scikit-learn中用gridsearchcv给随机森林(RF)自动调参
全文参考 1:http://scikit-learn.org/stable/auto_examples/model_selection/grid_search_digits.html#parameter-estimation-using-grid-search-with-cross-validation
全文参考 2:http://scikit-learn.org/stable/modules/model_evaluation.html#the-scoring-parameter-defining-model-evaluation-rules
全文参考 3:http://scikit-learn.org/stable/modules/generated/sklearn.metrics.roc_auc_score.html#sklearn.metrics.roc_auc_score
全文参考 4:http://scikit-learn.org/stable/auto_examples/model_selection/plot_roc.html#sphx-glr-auto-examples-model-selection-plot-roc-py
实验重点:随机森林(RandomForest) + 5折交叉验证(Cross-Validation) + 网格参数寻优(GridSearchCV) + 二分类问题中ROC曲线的绘制。
由于原始数据本身质量很好,且正负样本基本均衡,没有做数据预处理工作。
-
import pandas
as pd
-
import numpy
as np
-
import matplotlib.pyplot
as plt
-
-
from sklearn.metrics
import roc_curve
-
from sklearn.metrics
import roc_auc_score
-
from sklearn.metrics
import classification_report
-
from sklearn.model_selection
import GridSearchCV
-
from sklearn.ensemble
import RandomForestClassifier
-
#导入数据,来源于:http://mldata.org/repository/tags/data/IDA_Benchmark_Repository/,见上图
-
dataset = pd.read_csv(
'image_data.csv', header=
None, encoding=
'utf-8')
-
-
dataset_positive = dataset[dataset[
0] ==
1.0]
-
dataset_negative = dataset[dataset[
0] ==
-1.0]
-
#训练集和测试集按照7:3分割,分割时兼顾正负样本所占比例
-
#其中训练集基于5折交叉验证做网格搜索找出最优参数,应用于测试集以评价算法性能
-
train_dataset = pd.concat([dataset_positive[
0:
832], dataset_negative[
0:
628]])
-
train_recon = train_dataset.sort_index(axis=
0, ascending=
True)
-
test_dataset = pd.concat([dataset_positive[
832:
1188], dataset_negative[
628:
898]])
-
test_recon = test_dataset.sort_index(axis=
0, ascending=
True)
-
-
y_train = np.array(train_recon[
0])
-
X_train = np.array(train_recon.drop([
0], axis=
1))
-
y_test = np.array(test_recon[
0])
-
X_test = np.array(test_recon.drop([
0], axis=
1))
-
# Set the parameters by cross-validation
-
parameter_space = {
-
"n_estimators": [
10,
15,
20],
-
"criterion": [
"gini",
"entropy"],
-
"min_samples_leaf": [
2,
4,
6],
-
}
-
-
#scores = ['precision', 'recall', 'roc_auc']
-
scores = [
'roc_auc']
-
-
for score
in scores:
-
print(
"# Tuning hyper-parameters for %s" % score)
-
print()
-
-
clf = RandomForestClassifier(random_state=
14)
-
grid = GridSearchCV(clf, parameter_space, cv=
5, scoring=
'%s' % score)
-
#scoring='%s_macro' % score:precision_macro、recall_macro是用于multiclass/multilabel任务的
-
grid.fit(X_train, y_train)
-
-
print(
"Best parameters set found on development set:")
-
print()
-
print(grid.best_params_)
-
print()
-
print(
"Grid scores on development set:")
-
print()
-
means = grid.cv_results_[
'mean_test_score']
-
stds = grid.cv_results_[
'std_test_score']
-
for mean, std, params
in zip(means, stds, grid.cv_results_[
'params']):
-
print(
"%0.3f (+/-%0.03f) for %r"
-
% (mean, std *
2, params))
-
print()
-
print(
"Detailed classification report:")
-
print()
-
print(
"The model is trained on the full development set.")
-
print(
"The scores are computed on the full evaluation set.")
-
print()
-
bclf = grid.best_estimator_
-
bclf.fit(X_train, y_train)
-
y_true = y_test
-
y_pred = bclf.predict(X_test)
-
y_pred_pro = bclf.predict_proba(X_test)
-
y_scores = pd.DataFrame(y_pred_pro, columns=bclf.classes_.tolist())[
1].values
-
print(classification_report(y_true, y_pred))
-
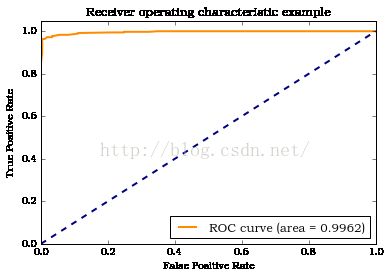
auc_value = roc_auc_score(y_true, y_scores)
输出结果:

-
#绘制ROC曲线
-
fpr, tpr, thresholds = roc_curve(y_true, y_scores, pos_label=
1.0)
-
plt.figure()
-
lw =
2
-
plt.plot(fpr, tpr, color=
'darkorange', linewidth=lw, label=
'ROC curve (area = %0.4f)' % auc_value)
-
plt.plot([
0,
1], [
0,
1], color=
'navy', linewidth=lw, linestyle=
'--')
-
plt.xlim([
0.0,
1.0])
-
plt.ylim([
0.0,
1.05])
-
plt.xlabel(
'False Positive Rate')
-
plt.ylabel(
'True Positive Rate')
-
plt.title(
'Receiver operating characteristic example')
-
plt.legend(loc=
"lower right")
-
plt.show()