总结 of 字节跳动的比赛(Bute Cup2018)——新闻标题生成
目录
0、废话
1、我们的模型介绍
0. 数据预处理
1. Seq2Seq + Attention
2. + pointer network + coverage
3. + temporary attention + policy gradient
4. + dropout
2、出现的问题
1. 分数据集
2. 模型保存
3. 测试时控制变量
3、别人很多值得学习的部分
1. copy + tranformer(All attention)
2. ensemble
3. 优化器用 Adam,学习速率0.0003
4 可以改进的地方
1. 预训练加 bert,或者数据处理用 bert
2. decode 用 AC 架构或者是 GAN
3. MC
4. 逆强化学习
代码已开源:https://github.com/taoyafan/abstractive_summarization,欢迎提意见,求 star 求 star 求 star~
0、废话
废话还是必须要有的,毕竟比赛完了,很多感受,就写在这里吧,这个部分就写自己的感受,然后学到的东西就都在下边,不想看的自行跳过。想想博客已经好久没更新了,GAN 的总结和强化的总结也都没写完。最近这个比赛搞的、太累了,之前对 NLP 的东西完全不了解,看到比赛前十可以免笔试,为了能找个工作,算了,参加吧,从 Seq2Seq 加 attention 开始学。唉,苦逼啊,在最后一个月学成了,终于从100多名提到了13名,然后就再也上不去了,后来准备加强化、tensorflow 也不熟,然后找了别人实现了,后来调试发现各种错误。。最后开放测试集了才调的差不多,将就这用。。。唉各种坑,最终测试集的第一次提交竟然是最好成绩,一直等最后一天截止前才算是还原了第一次提交的成绩。。不说废话了,下面的章节这么分吧,第一章介绍的门的模型,和做过的一些实验。第二章介绍我们出现的很多问题。第三章总结下前几名的方法和技巧。第四章猜一下哪些地方还能改进。
1、我们的模型介绍
0. 数据预处理
官方给了126万篇文章,自己分出了900个测试集出来,不过刚开始没分好,第二章会详细介绍。但是这些文章都有一个很大的问题,就是很多句号后面没有空格,就导致 tokenize 的时候会把一个句号前后两个词包括句号给当成一个词,所以先采用正则,把所有没有空格的句号替换成句号加空格。然后分词使用斯坦福的 Tokenization - Stanford NLP 对文章进行tockenize(最初用的是nltk的分词工具)。最后将分好的文章存成存成 tensorflow 的 example 格式,.bin 的文件,再对文件进行拆分,每个小文件5000个样本。
1. Seq2Seq + Attention
首先 nlp 的大部分任务应该都是以这个作为基本架构的,我们第一个模型是参考 github 中代码 udibr/headlines ,encoder 和 decoder 都采用的是单向的 LSTM,输入三层,输出一层。attention 采用点乘,并为了减少运算量,将 hidden 层前 40 个长度的向量作为 key,后 216 个长度作为 value。论文参考:Generating News Headlines with Recurrent Neural Networks。这个程序使用 GloVe.6B 作为 embedding 层的初始化,参考:stanfordnlp/GloVe。不过最终没有使用这个代码。
2. + pointer network + coverage
如果只是采用 Seq2Seq 的架构,当 encoder 中出现词汇表中未出现过的词后在 decoder 中无法复现,因此需要特殊的结构来复制输入的内容,因此我们采用 pointer network ,根据注意力机制决定复制原文的哪个单词,并通过一个变量来表示输出是生成的单词还是复制的单词,这部分详细可以参考论文 Get To The Point: Summarization with Pointer-Generator Networks,其中 coverage 也是这篇文章提出的内容,可以防止生成重复的内容,但是经过一些测试,发现在生成短题目时,coverage 却起到了反作用,所以最终没有用。这部分代码参考论文作者的 github :https://github.com/abisee/pointer-generator。我们使用这种方法在验证集获得最好成绩为13名。
最终看到还有一个 copy 机制,和 pointer network 不太一样,但是作用和效果类似。
3. + temporary attention + policy gradient
为了再提高结果,参考了一篇论文:A DEEP REINFORCED MODEL FOR ABSTRACTIVE SUMMARIZATION,使用强化学习中的 Policy gradient 来针对评价指标(比如 rouge-l)做针对性的优化,而且还可以解决 exposure bias 的问题,论文同时提出了一些其他的 trick, 如 temporary attention,intra-temporal attention 等,但是后来测试这些效果都不好。所以只加了 policy gradient,这篇论文没有官方开放的源码,有第三方开源的代码,如 pytorch 版的:https://github.com/oceanypt/A-DEEP-REINFORCED-MODEL-FOR-ABSTRACTIVE-SUMMARIZATION,不过这个代码写的说明文档太少,看了下程序基本写完了,对论文的 policy gradient 部分复现基本完成,不过没有测试,但是对我写 tensorflow 的部分代码很有帮助。除了这个还有一个开源的代码写的可以:https://github.com/yaserkl/RLSeq2Seq,说明文档很全面,而且不仅实现了 policy gradient,还实现了 schedule sampling 和强化学习中的 AC 架构。不过经过我的测试和对代码的阅读,发现了 policy gradient 部分大量的错误,完全没有复现论文中的模型,也因此对 policy gradient 做了比较多的修改,最终完全复现了论文中的模型。不过论文中采用 policy gradient 计算的 loss 是:
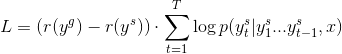
其中 ![]() 是 sample 得到的输出的 reward(rouge-l得分),
是 sample 得到的输出的 reward(rouge-l得分),![]() 是 greedy 得到的输出的 reward,x 是输入 encoder 的内容,对于 greedy 得到的输出,在论文中并没有明确的说输入是上一个单元的输出还是用的 ground truth,但是我觉得为了解决 exposure bias,应该都用的是自己的输出。
是 greedy 得到的输出的 reward,x 是输入 encoder 的内容,对于 greedy 得到的输出,在论文中并没有明确的说输入是上一个单元的输出还是用的 ground truth,但是我觉得为了解决 exposure bias,应该都用的是自己的输出。
但是采用上述公式是根据本次 sample 的好坏来调整本次 sample 得到结果的几率,经过试验,将 baseline(get to the point 中不加 coverage 的模型)切换为使用 policy gradient 的时候,greedy 打的得分快速的下降,在 greedy 和 sample 的得分接近时才会上升。因此我将公式改为了如下的形式:
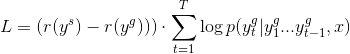
及根据本次 greedy 的好坏来调整本次 greedy 得到结果的几率,这样做在将 baseline 切换至 policy gradient 后 greedy 得到的得分并不会下降太多。
不过最后在比赛前一天才完全调好 policy gradient 的程序,最后效果没体现出来,有点难受。。
4. + dropout
在 RNN 中使用 dropout 可以参考论文:A Theoretically Grounded Application of Dropout in Recurrent Neural Networks,说实话我没怎么看这篇论文的,因为用起来太方便了,不过大家都参考这边论文,我也引用一下吧。其实就是在 LSTM cell 的输入、输出、还有忘记门那里加dropout,用法参考 tensorflow 的官方文档:https://www.tensorflow.org/api_docs/python/tf/nn/rnn_cell/DropoutWrapper,我在实现的时候给 input、output 和 state 设定的一样的值,在 0.9,0.85,0.8,0.7 几个值中分别测试,发现 0.85 时效果最好,不过在使用 policy gradient 的时候发现加了 dropout 想过会变得很差,而且使用强化本来就基本不会过拟合,训练集的得分和测试集的得分基本一样。
不过最后也没来得及加上,又更难受了。。。
2、出现的问题
1. 分数据集
这个我列在了第一个,因为这个问题对我们影响很大。我把数据集分成了训练集和测试集,训练集126W个,测试集刚开始分的太少了,只分了100多个,而且由于中间一些失误,导致测试集和训练集有一部分样本是重复的,所以训练的时候测试集的 loss 持续下降,根本没办法判断收敛和过拟合,只能训练一段时间就上传一次官方的验证集判断好坏,也是因为如此,后来加了 policy gradient 后将数据集重新分开,从头训练,浪费了大量的时间。最后是自己分了 900 个测试集,虽然自己的测试集的得分和官方的还是有一定差距,但是至少趋势基本一样,而且可以明确的判断自己的模型是否收敛了。
2. 模型保存
因为第一次最优的模型没保存好,导致后来一直没有超越第一次的最优模型,所以模型保存很重要很重要。
3. 测试时控制变量
就是高中学的控制变量,不然哪个改进好哪个改进坏真不好讲。。。千万不能我觉得这可以改,那可以改,然后放在一起做实验,然后回头发现实验做了没用,浪费时间。
3、别人很多值得学习的部分
1. copy + tranformer(All attention)
参考谷歌论文 attention is all you need,另外加 copy 机制。Opennmt 有代码。copy 的 attention 和 transformer 的不能分开。
2. ensemble
首先对样本进行分类,比如文章长短、标题跟文章前几句话rouge高的、还有留头留尾去中间的。然后对不同的类别分别训练模型,最终每个模型得到题目和其他的模型题目计算rouge,求和,当做这个模型的最终得分,然后将最终得分最高的结果作为输出结果。最优用了两层的
3. 优化器用 Adam,学习速率0.0003
参考论文 ACL2018 global encoder for abstract summarization。单一个学习速率能提高0.003,baseline 模型是 Opennmt 的 Summarization,pytorch 版。