Pytorch入门(三)用Pytorch多特征预测股票(LSTM、Bi-LSTM、GRU)
输入数据
pytorch的input:(seq_len, batch, input_size),注意,LSTM本身是没有timestep这个参数的!!!我们希望每次通过前10s的数据预测下1s的数据的话,就相当于LSTM循环10次,这里一般有两种做法。
第一种,如果你的数据处理完每次喂给LSTM层是(seq_len, batch, input_size),当seq_len=1的时候,你需要手动写个for循环串联timestep个LSTM,否则,默认就是循环1次,其实很少这样做。当seq_len不等于1呢?那就直接给LSTM,seq_len等于几就循环几次,只不过把数据处理成这样不太方便(其实也就是reshape一下的事),这种主要是方便你对每一次LSTM循环后取值(隐藏态、细胞态、输出),做一下attention操作啥的,方便更细粒度的操作LSTM网络结构。
第二种,你不想那么麻烦,数据直接处理成(batch,timestep,input_size)的形式,那么必须在定义网络的时候
batch_first = True因为默认batch的参数是第二个,LSTM会把根据timestep,也就是第二个参数循环timestep次。数据处理方式如下
初始的数据集一般是(总时间,特征),这个时候,为了扩展成三维的数据,假设时间步长10s,特征为5,那么把前10s的数据拼在一行,原来一行是1×5,现在变成了1×50,就是第11s的数据是由前10s行构成,依次类推,预测值对应的从11s开始,这样处理完的数据变成(总时间-timestep,timestep*特征数),然后再reshape成三维的变成(总时间-timestep,timestep,特征数),对应的预测值的维度就是(总时间-timestep,1),下面是核心代码
# convert series to supervised learning
def series_to_supervised(data, n_in=1, n_out=30, dropnan=True):
n_vars = 1 if type(data) is list else data.shape[1]
df = pd.DataFrame(data)
cols, names = list(), list()
# input sequence (t-n, ... t-1)
for i in range(n_in, 0, -1):
cols.append(df.shift(i))
names += [('var%d(t-%d)' % (j + 1, i)) for j in range(n_vars)]
# forecast sequence (t, t+1, ... t+n)
for i in range(0, n_out):
cols.append(df.shift(-i))
if i == 0:
names += [('var%d(t)' % (j + 1)) for j in range(n_vars)]
else:
names += [('var%d(t+%d)' % (j + 1, i)) for j in range(n_vars)]
# put it all together
agg = pd.concat(cols, axis=1)
agg.columns = names
# drop rows with NaN values
if dropnan:
agg.dropna(inplace=True)
return agg处理完大概长这样
 网络搭建
网络搭建
class GRUNet(nn.Module):
def __init__(self, input_size):
super(GRUNet, self).__init__()
self.rnn = nn.GRU(
input_size=input_size,
hidden_size=64,
num_layers=1,
batch_first=True,
bidirectional=True
)
self.out = nn.Sequential(
nn.Linear(128, 1)
)
def forward(self, x):
r_out, (h_n, h_c) = self.rnn(x, None) # None 表示 hidden state 会用全0的 state
out = self.out(r_out[:, -1])
print(out.shape)
return out
class LSTMNet(nn.Module):
def __init__(self, input_size):
super(LSTMNet, self).__init__()
self.rnn = nn.LSTM(
input_size=input_size,
hidden_size=64,
num_layers=1,
batch_first=True,
)
self.out = nn.Sequential(
nn.Linear(64, 1)
)
def forward(self, x):
r_out, (h_n, h_c) = self.rnn(x, None) # None 表示 hidden state 会用全0的 state
out = self.out(r_out[:, -1])
print(out.shape)
return out
class BiLSTMNet(nn.Module):
def __init__(self, input_size):
super(BiLSTMNet, self).__init__()
self.rnn = nn.LSTM(
input_size=input_size,
hidden_size=64,
num_layers=1,
batch_first=True,
bidirectional=True
)
self.out = nn.Sequential(
nn.Linear(128, 1)
)
def forward(self, x):
r_out, (h_n, h_c) = self.rnn(x, None) # None 表示 hidden state 会用全0的 state
out = self.out(r_out[:, -1])
print(out.shape)
return out
这里Bi-LSTM后面的全连接层必须是LSTM输出的两倍
网络训练
net = GRUNet(features)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.0001, weight_decay=0.001)
# start training
for e in range(1000):
for i, (X, y) in enumerate(train_loader):
var_x = Variable(X)
var_y = Variable(y)
# forward
out = net(var_x)
loss = criterion(out, var_y)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('Epoch: {}, Loss: {:.5f}'.format(e + 1, loss.item()))
if (e + 1) % 100 == 0: # 每 100 次输出结果
torch.save(obj=net.state_dict(), f='models/lstmnetpro_gru_%d.pth' % (e + 1))
torch.save(obj=net.state_dict(), f="models/lstmnet_gru_1000.pth")效果图
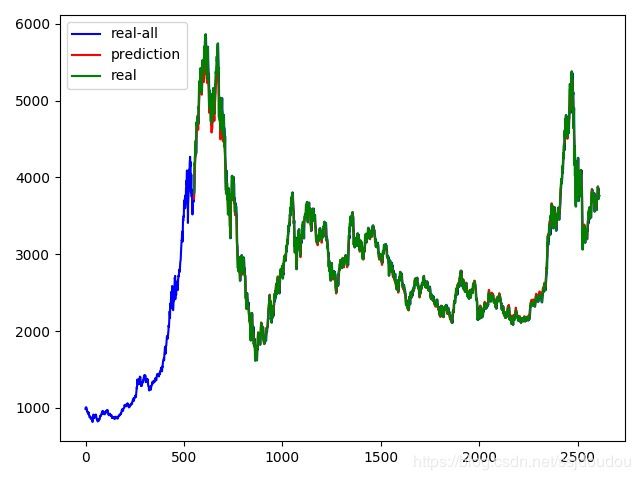
总结
GRU的效果比LSTM更好