模块
在lib目录下打开终端,输入
make clean
make
cd ..
如果按照前面的步骤,把GPU配置的代码注释,应该可以成功编译(不报错)。
此时终端回到主目录tf-faster-rcnn
5.安装 Python COCO API,这是为了使用COCO数据库
cd data
git clone https://github.com/pdollar/coco.git
cd coco/PythonAPI
make
cd ../../..
此时终端的目录是主目录tf-faster-rcnn
6.运行Demo 和测试预训练模型
(1)下载预训练模型
要用到的模型 voc_0712_80k-110k.tgz ,按照readme里面给的sh文件下载可能会有网络问题,下载不下来。这个文件可以手动下载(百度云备份:https://pan.baidu.com/s/1kWkF3fT),下载之后放到 data文件夹中就行。使用命令
tar xvf voc_0712_80k-110k.tgz
解压得到voc_2007_trainval+voc_2012_trainval文件夹
(2)建立预训练模型的软连接
NET=res101
TRAIN_IMDB=voc_2007_trainval+voc_2012_trainval
mkdir -p output/${NET}/${TRAIN_IMDB}
cd output/${NET}/${TRAIN_IMDB}
ln -s ../../../data/voc_2007_trainval+voc_2012_trainval ./default
cd ../../..
在data目录下运行终端,运行完前三条命令,会新建一个目录tf-faster-rcnn/data/output/res101/voc_2007_trainval+voc_2012_trainval
然后运行第四条命令,终端进入voc_2007_trainval+voc_2012_trainval文件夹,运行第五条命令,产生一个名字为default的链接文件,但是...此处需要注意,按照这条命令,从终端的tf-faster-rcnn/data/output/res101/voc_2007_trainval+voc_2012_trainval路径开始,执行../../../后的终端目录是tf-faster-rcnn/data,而此时后半部分命令是data/voc_2007_trainval+voc_2012_trainval ./default这里可以发现,当前目录和后半部分的data重复了,按照这个执行下去,不会报错,
但是双击打开这个default,会提示所链接的文件不存在。
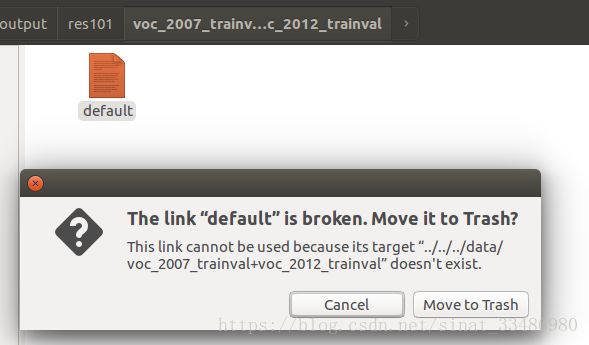
当后面跑demo时,会自动根据这个default去链接训练好的模型文件,这种情况下的default是无效的,直接报错。所以这里的第5条命令需要修改为:
ln -s ../../../voc_2007_trainval+voc_2012_trainval ./default
也就是把data/去掉,这时打开default会显示链接到的四个模型文件。

此时,运行最后的一条命令,将终端目录切换到了data目录下
![]()
(3)运行demo
博客中的代码是这样的,也是github里面给出的
GPU_ID=0
CUDA_VISIBLE_DEVICES=${GPU_ID} ./tools/demo.py
但是,我是直接用cpu进行处理,所以直接运行demo.py文件,注意...,上一步最后的目录是停在了data下,所以不能直接运行./tools/demo.py
而是需要将目录切换到主目录下才能访问tools文件,所以最终的命令是:
../tools/demo.py
运行结果为:
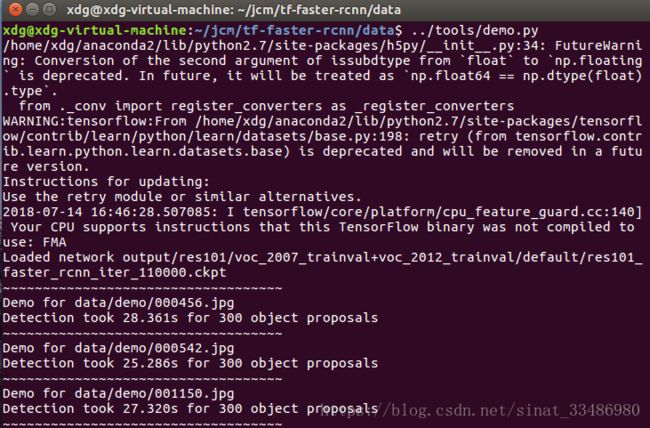
这个demo里面自带5张照片:
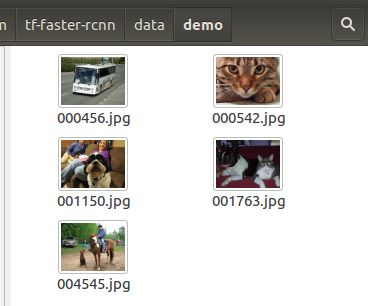
运行后的预测结果为12张图像:
到此结束~