在VMware虚拟机上部署Hadoop-3.2.0完全分布式
0、主要思路
| 1.虚拟机软件准备 2.在master节点上配置hadoop用户、安装ssh server、安装java环境 3.在master节点上安装hadoop、并完成配置 4.利用虚拟机克隆master为两个slave节点 5.对slave节点进行配置 6.在master节点上启动hadoop |
1、虚拟机软件准备
去VMware官网下载 VMware worksation 15pro,下载地址:https://my.vmware.com/en/web/vmware/info/slug/desktop_end_user_computing/vmware_workstation_pro/15_0?wd=&eqid=a4607e230000009c000000065d22abd0
(我的笔记本是windows,所以我直接下载windos版本)
下载完成后直接安装。(因为我笔记本C盘空间不足,我安装到了D盘)
安装完成后要输入密钥激活,密钥网上有很多,我提供一个网址供大家参考:
https://blog.csdn.net/felix__h/article/details/82853501
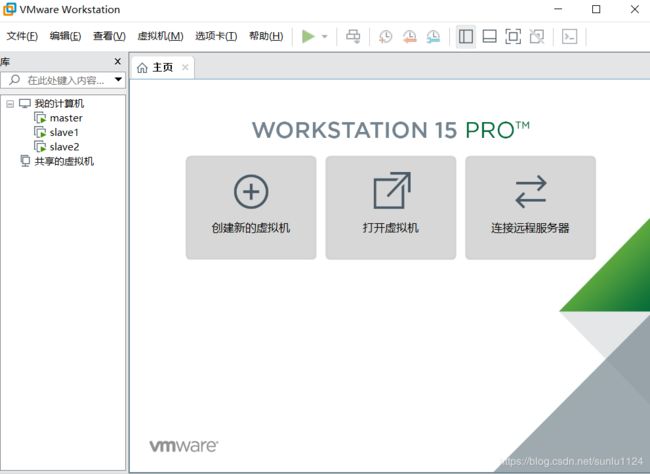
安装完成后如下图所示:(我是已经建好了一个master和两个slave,所以在我的计算机下面会显示有三台虚拟机,新安装的wmware应该是空白)
在ubuntu官网下载Ubuntu 18.04.1-LTS-桌面版-64位 ,下载地址http://releases.ubuntu.com/18.04/ubuntu-18.04.2-desktop-amd64.iso
然后回到vmware,点击创建新的虚拟机,创建一个master节点。创建虚拟机过程中,如下图所示选择刚下载的ubuntu iso文件:
然后直接点下一步就行了,创建虚拟机过程很简单,在此就不过多赘述。
master虚拟机创建完成后,直接启动,虚拟机会自动安装ubuntu,ubuntu安装完成后,会看到如下页面:
(Terminal需要自己手动拖拽到ubuntu桌面上,具体方法:点击左下角“九个点”的图标,搜索terminal,拖拽到桌面即可。)
2.在master节点上配置hadoop用户、安装ssh server、安装java环境
以下操作是在master节点上执行的!!!!!!
2.1 创建hadoop用户
如果你安装 Ubuntu 的时候不是用的 “hadoop” 用户,那么需要增加一个名为 hadoop 的用户。
在master系统中,创建新用户hadoop。在终端窗口(terminal窗口),输入如下命令创建新用户:
$ sudo useradd -m hadoop -s /bin/bash
$ sudo passwd hadoop
$ sudo adduser hadoop sudo
$ su hadoop
$ sudo apt-get update上述语句:
- 创建了可以登录的hadoop用户,并使用/bin/bash作为shell
- 设置hadoop用户登录密码
- 为hadoop用户添加管理员权限
- 转到hadoop用户
- 更新apt
2.2 安装vim
安装vim主要是因为后续需要更改一些配置文件
$ sudo apt-get install vim安装软件时若需要确认,在提示处输入 y 即可。
(vim简单操作指南!!!!新手必看!!!!!不然你根本不会更改配置文件)
| vim的常用模式有分为命令模式,插入模式,可视模式,正常模式。本教程中,只需要用到正常模式和插入模式。二者间的切换即可以帮助你完成本指南的学习。
|
2.3 SSH安装和配置无密码登录
- SSH用于主、从节点之间的连接;Ubuntu默认已安装SSH client,还需要安装SSH server:
$ sudo apt-get install openssh-server
# 安装后使用如下命令登录本机
$ ssh localhost
$ exit # 退出本次登录2.配置ssh无密码登录
$ cd ~/.ssh/
$ ssh-keygen -t rsa #遇到提示按回车即可
$ cat ./id_rsa.pub >> ./authorized_keys #加入授权
$ ssh localhost #此时再用该命令,无需输入密码就可以直接登录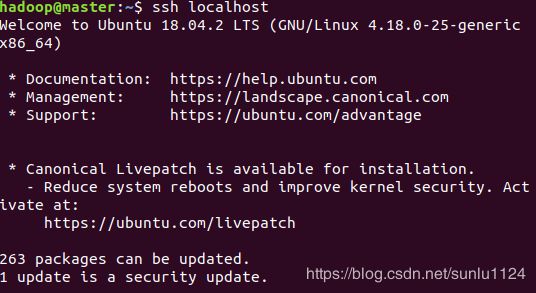
此时实现的是master节点的SSH无密登录,等后续建立slave节点后,再进行主、从节点间的SSH无密登录。
2.4安装Java环境
$ sudo apt-get insatll openjdk-8-jre
$ sudo apt-get install openjdk-8-jdk
# 下面开始配置JAVA_HOME环境变量
$ sudo vim ~/.bashrc
在文件最前面添加如下单独一行(注意 = 号前后不能有空格),将“JDK安装路径”改为上述命令得到的路径,并保存:
(如果你是和我一样的下载方式,下载时没有指定文件夹,那么jdk默认安装路径是/usr/libjvm/java-8-openjdk-amd64)
具体的环境变量配置代码如下:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=${JAVE_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH配置完如下图所示:

接着还需要让该环境变量生效,执行如下代码:
$ source ~/.bashrc
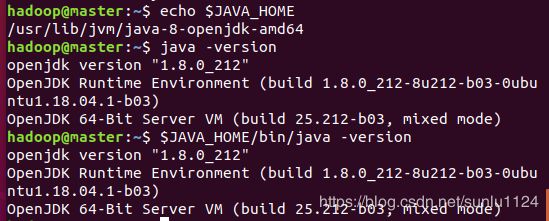
检验java环境变量配置是否正确:
$ echo $JAVA_HOME
$ java -version
$ $JAVA_HOME/bin/java -version
如果设置正确的话,$JAVA_HOME/bin/java -version 会输出 java 的版本信息,且和 java -version 的输出结果一样,如下图所示:
3、在master节点上安装hadoop并完成配置
3.1下载hadoop
通过ubuntu自带的火狐浏览器下载hadoop-3.2.0.tar.gz这个文件到Downloads文件夹下
下载地址:http://mirror.bit.edu.cn/apache/hadoop/common/
3.2安装hadoopsudo
# 解压到/opt目录下
$ sudo tar -zxf ~/Downloads/hadoop-3.2.0.tar.gz -C /opt
# 将hadoop-3.2.0文件夹改名为Hadoop,方便后续操作
$ cd /opt
$ sudo mv ./hadoop-3.2.0/ ./hadoop
$ sudo chown -R hadoop ./hadoop # 修改权限,前一个hadoop是指hadoop用户
$ cd hadoop
$ ./bin/hadoop version #测试安装是否成功成功的话如下图所示,会输出Hadoop的版本信息:

3.3配置hadoop环境变量
$ sudo vim ~/.bashrc
然后输入如下:hadoop
export HADOOP_HOME=/opt/hadoop
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin使环境变量生效
$ source ~/.bashrc3.4配置集群/分布式环境
集群/分布式模式需要修改 /opt/hadoop/etc/hadoop 中的5个配置文件,更多设置项可点击查看官方说明,这里仅设置了正常启动所必须的设置项: workers(原来的版本里叫slaves)、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
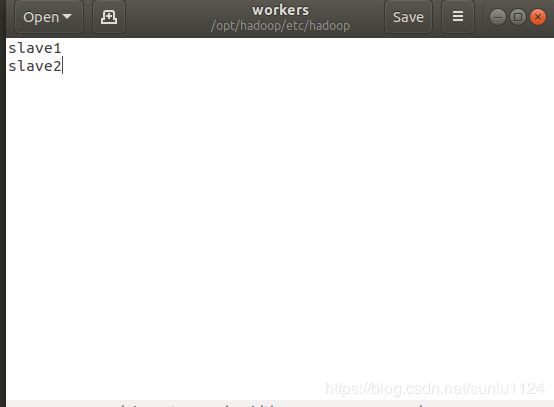
1.文件 workers,将作为 DataNode 的主机名写入该文件,每行一个,默认为 localhost,所以在伪分布式配置时,节点即作为 NameNode 也作为 DataNode。分布式配置可以保留 localhost,也可以删掉,让 Master 节点仅作为 NameNode 使用。
本教程让 Master 节点仅作为 NameNode 使用,因此将文件中原来的 localhost 删除,添加另外两个slave节点的名字。
2.文件 core-site.xml 改为下面的配置:

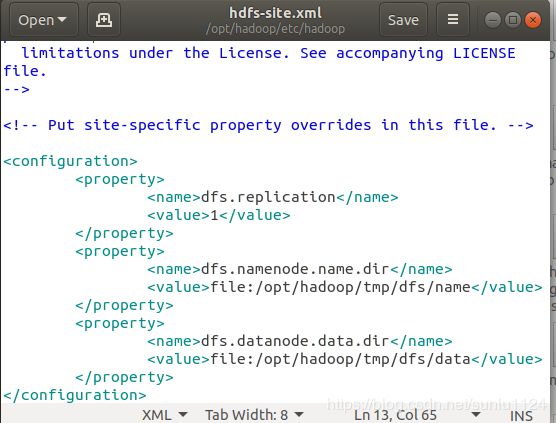
3, 文件 hdfs-site.xml,dfs.replication 一般设为 3,这里我设置dfs.replication 的值为 1
4, 文件 mapred-site.xml (可能需要先重命名,默认文件名为 mapred-site.xml.template),然后配置修改如下:

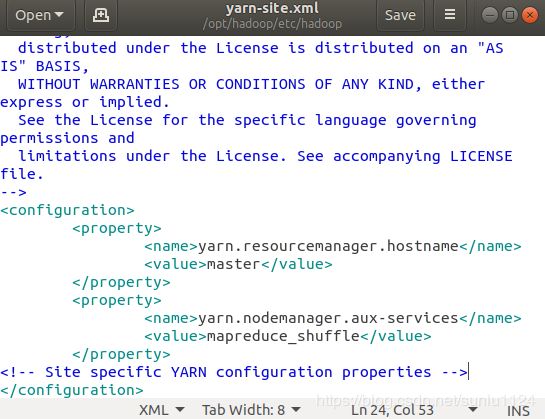
5, 文件 yarn-site.xml:
4.利用虚拟机克隆master为两个slave节点
利用虚拟机的方便,直接将现有的master节点克隆2份,完全克隆,并命名为slaver1~2,那么上述的一些配置就不用再重复配置(hadoop用户,JDK环境、hadoop安装和hadoop文件配置)。
具体虚拟机克隆方法:在vmware选中master点右键——管理——克隆,选择完全克隆,然后一直点下一步就行了。
另外注意所有虚拟机的网络都是桥接模式!!!!!!!如果默认不是桥接模式,在每台虚拟机上都要设置一下,或是把master虚拟机的网络设置为桥接后再克隆slave1和slave2虚拟机。
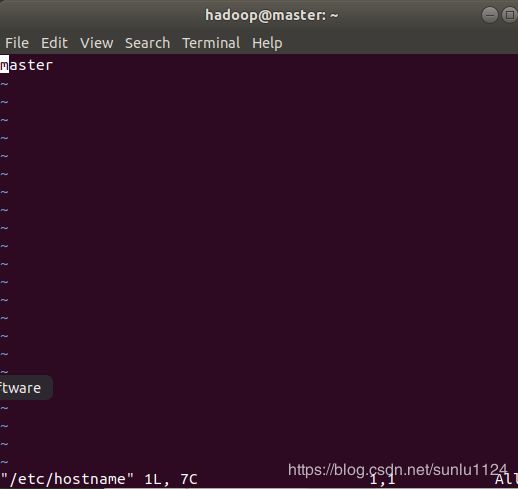
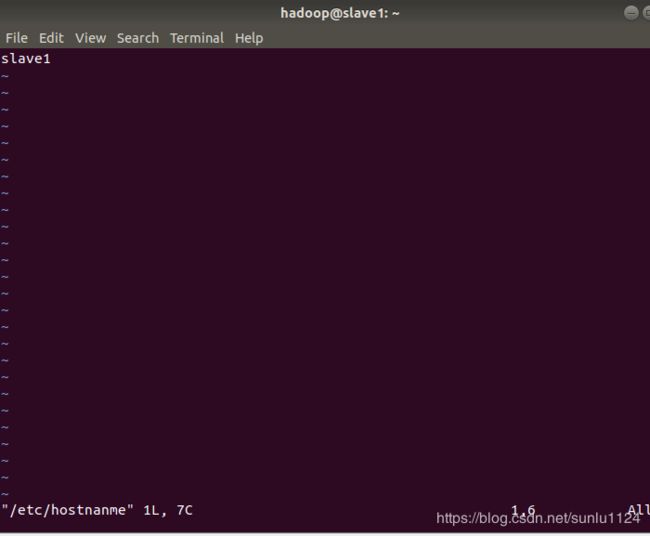
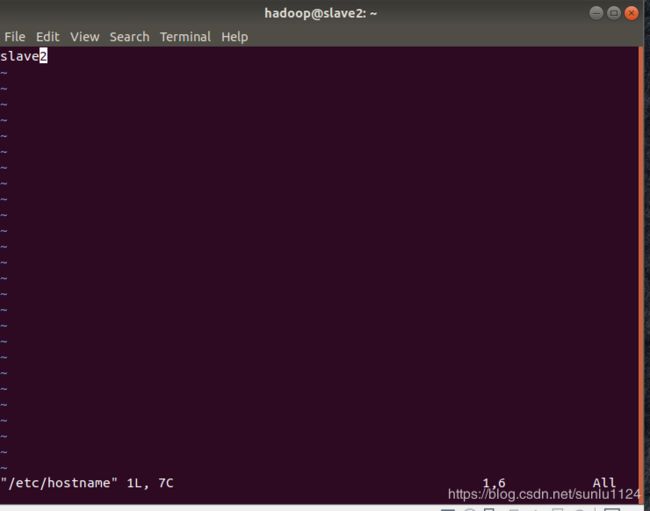
4.1主机名配置
为了便于区分,先修改各个节点的主机名
$ sudo vim /etc/hostname master虚拟机就改为master,slave1虚拟机就改为slave1,同理slave2就改为slave2,分别如下图所示: